
Asynchronous Local-SGD and Self-Rewarding LLMs
The Weekly Salt #1


In The Weekly Salt, I review and analyze in plain English interesting AI papers published last week.
Reviewed this week
⭐Machine Translation Models are Zero-Shot Detectors of Translation Direction
Mind Your Format: Towards Consistent Evaluation of In-Context Learning Improvements
⭐Asynchronous Local-SGD Training for Language Modeling
Mission: Impossible Language Models
⭐Self-Rewarding Language Models
⭐: Papers that I particularly recommend reading.
New code repositories
⭐Asynchronous Local-SGD Training for Language Modeling
For configurations using multiple devices, such as multiple GPUs, local Stochastic Gradient Descent (Local-SGD) provides optimization methods to alleviate communication bottlenecks. Devices execute multiple local gradient steps before syncing parameter updates with a central server, reducing communication frequency. However, in this situation, faster devices wait for slower ones, undermining system efficiency.
Asynchronous Local-SGD enables the server to update the model as soon as worker updates are available, boosting computational utilization, and slashing communication bandwidth needs.
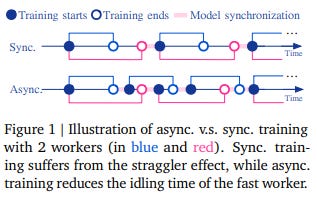
This study by Google DeepMind delves into asynchronously training Large Language Models (LLMs) using Local-SGD, building on prior attempts to tweak synchronous Local-SGD.
This work empirically probes existing optimization strategies and proposes two new techniques: Delayed Nesterov momentum update (DN) and Dynamic Local Updates (DyLU). Evaluated on training LLMs, these techniques bring asynchronous Local-SGD closer to synchronous Local-SGD in perplexity versus local updates.

⭐Machine Translation Models are Zero-Shot Detectors of Translation Direction
It is well-known in the machine translation community that both human and machine-generated translations share "translationese" properties like normalization, and simplification, along with a lack of lexical diversity. In other words, a text that is a translation from another language is usually more simple than a text that is not a translation. LLMs can detect the difference between both. Note: I worked on this topic for a long time and notably published this paper at the ACL 2020 (not cited by the authors :( ).
This new study explores unsupervised translation direction detection based on neural machine translation (NMT) probabilities. It’s very simple.

The authors believe their detection method applies to both types of translations, human and machine-generated.
To verify this assumption, the study uses three multilingual machine translation (MMT) systems to generate translation probabilities, testing across 20 translation directions with varying resource availability. Results indicate the approach is effective, achieving 66% accuracy for detecting human translations on average at the sentence level and 80% for documents with ≥ 10 sentences. Neural machine translation’s outputs exhibit even higher detection accuracy, but the proposed hypothesis is not valid for older non-neural machine translation systems (e.g., statistical machine translation systems).
Here are their results for detecting human translations:

The authors released code here and even propose to try their method via a Hugging Face Space.
Mind Your Format: Towards Consistent Evaluation of In-Context Learning Improvements
We know that prompt templates for few-shot learning influence the evaluation of a model's performance.
Here is an example of the impact on a metric score:

This study assesses template sensitivity in 19 models.
Importantly, there are no universally optimal templates for a task. The best-performing demonstration format does not consistently transfer across models, demonstration sets, or prediction methods. This inconsistency raises concerns, making template tuning challenging, as even the best template can yield poor results after slight changes.
To address template sensitivity practically, this study proposes Template Ensembles—a test-time augmentation method that averages model predictions over multiple task templates. This approach, easy to implement, boosts average performance across templates for various prompting methods, reducing sensitivity to template choice. But it’s also very costly. It’s already expensive to run standard benchmarks on consumer hardware so testing even more prompts may be impossible for many LLM practitioners.
In summary, the contributions include a comprehensive evaluation of prompt template sensitivity, revealing gains comparable to in-context learning improvements that can result from proper template selection. The study highlights the dependence of the best template on various factors and proposes Template Ensembles as a baseline solution for enhancing template robustness in in-context learning.
Note: The paper mentions a repository where we can get the code but it currently returns a 404 error.
Mission: Impossible Language Models
In this study, experimental evidence is provided to show that LLMs possess the capability to learn both possible and impossible languages in a manner analogous to human language learning.
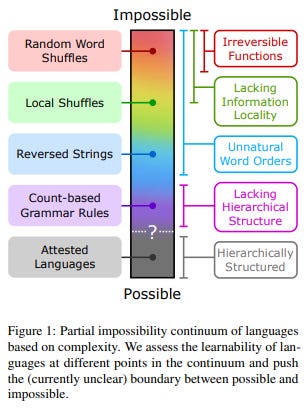
The paper presents examples of impossible languages ranging from intuitively impossible cases, such as random sentence-level shuffling of English words, to less obvious claims in linguistics literature involving rules dependent on word counting.
The experiments presented in the paper aim to either support or challenge the following hypotheses: if LLMs learn impossible languages as efficiently as natural languages, it would substantiate claims made by Chomsky and others that LLMs “are incapable of distinguishing the possible from the impossible”; conversely, if they encounter difficulties, it would cast doubt on those assertions.
Utilizing GPT-2 small models and the BabyLM dataset, the training corpus is modified to implement impossible languages. The experiments reveal that these models encounter challenges in learning impossible languages. Models trained on possible languages exhibit higher learning efficiency, achieving lower perplexities in fewer training steps.
Overall, the experimental results strongly challenge the claims made by Chomsky and others, prompting further discussions on LLMs as models of language learning and the distinction between possible and impossible human languages.
⭐Self-Rewarding Language Models
In this research, the suggested method, Self-Rewarding Language Models, involves training a self-improving reward model that continually updates during the alignment process, avoiding the limitations posed by a static model. Unlike conventional methods that separate reward and language models, such as reinforcement learning with human feedback (RLHF), this approach combines them into a unified agent with all desired abilities.

This agent acts as an instruction-following model, generating responses for prompts, and can generate and evaluate new instruction-following examples to augment their own training set. The training process involves an Iterative DPO framework, which doesn’t need a separate reward model, starting from a seed model and iteratively refining through self-instruction creation, reward assignment, and model training.

Experiments conducted with Llama 2 70B as a seed model demonstrate that the instruction-following performance improves significantly during Self-Rewarding LLM alignment. Notably, the reward modeling ability, no longer fixed, also exhibits improvement. This implies that the model, during iterative training, can provide a higher-quality preference dataset to itself at each iteration. While this effect may reach saturation in real-world scenarios, it raises the possibility of obtaining superior reward models (and consequently LLMs) compared to those only trained from the original human-authored seed data.
As for the results, Meta AI shows that Llama 2 70B becomes better than GPT-4 (0613), Claude 2, and Gemini Pro after 3 iterations of self-rewarding improvements:

Yet, I recommend taking these results with a pinch of salt. AlpacaEval 2.0 uses GPT-4 to evaluate LLMs, including GPT-4. To me, this evaluation benchmark creates a strong evaluation bias that we may not find in other evaluation benchmarks. I would really like to see this paper reproduced and evaluated on a more standard benchmark such as the Evaluation Harness.

Other interesting papers this week
If you have any questions about one of these papers, feel free to write them in the comments. I will try to answer them.