

Prometheus 2 and Simple Methods to Extend the Context Length of LLMs
Prometheus 2 and Simple Methods to Extend the Context Length of LLMs
The Weekly Salt #16

Reviewed this week
⭐Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models
Extending Llama-3's Context Ten-Fold Overnight
Iterative Reasoning Preference Optimization
⭐: Papers that I particularly recommend reading.
New code repositories:
I maintain a curated list of AI code repositories here:
Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models
This work discusses the challenges associated with relying on proprietary LLMs for evaluation, highlighting issues such as lack of transparency in training data which affects the fairness of the evaluation. Additional concerns include controllability and affordability.
To tackle these issues, recent efforts have been directed toward developing open-access, transparent, and controllable evaluator LLMs. Despite these efforts, the open-access models often fail to align their evaluations with human judgment or proprietary models and are limited in flexibility as they are generally trained for specific tasks like direct assessment or pairwise ranking.
To bridge the gap between open and proprietary LLMs, this paper proposes a unified evaluator LLM by merging the training approaches of direct assessment and pairwise ranking. They develop a method that merges the weights of two evaluator LLMs, trained for direct assessment and pairwise ranking, respectively. This approach results in an evaluator LLM that not only operates effectively in both assessment formats but also shows superior performance compared to models trained on a single format or jointly on both.
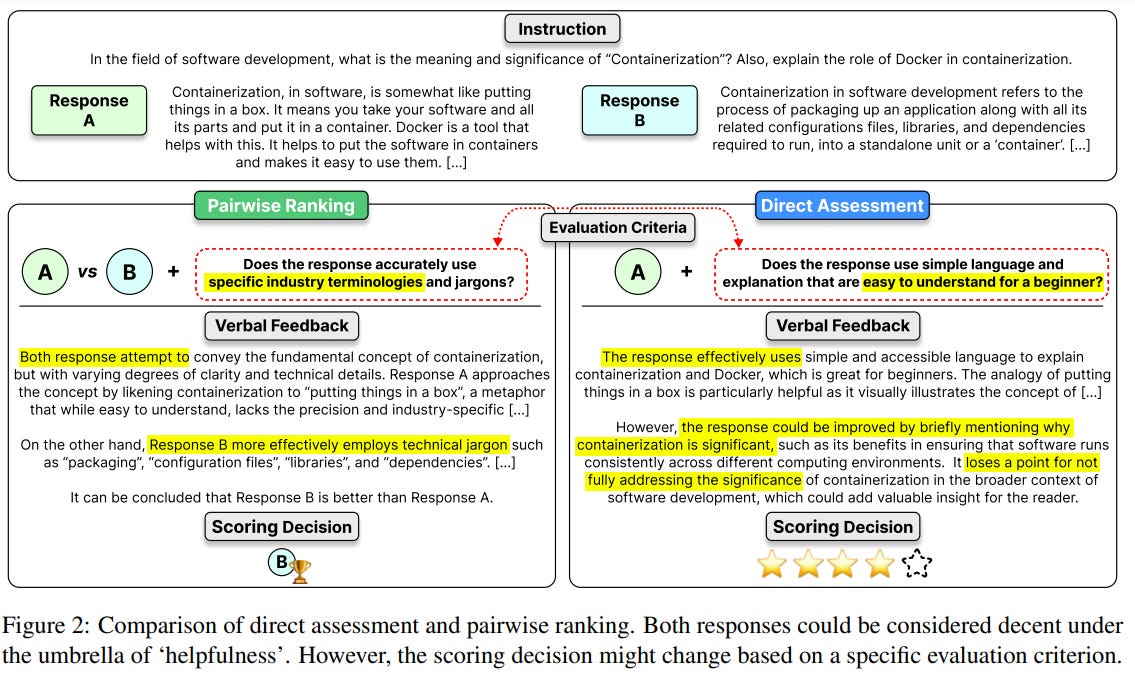
To validate this method, they introduce a new dataset named PREFERENCE COLLECTION, which complements an existing direct assessment dataset called FEEDBACK COLLECTION. Using the base models Mistral-7B and Mixtral-8x7B, the researchers merge the weights from evaluator LLMs trained on these two datasets to create PROMETHEUS 2 (7B & 8x7B).
The PROMETHEUS 2 models are tested across various benchmarks and demonstrate a significantly higher correlation with human evaluators and proprietary models than other open evaluator LLMs. The results indicate a substantial improvement, notably halving the performance gap with proprietary models like GPT-4 in pairwise ranking tasks.
They released their code and data here:
GitHub: prometheus-eval/prometheus-eval
And the Prometheus 2 model is on the HF Hub:
Extending Llama-3's Context Ten-Fold Overnight
In this technical report, the authors present an efficient method to extend the context of LLMs, particularly for Llama-3-8B-Instruct, extending its context length from 8K to 80K tokens.
They used GPT-4 to generate 3.5K instances of long-context training data for three distinct tasks: Single-Detail QA, which focuses on one detail within a large text; Multi-Detail QA, which involves aggregating and reasoning across multiple details from coherent or heterogeneous texts; and Biography Summarization, where biographies for main characters in a book are created.
For each task, the context length ranges between 64K and 80K tokens, and the methodology allows for the creation of even longer data. The training involves organizing question-answer pairs into multi-turn conversations, which are then used to fine-tune the LLM to respond accurately to questions based on the entire long context.
To prevent model forgetting, instances from other datasets like RedPajama and LongAlpaca are mixed into the training set, totaling 20K instances.
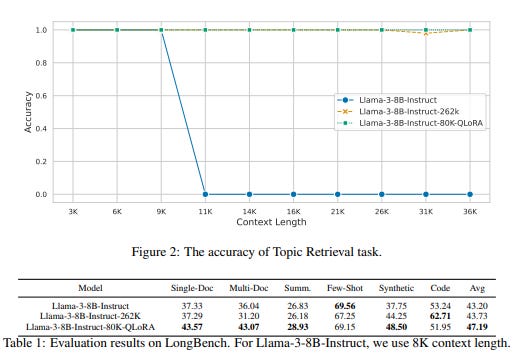
For this fine-tuning, they used QLoRA. They released the code here:
GitHub: Long LLM

Iterative Reasoning Preference Optimization
In their study, the authors propose Iterative Reasoning Preference Optimization (Iterative RPO), which applies iterative preference optimization to improve reasoning capabilities, particularly in Chain-of-Thought (CoT) reasoning.
This process involves sampling multiple reasoning steps and answers across training prompts, creating pairs where the correct answers determine the winners and the incorrect ones the losers. These pairs then train a modified version of DPO that integrates a negative log-likelihood loss for the winners.
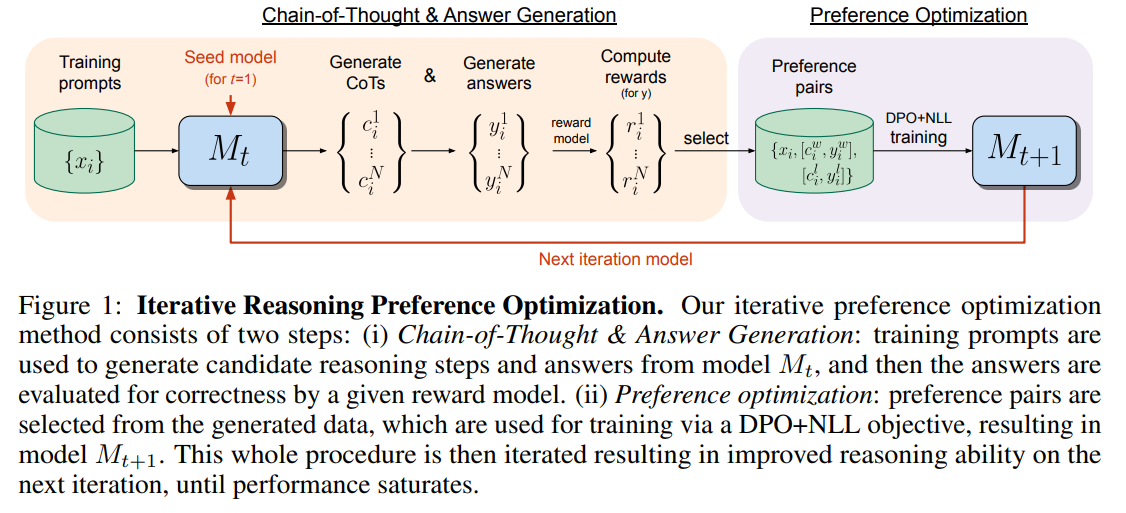
The model is refined through several cycles of generating new pairs and training, leading to improved reasoning performance that eventually reaches a saturation point.
Iterative RPO is shown to surpass DPO and other methods on various benchmarks.
If you have any questions about one of these papers, write them in the comments. I will answer them.