


Accurate LLM Training with FP4 Quantization, Coming Soon?
The Weekly Salt #54


This week, we read about optimizing LLM efficiency:
⭐Optimizing Large Language Model Training Using FP4 Quantization
Low-Rank Adapters Meet Neural Architecture Search for LLM Compression
Parameters vs FLOPs: Scaling Laws for Optimal Sparsity for Mixture-of-Experts Language Models
⭐: Papers that I particularly recommend reading.
New code repositories (list of all repositories):
⭐Optimizing Large Language Model Training Using FP4 Quantization
LLMs are trained using FP32 (full precision) or FP16/BF16 (half precision) formats. Quantization techniques allow these to be reduced to 8-bit or even 4-bit representations, significantly improving memory efficiency. Recent advancements in hardware, such as NVIDIA's H100 and B200 GPUs, have introduced support for low-bit arithmetic operations.
The Hopper-series GPUs feature FP8 tensor cores, with a 2x speed-up over FP16 cores, while the Blackwell-series GPUs extend this capability with FP6 and FP4 support. Theoretically, FP4 can double computational throughput compared to FP8, making it an attractive option for training efficiency. However, applying FP4 directly to model training has proven difficult due to accuracy loss caused by the limited numerical range, leading to instability and performance degradation.
This paper by Microsoft introduces an FP4-based training framework that addresses these challenges and validates the feasibility of ultra-low precision training. The authors propose two key optimization techniques to minimize accuracy loss:
Differentiable Quantization Estimator for Weights
Directly quantizing model weights to FP4 can significantly impact gradient updates during training, leading to poor learning.
To solve this, the study introduces a differentiable quantization estimator that corrects for the loss of precision by incorporating adjustment terms into the gradient calculation.
This method helps maintain stable training dynamics and preserves model accuracy even at ultra-low precision.
Outlier Clamping and Compensation for Activations
LLMs often produce activation values that are highly skewed, with a few extreme outliers that dominate the computation.
Traditional quantization struggles with these outliers, leading to further accuracy degradation.
The study proposes an outlier clamping mechanism that restricts extreme activation values while preserving useful information.
A sparse auxiliary matrix is also introduced to store critical information lost during quantization, compensating for accuracy loss.

To evaluate their method, the authors conducted experiments on LLMs with up to 13 billion parameters and 100 billion training tokens. They used NVIDIA H100 GPUs to emulate FP4 computations and compared results against BF16 and FP8 models. Their findings showed that models trained with FP4 achieved accuracy levels close to BF16 and FP8, with only a minor gap in training loss.
They plan to open-source the training framework.
Low-Rank Adapters Meet Neural Architecture Search for LLM Compression
Low-rank adaptation (LoRA), a parameter-efficient fine-tuning (PEFT) technique, attaches small low-rank adapters to a model’s linear layers. Instead of updating all model parameters, LoRA fine-tunes only these adapters, significantly reducing computational costs while maintaining strong performance.
Meanwhile, Neural Architecture Search (NAS) is a method used to discover optimal AI model structures. Traditional NAS techniques have struggled to keep up with the growth of large-scale models because evaluating billions of potential architectures is computationally expensive. However, an efficient approach known as weight-sharing NAS improves efficiency by activating different substructures of a neural network during training, allowing smaller networks to share weights with their larger counterparts.
This study highlights the synergies between LoRA and NAS, showing how they can enhance each other. First, NAS techniques can optimize low-rank adapters, dynamically adjusting them for different tasks. Conversely, low-rank representations can improve NAS by reducing search space complexity, making architecture exploration more efficient.
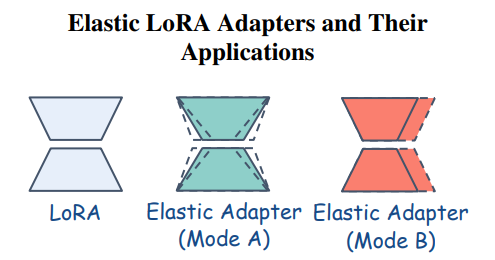
To leverage these advantages, the study introduces the Elastic LoRA Adapter, which allows LoRA configurations to be adjusted dynamically. This adapter operates in two modes:
Mode A: Allows the rank of LoRA matrices to be flexible, adapting to different computational constraints.
Mode B: Extends elasticity further by enabling input and output channel widths to change dynamically.
By combining LoRA with weight-sharing NAS techniques, models can achieve greater adaptability, improved compression, and more efficient fine-tuning.
The authors released their code in this repository:
Parameters vs FLOPs: Scaling Laws for Optimal Sparsity for Mixture-of-Experts Language Models
Empirical scaling laws for language model pretraining have shown that increasing model capacity, data, and compute budget leads to lower perplexity and better performance on downstream tasks. Model capacity has been measured by the total number of parameters, but another critical factor is compute per example, measured in FLOPs (floating point operations). While increasing parameters generally improves performance, different architectures, such as Sparse Mixture-of-Experts (MoE) models, allow for independent control over parameters and FLOPs.
This paper explores the trade-off between total parameters and FLOPs per example in MoE models, which activate only a subset of expert modules per input. By analyzing various sparsity levels (the ratio of inactive experts to total experts), model sizes, and compute budgets, the research identifies optimal configurations for different training and inference settings.
Key findings include:
During pretraining, adding more parameters is more beneficial than increasing FLOPs per example. Compute-optimal models tend to grow larger with higher training budgets, while the number of active parameters per example decreases.
During inference, FLOPs per example become more critical. Models with the same pretraining perplexity but higher sparsity perform worse on tasks requiring more reasoning, despite being more efficient overall.