


A Rectified Softmax and a New Bi-Level Adaptive Reasoning Optimization
The Weekly Salt #67


This week, we read:
⭐AdaR1: From Long-CoT to Hybrid-CoT via Bi-Level Adaptive Reasoning Optimization
Softpick: No Attention Sink, No Massive Activations with Rectified Softmax
ReplaceMe: Network Simplification via Layer Pruning and Linear Transformations
⭐: Papers that I particularly recommend reading.
New code repositories (list of all repositories):
⭐AdaR1: From Long-CoT to Hybrid-CoT via Bi-Level Adaptive Reasoning Optimization
Recent LLMs, like OpenAI's o1, Qwen3, and Deepseek’s R1, have focused on incorporating detailed reasoning processes (Long-CoT). Although this improves problem-solving significantly, it also increases computational costs, latency, and resource consumption, making it less practical for scenarios where speed and efficiency matter.
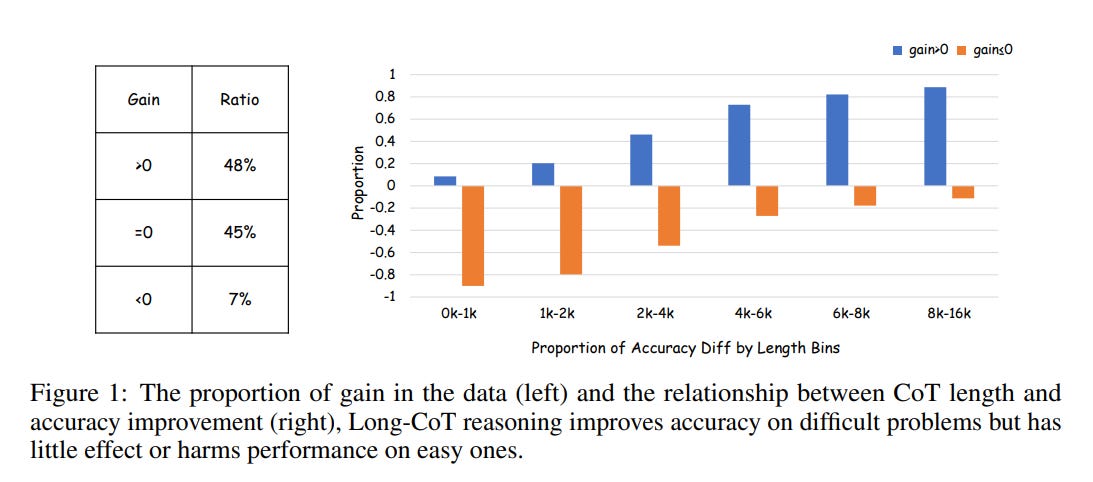
Existing methods typically optimize reasoning within the Long-CoT framework, compressing steps to reduce redundancy, but they don't address the fundamental question: is a long reasoning chain always necessary? Research shows detailed reasoning is beneficial for complex problems but can actually be wasteful or harmful for simpler ones. This insight highlights the value of adaptive reasoning, adjusting complexity based on the task at hand.
Building on this idea, the authors of this paper propose a hybrid reasoning model combining both detailed (Long-CoT) and concise (Short-CoT) strategies. They introduce a two-level training method (AdaR1) that first chooses the appropriate reasoning style based on task complexity and then fine-tunes for correctness and conciseness. Experimental results indicate substantial efficiency improvements, significantly shortening reasoning lengths (by around 58% to 74%) without sacrificing accuracy, even slightly improving it in some cases.
The code will be available here:
GitHub: StarDewXXX/AdaR1
Softpick: No Attention Sink, No Massive Activations with Rectified Softmax
Softmax is the standard function used in transformers to normalize attention scores into probabilities. It's stable, provides smooth gradients, and regularizes attention nicely. But it introduces some weird quirks, like attention sinks, where heads obsessively focus on irrelevant tokens (often the BOS token), and massive hidden-state activations, making low-precision quantization tricky.
To fix these issues, the authors introduce softpick, a relaxed alternative to softmax. Unlike softmax, softpick doesn’t strictly sum to one, so it avoids attention sinks and massive activations altogether. They trained transformer models with softpick, finding performance equal to softmax in standard benchmarks, but notably better when quantized to ultra-low precision (2-bit). Attention maps become clearer, sinks vanish, and hidden states stay stable.

Still, softpick has its own issues: it sometimes produces underscaled scores in long contexts. The authors acknowledge this and suggest possible fixes for future work.
The code is here:
GitHub: zaydzuhri/softpick-attention
ReplaceMe: Network Simplification via Layer Pruning and Linear Transformations
The size of LLMs limits their accessibility and practical deployment, especially in environments with constrained hardware. To address these challenges, the research community has focused on efficiency techniques like quantization, distillation, and pruning. Among these, structured pruning, which removes entire groups of parameters (e.g., layers or blocks), stands out for its ability to reduce resource demands while maintaining compatibility with standard hardware and preserving model structure.
This work introduces ReplaceMe, a novel training-free structured depth pruning method. It is based on the insight that a sequence of transformer blocks can be effectively approximated by a single linear transformation. ReplaceMe estimates this transformation using a small calibration dataset, allowing it to remove blocks and replace them with a compact operation, without requiring any retraining or "healing" phase, which is typically needed in pruning pipelines to recover lost performance. The linear replacement is then fused into existing model weights, making it easy to integrate without adding extra parameters or altering inference flow.

The paper provides a thorough exploration of how to estimate these linear transformations analytically and numerically, including experiments on different loss functions, solvers, and model families. ReplaceMe is shown to work across both language and vision transformers (e.g., ViT), but the accuracy in benchmarks is significantly degraded while the perplexity increases at levels where the model is often broken. The results are nonetheless very interesting. I’ll definitely try to reproduce their methods with more recent models like Qwen3.
GitHub: mts-ai/ReplaceMe