
A Recipe to Convert Existing Models Into Fine-Tuned BitNet
The Weekly Salt #92


This week, we review:
⭐QueST: Incentivizing LLMs to Generate Difficult Problems
BitNet Distillation
LLMs Can Get “Brain Rot”!
⭐QueST: Incentivizing LLMs to Generate Difficult Problems
QueST tackles a familiar bottleneck: we don’t have enough truly hard coding problems to keep training reasoning-heavy models moving. Instead of mining or lightly mutating old tasks, the authors train a generator that’s explicitly rewarded for producing problems that are hard for strong solvers, and then use those problems to teach smaller models.
First, difficulty-aware graph sampling searches over structured templates, so the generator spends time where tough instances are likely. Second, difficulty-aware rejection fine-tuning feeds back a signal that prefers problems that models actually struggle with, pushing the generator toward higher-yield regions of the space. Together, the generator becomes a specialist in hard problem creation rather than a general instruction writer.
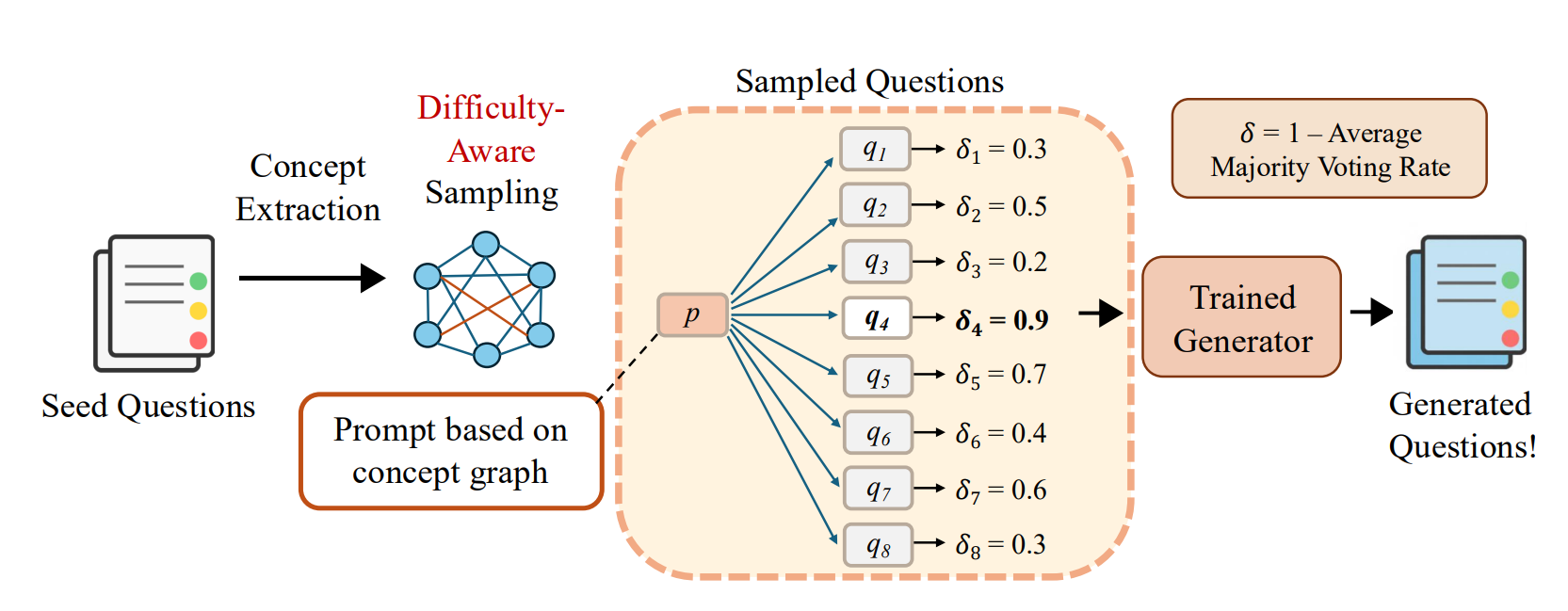
They then put the data to work in two common pipelines. In distillation, QueST problems are paired with long teacher rationales to train smaller students. In reinforcement learning, the same problems drive updates directly toward better reasoning. In both cases, the claim is that QueST’s “hard on purpose” problems produce larger downstream gains than problems sourced from a general model like GPT-4o.
Numbers worth noting: fine-tuning Qwen3-8B-base on 100k QueST problems beats the vanilla model on LiveCodeBench. Adding ~112k more examples, 28k human problems plus multiple synthetic solutions, yields an 8B student that reportedly matches a far larger DeepSeek-R1-671B on the same benchmark.
BitDistill is about turning ready FP16 backbones into ternary 1.58-bit models that keep task accuracy while cutting memory and boosting CPU throughput. I explained BitNet in this article (The Kaitchup):

Direct FP16 to 1.58-bit fine-tunes struggle and the gap widens with scale. BitDistill reframes the path so you do not need to pre-train a BitNet from scratch to get usable downstream models.
First, add SubLN before the MHSA and FFN output projections to stabilize activations where ternary projections are touchy.
Second, run a short continue-pretrain on a small corpus to improve weight distributions toward a BitNet-friendly shape.
Third, fine-tune on the task with two signals at once. Use standard logits distillation and an attention-relation loss from MiniLM, applied to a single late layer rather than all layers. That choice consistently helps the ternary student optimize.
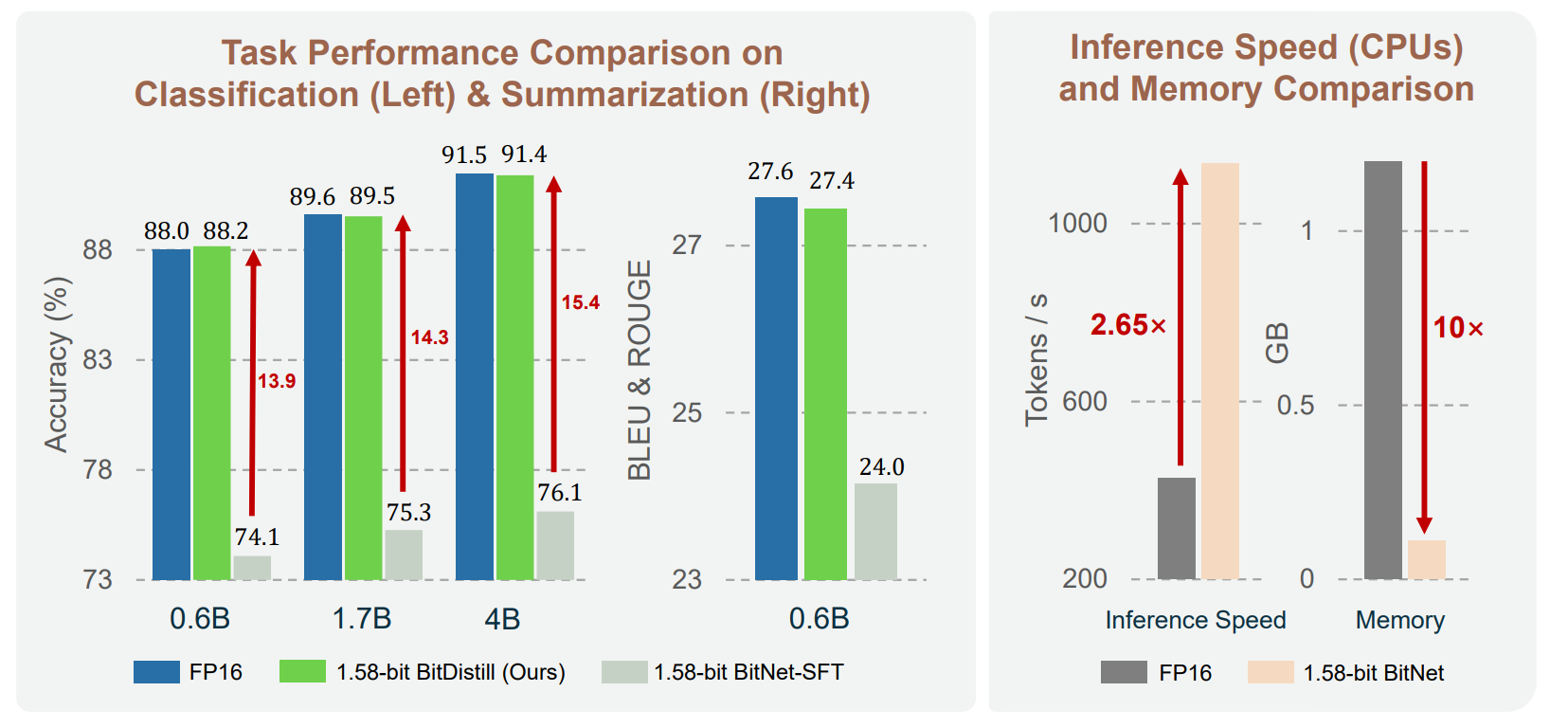
Compared to naive 1.58-bit fine-tuning, BitDistill closes the accuracy gap to FP16 across 0.6B, 1.7B, and 4B settings on classification and summarization while keeping the system wins that make BitNet attractive. On CPU with 16 threads, they report about 2.65x tokens per second and roughly 10x lower memory than FP16.
If you keep pretraining on junk web text, do LLMs get worse in ways that matter?
The authors build two controlled Twitter datasets that isolate what they call junk along two axes.
M1 captures engagement patterns with short and highly popular posts. M2 targets semantic low quality like sensational phrasing (quite common on Twitter/X…). They match token count and training steps against a control set. The result is a causal story rather than a loose correlation. Models continually exposed to the junk sets show lasting drops in reasoning, long context retrieval, and safety.
Chains of thought get truncated or never start. Error forensics on ARC show most failures fall into no thinking, no plan, or skipped steps, rather than subtle logic slips. That makes the decline visible in the transcript and not only in the score. The popularity signal in M1 comes out as the sharper toxin for reasoning, while extreme brevity hits long context tracking. This split matters because it says length and popularity drive different kinds of damage.
As the junk share goes from zero to full, ARC Challenge with chain of thought drops from the high seventies to the high fifties (that’s very low for ARC). RULER long context tasks show similar falls, with multi key retrieval hurt the most.
Mitigation is only partly effective. The team tries reflective prompting and it helps only when a stronger external model supplies the critique. They also scale instruction tuning and a clean continue pretrain. Scores recover a chunk yet never fully return to baseline, even when the post hoc tuning uses far more tokens than the junk exposure. The paper reads this as representational drift rather than a formatting issue. If true, routine “cognitive health checks” during deployment stop being optional.
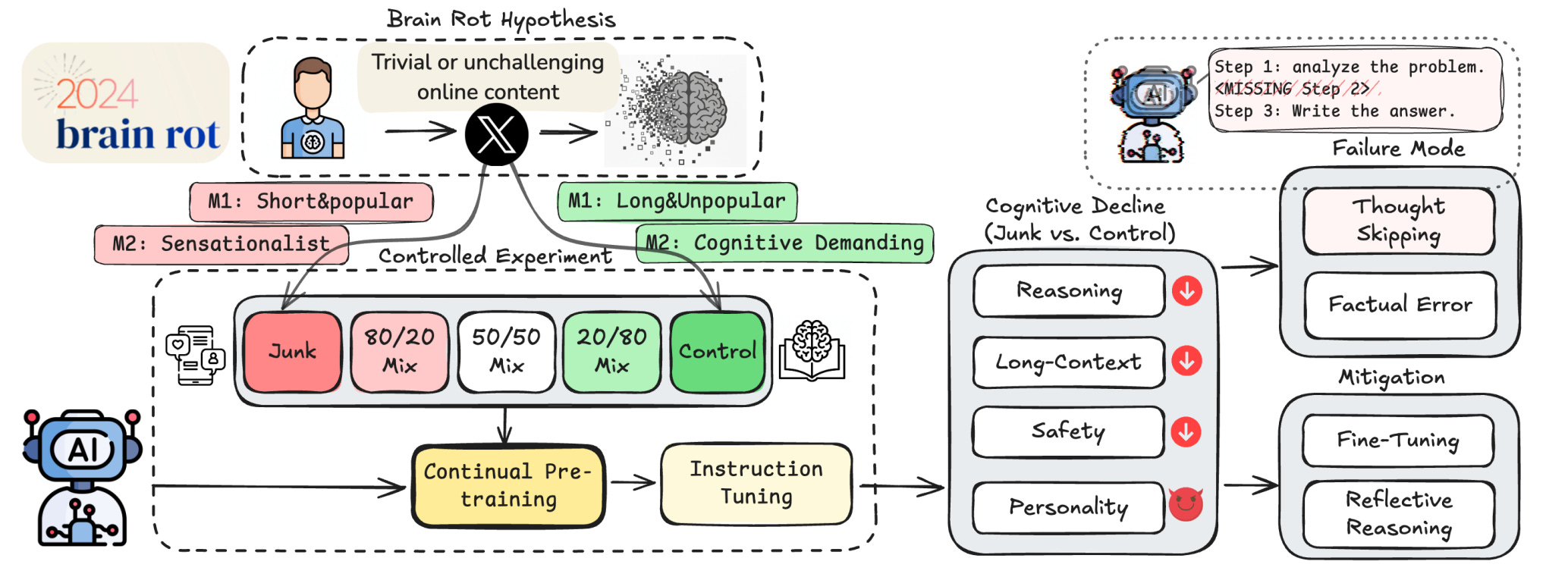
Interestingly, they also found that junk exposure shifts model personality traits. Under M1, the model tilts upward on psychopathy and narcissism while agreeableness drops. The same trend is weaker or mixed for M2. I would not over index on these trait labels, but the direction aligns with the safety results and with the idea that low friction engagement content rewards fast takes over careful reasoning. The safer read is that engagement driven corpora are not neutral. They pull models toward shortcuts that later show up as refusals, jailbreak risk, and sloppy plans.