
Are Current Quantization Methods Accurate for Reasoning Models?
The Weekly Salt #63


This week, we read:
⭐SmolVLM: Redefining small and efficient multimodal models
Quantization Hurts Reasoning? An Empirical Study on Quantized Reasoning Models
Multi-Token Attention
⭐: Papers that I particularly recommend reading.
New code repositories (list of all repositories):
⭐SmolVLM: Redefining small and efficient multimodal models
Recent progress in Vision-Language Models (VLMs) has mostly relied on scaling—large models with high parameter counts and compute needs. Even smaller variants, like Qwen2-VL or InternVL 2.5, tend to follow similar architectures, which keep their memory and resource requirements relatively high. These constraints limit their usability in settings like mobile or edge devices. This is less the case for Qwen2.5-VL, which is more optimized.

Hugging Face’s SmolVLM focuses on efficient architecture design to reduce resource usage. The design process involved systematic testing of neural components: varying the balance between vision encoder and language model sizes, comparing tokenization methods, experimenting with positional encoding strategies, and increasing context lengths up to 16k tokens. For vision processing, they analyzed the impact of pixel shuffle factors and frame averaging on video tasks, noting that excessive averaging reduces performance, while smaller shuffle values can help maintain efficiency.
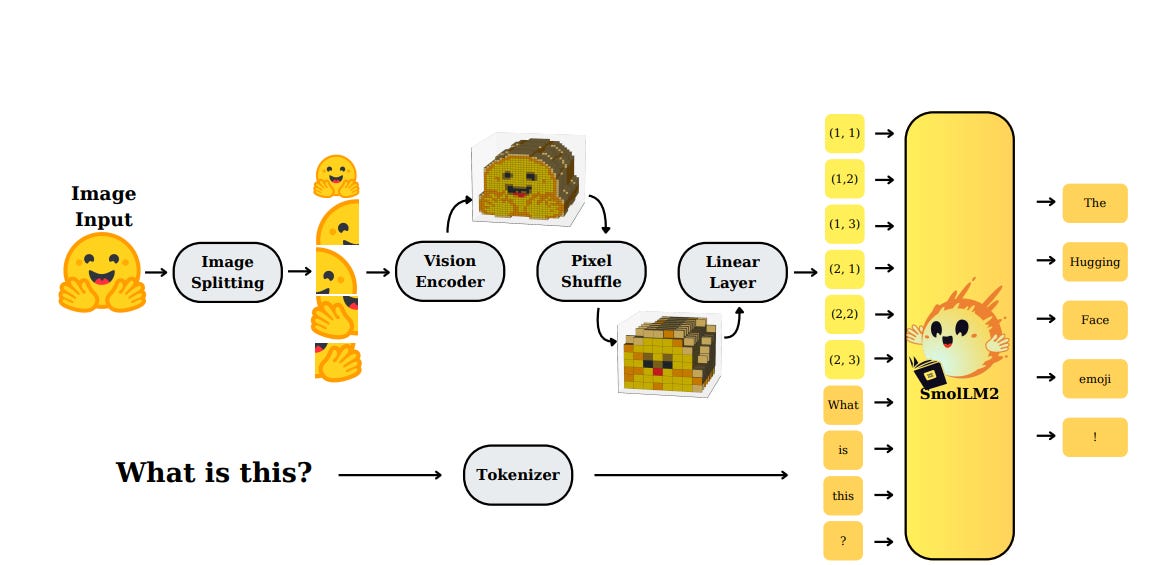
The smallest SmolVLM model runs inference with under 1GB of GPU memory. Evaluation shows it performs reliably on benchmarks like Video-MME, with solid results in tasks like captioning (CIDEr) and visual question answering. LLMs benefit more from higher-capacity vision encoders, while smaller ones show less gain, suggesting different scaling strategies depending on model size.
The models:
Code:
GitHub: huggingface/smollm
Quantization Hurts Reasoning? An Empirical Study on Quantized Reasoning Models
Recent LLMs trained for complex reasoning tasks, like math competitions and multi-disciplinary QA, perform well but tend to generate long, detailed outputs, even for simple problems. This increases inference costs and can make them inefficient in practice.
To address this, the authors of this paper have explored compression techniques like quantization, pruning, and distillation. However, most quantization methods were designed and evaluated for standard LLMs, not those optimized for reasoning, where longer chain-of-thought outputs can amplify errors introduced by quantization. Note: I think this is not only about how long the chain of thoughts is, but also about how large the activations are. Like for the chat template of standard instruct LLMs, the special tokens of the “thinking” part of the models may yield large activations that are very difficult to quantize and may break the model.
This study evaluates several quantization strategies—weight-only, weight-activation, and KV cache quantization—on reasoning-focused models ranging from 1.5B to 70B parameters. Benchmarks include AIME-120, MATH-500, GSM8K, GPQA-Diamond, and LiveCodeBench. The results show that 8-bit weight-activation quantization works well across tasks and sizes, with minimal accuracy loss. More aggressive methods, like 4-bit quantization, can still perform reasonably well but with greater risk, especially on harder tasks.

The study also finds that certain algorithms perform better for specific types of quantization (e.g., AWQ for weight-only, as usual), and that models trained via distillation are more robust to quantization than those trained with reinforcement learning. Larger models tend to handle quantization better and maintain stronger performance per latency cost compared to smaller ones, although very low-bit quantization can increase output length in smaller models.
They will release their code here:
Standard attention in LLMs relies on computing similarity between individual query and key tokens to decide where to focus, which works well for simple lookups. However, this setup struggles when the task requires understanding relationships between multiple tokens. Since attention weights depend on single query-key pairs, the model can't easily capture multi-token dependencies without using deeper layers and more model capacity.
To overcome this limitation, the authors introduce Multi-Token Attention (MTA), a modified attention mechanism that allows attention scores to depend on groups of tokens and heads. MTA introduces lightweight convolution operations over the attention weights, applied across keys, queries, and attention heads, which lets the model incorporate information from neighboring tokens and jointly reason over multiple relevant inputs. This enables more precise attention in contexts where relevant information is distributed across tokens.
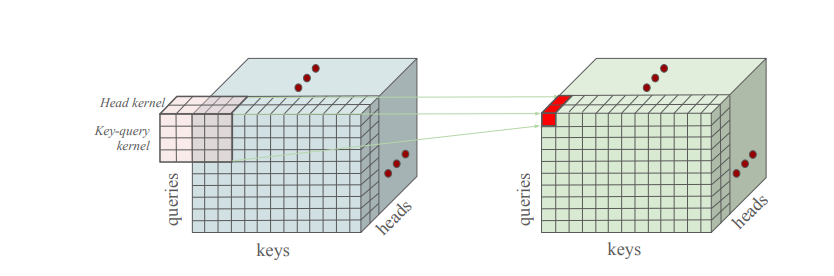
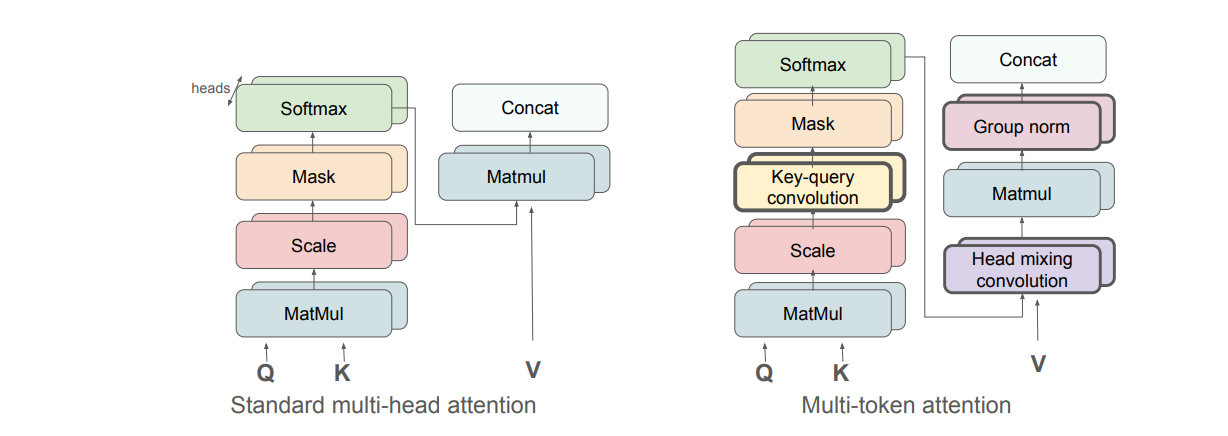
The paper demonstrates that MTA solves synthetic tasks that expose standard attention’s limitations. It also scales effectively: models with MTA (880M parameters, trained on 105B tokens) show improved validation perplexity and better performance on benchmarks, including long-context tasks like Needle-in-the-Haystack and BabiLong. These improvements come with almost no increase in model size.