


Better Mixture of Experts with a Layerwise Recurrent Router
The Weekly Salt #31


Reviewed this week:
FuseChat: Knowledge Fusion of Chat Models
⭐Heavy Labels Out! Dataset Distillation with Label Space Lightening
Layerwise Recurrent Router for Mixture-of-Experts
⭐: Papers that I particularly recommend reading.
New code repositories:
I maintain a curated list of AI code repositories here:
FuseChat: Knowledge Fusion of Chat Models
In this study, the researchers present a framework called FUSECHAT, designed to extend the fusion of LLMs to chat-based LLMs with diverse architectures and scales.
This is a two-step process. First, they perform pairwise knowledge fusion between source chat LLMs to create multiple target LLMs of the same structure and size. This involves selecting a pivot LLM, aligning tokens, and fusing knowledge between the pivot and other LLMs, allowing the target models to inherit the strengths of the source models.
In the second stage, the target LLMs are merged using a new method called SCE, which determines merging coefficients based on parameter updates during fine-tuning.

To demonstrate FUSECHAT's effectiveness, the researchers implemented a model called FuseChat-7B using six open-source chat LLMs.
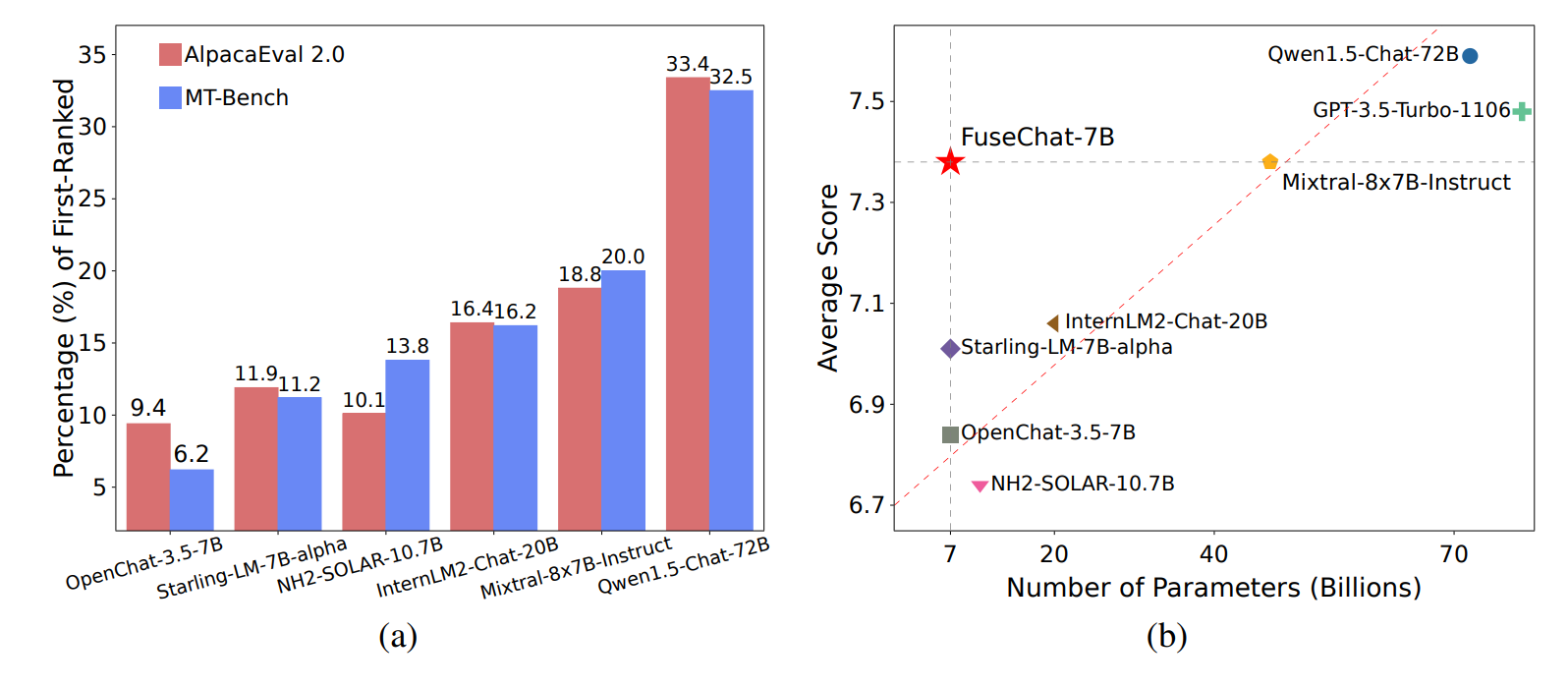
The authors released their code here:
GitHub: fanqiwan/FuseAI
⭐Heavy Labels Out! Dataset Distillation with Label Space Lightening
With dataset distillation, the goal is to condense a large image dataset into a much smaller synthetic version that retains the original training performance for fine-tuning models.
However, achieving a high compression ratio makes it difficult for the distilled dataset to fully capture the knowledge of the original, leading to a performance gap, especially with large datasets.
Recent advancements in dataset distillation have incorporated data augmentation techniques to enhance the performance of distilled datasets. Despite these improvements, these methods rely heavily on soft labels generated by a pre-trained teacher model. This reliance on soft labels creates a significant storage burden, as the number of soft labels far exceeds the number of synthetic samples, making storage costs substantial, particularly for large-scale datasets.
To address the issue of excessive label storage, this work proposes the Heavy Labels Out (HeLlO) framework that introduces a label-lightening approach. HeLlO uses a lightweight projector, based on models like CLIP, to significantly reduce the required storage for soft labels. This approach leverages CLIP’s pre-trained vision-language alignment capability and employs a LoRA-like knowledge transfer method to adapt CLIP's feature space to the target dataset. The projector is initialized with textual representations of label categories to improve training and convergence. Additionally, an image optimization method is introduced to minimize errors between the original and distilled label generators.

Note: This is a very interesting work. I wasn’t aware of data distillation techniques for image datasets. The paper is a little difficult to read if you don’t have much background in image processing but I recommend it.
Layerwise Recurrent Router for Mixture-of-Experts
Current pre-trained Mixture-of-Experts (MoE) models, despite their large size, often fall short in parameter efficiency compared to standard models of equivalent size.

Studies have shown that even with the same training data, MoE models with billions of parameters often perform similarly to much smaller standard models. For instance, an MoE model with 52 billion parameters and only 1.3 billion activated per token performs comparably to a standard model with 6.7 billion parameters (if trained on the same data). Efforts to convert standard models into MoE counterparts, such as transforming a T5-base model into a larger MoE version, yield some improvements but still lag behind slightly larger standard models.
A key challenge in MoE models may lie in the router, a lightweight linear layer responsible for assigning tokens to experts. This component's limited capacity may prevent optimal token-expert combinations. Research has found that routers can quickly converge to suboptimal routing patterns during early training phases, limiting the effectiveness of the model. Alternative routing strategies, such as hash functions or stochastic policies, have shown competitive performance, suggesting the need for further improvements in learnable routers.
Although some enhancements have been made to routers, they typically operate independently across layers, leading to potential inefficiencies. Each layer's routing decisions are based only on local information, which may not fully use the model's parameters. While traditional MoE models could theoretically share routing information through hidden states, this information often gets overshadowed by other factors during training.
To address these issues, the authors introduce a new architecture called Recurrent Router for Mixture-of-Experts (RMoE). This design is a Gated Recurrent Unit (GRU) to capture and pass routing information across layers, allowing for better cross-layer collaboration. The GRU's role in RMoE is specifically focused on routing, helping to separate this task from model prediction.

RMoE has been validated across various model sizes, architectures, datasets, and training settings, consistently outperforming existing baselines.
The authors published their code:
GitHub: qiuzh20/RMoE
If you have any questions about one of these papers, write them in the comments. I will answer them.