

LiveBench: Finally a Contamination-Free LLM Benchmark?
LiveBench: Finally a Contamination-Free LLM Benchmark?
The Weekly Salt #24


Reviewed this week
⭐LiveBench: A Challenging, Contamination-Free LLM Benchmark
Direct Preference Knowledge Distillation for Large Language Models
Towards Fast Multilingual LLM Inference: Speculative Decoding and Specialized Drafters
Unlocking Continual Learning Abilities in Language Models
⭐: Papers that I particularly recommend reading.
New code repositories:
I maintain a curated list of AI code repositories here:
⭐LiveBench: A Challenging, Contamination-Free LLM Benchmark
LLM benchmark scores are always difficult to trust due to the lack of transparency regarding potential data contamination. In other words, we don’t know how carefully the evaluators filtered out the benchmark data from the training data. As far as we know, LLMs could have been trained, partially, on the benchmark data. As I show in a previous article, such training on benchmark data is easy and can be done without overfitting a particular benchmark.

This new paper introduces a benchmarking framework designed to avoid test set contamination and the issues associated with LLM judging and human crowdsourcing.
This framework is used to create LiveBench, a benchmark with three key features: (1) frequently updated questions based on recent information sources, (2) automatic scoring using objective ground truth without an LLM judge, and (3) a diverse set of questions from six categories.
The questions included have objectively correct answers, making them suitable for precise evaluation. LiveBench presents challenging questions, with no current model achieving higher than 65% accuracy. Questions will be added and updated monthly, with new and more difficult tasks introduced over time to continuously evaluate the evolving capabilities of LLMs.
LiveBench currently includes 18 tasks across six categories: math, coding, reasoning, language comprehension, instruction following, and data analysis. The tasks fall into two types: those using recent information sources and those that are more challenging.
The evaluation already includes numerous models, both proprietary and open, ranging from 0.5B to 8x22B in size. All questions, code, and model answers are made publicly available, encouraging community engagement and collaboration.
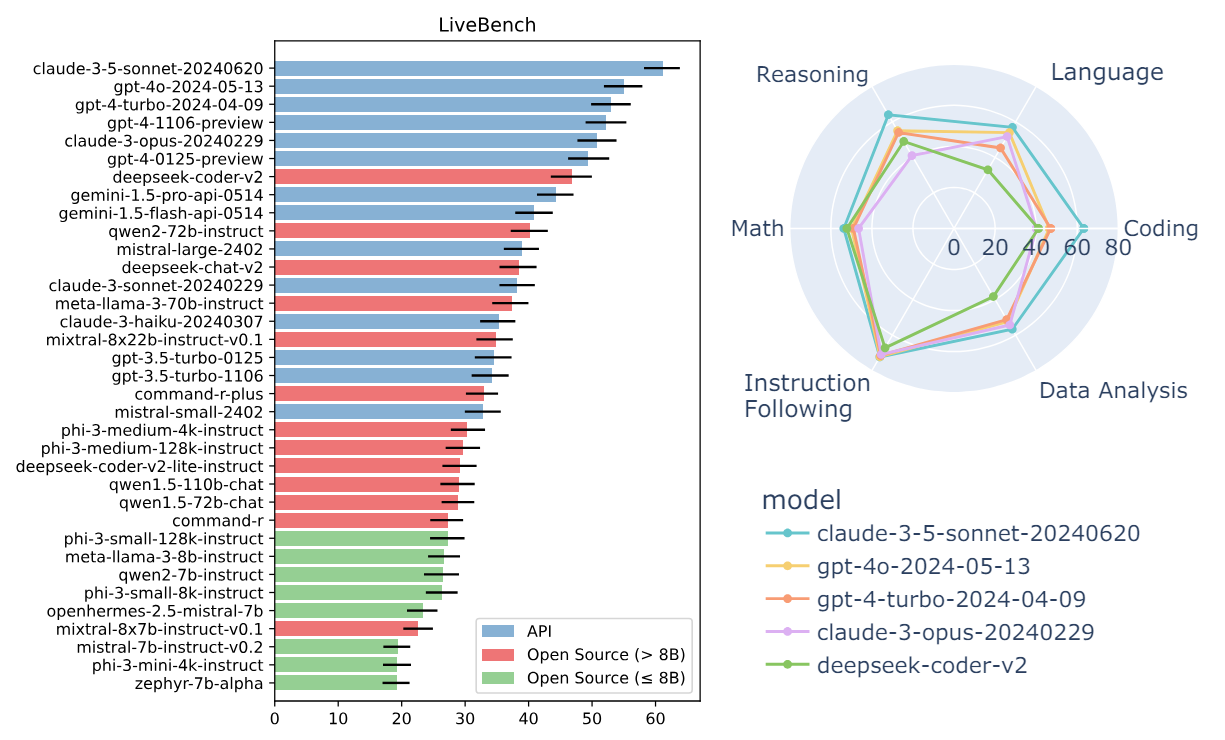
You can see the current ranking here:
Direct Preference Knowledge Distillation for Large Language Models
Recent studies have highlighted the limitations of KL divergence in traditional knowledge distillation (KD) for LLMs.
It has been noted that KL divergence is inadequate when dealing with a very strong teacher model, necessitating additional objectives and innovative KD procedures.
In this work, a new framework called Direct Preference Knowledge Distillation (DPKD) is proposed for the KD of LLMs.
It has been shown that LLMs can function as an implicit reward function. Given the limitations of KL divergence, the implicit reward function is defined as a supplement to the KL distance.
The KD process for white-box LLMs is reformulated to first maximize an optimization function combining implicit reward and reverse KL divergence, and then enhance the preference probability of teacher outputs over student outputs. This approach mitigates the shortcomings of KL divergence while ensuring high training efficiency.
Experiments were conducted on the DPKD method in the context of instruction tuning, using various families of LLMs such as GPT-2 and OPT with parameter sizes ranging from 120M to 13B across multiple datasets.
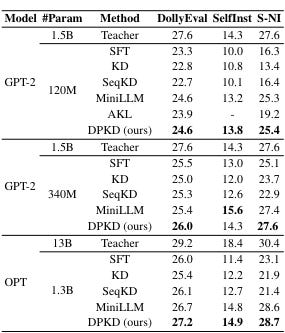
The results show that the DPKD method outperforms baseline methods and shows advantages over a wide range of generation lengths.
The authors released their code here:
GitHub: DPKD
Towards Fast Multilingual LLM Inference: Speculative Decoding and Specialized Drafters
Speculative decoding has recently attracted significant attention, but its application in multilingual contexts remains largely understudied. I explained speculative decoding in this article:

Speculative decoding uses a small LLM (drafter) to generate the tokens which are then validated, or corrected if needed, by a much better and larger LLM. If the small LLM is accurate enough, speculative decoding can dramatically speed up inference.
This paper aims to understand the behavior of drafters in speculative decoding within multilingual tasks and assess their effectiveness. It demonstrates that a pre-train and fine-tune strategy significantly improves the alignment of drafter models, achieving the highest speedup ratio among the baselines.
Additionally, the research finds that the speedup ratio increases with the number of tokens specific to the target task used in training, with this speedup being logarithmically proportional to the scale of token count in drafter training.
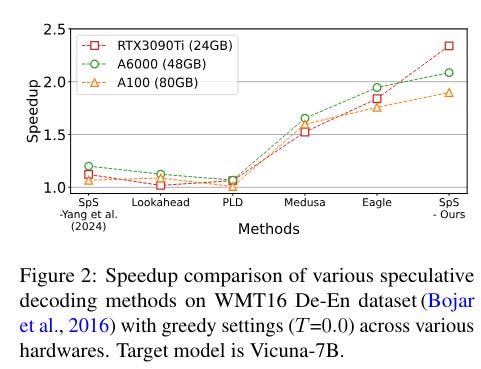
In multilingual translation, input languages consistent with the training set lead to notable speedup, whereas outputs aligned with the training domain do not necessarily improve performance.
Unlocking Continual Learning Abilities in Language Models
The paper introduces a new approach, "MIGU" (Magnitude-based Gradient Updating for continual learning), leveraging magnitude distribution differences for continual learning.
During the forward pass, it caches and normalizes the output of linear layers using the L1-norm. During backward propagation, it updates parameters with the largest values in L1-normalized magnitude, effectively using the model's inherent features to handle task-specific parameter updates and reduce gradient conflicts.
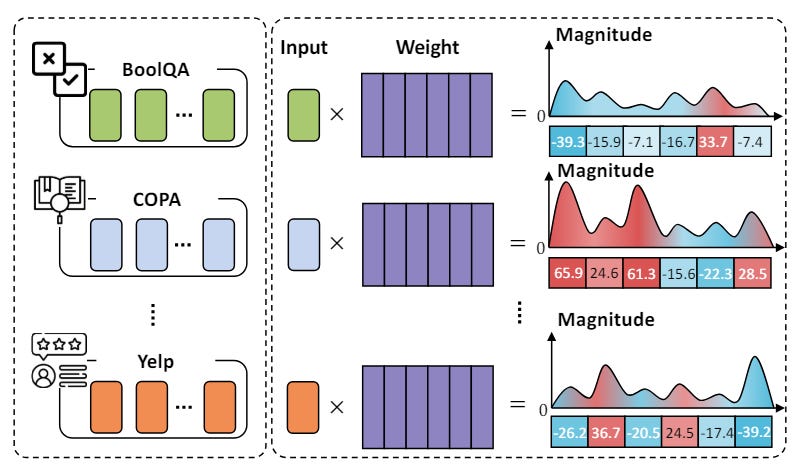
MIGU was evaluated across three main LM architectures: RoBERTa, T5, and Llama 2 under continual pre-training and continual fine-tuning settings using four continual learning datasets.
Experimental results showed that MIGU achieved comparable or superior performance to state-of-the-art methods.
If you have any questions about one of these papers, write them in the comments. I will answer them.