


Better MoE Compression and Understanding of Massive Activations
The Weekly Salt #81


This week, we review:
⭐Is Chain-of-Thought Reasoning of LLMs a Mirage? A Data Distribution Lens
Hidden Dynamics of Massive Activations in Transformer Training
MoBE: Mixture-of-Basis-Experts for Compressing MoE-based LLMs
⭐Is Chain-of-Thought Reasoning of LLMs a Mirage? A Data Distribution Lens
The paper challenges the belief that Chain-of-Thought (CoT) prompting gives LLMs real reasoning skills. CoT, often triggered by a cue like “Let’s think step by step,” is known to improve results on tasks involving logic, math, and common sense.
The authors of this paper argue that these improvements mostly come from the model reproducing familiar patterns learned during training, not from genuine logical inference. As a result, CoT works well when the test questions are similar to training data, but starts to fail when the questions change even slightly.
They describe this through a data distribution lens, which frames CoT as a process that relies heavily on the model’s exposure to similar examples during training. When a test question is “in distribution,” CoT outputs can seem coherent and correct. But when the input is “out of distribution,” performance drops sharply. The authors focus on three kinds of distribution changes: introducing new types of tasks, changing the length of reasoning chains, and altering the format or phrasing of the question.
To separate these effects from the complexity of large-scale pretraining, the authors built DataAlchemy, a controlled experimental setup where they train LLMs entirely from scratch. This allows them to precisely measure how CoT handles different types of distribution shifts without interference from unrelated pretraining patterns. Their experiments show that CoT can produce fluent, step-by-step answers that sound convincing but still contain logical contradictions, especially under even modest shifts from the training data.
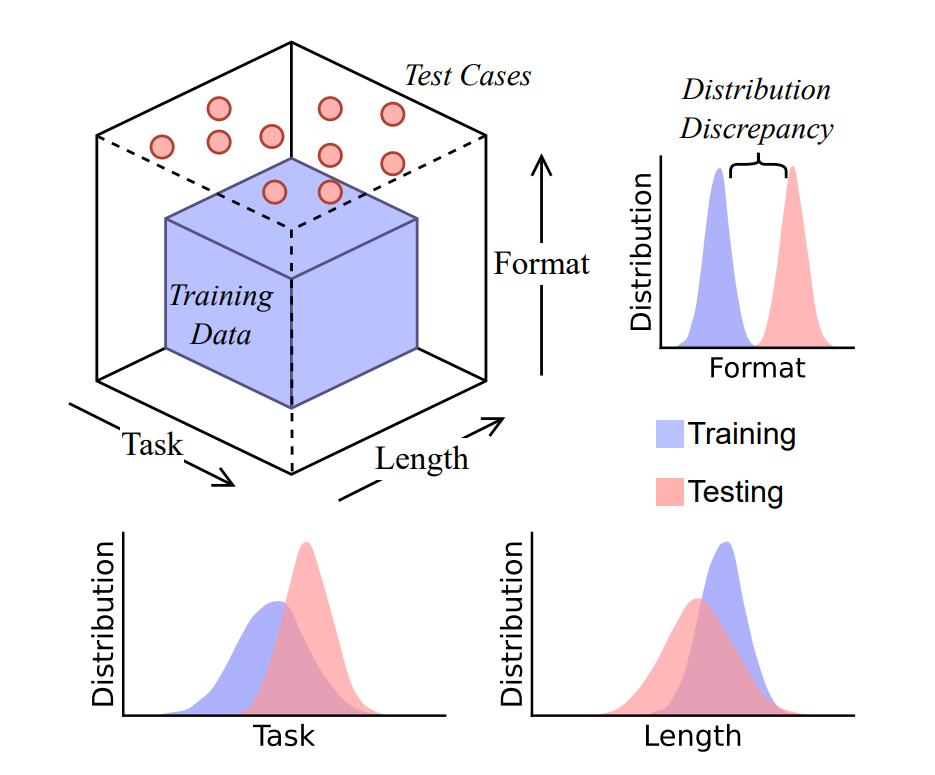
The conclusion is that current CoT performance is better explained as pattern replication rather than true reasoning. While CoT can be effective in cases that closely match training data, it is fragile and unreliable when generalization is required. For practitioners, this means CoT should not be treated as a universal solution for reasoning tasks. For researchers, it underscores the need for new approaches and architectures that can perform reasoning in a way that is both logically correct and robust to distribution changes.
Hidden Dynamics of Massive Activations in Transformer Training
This paper focuses on massive activations (MAs) in decoder-only transformer language models, i.e., neuron activations whose magnitude can be thousands of times larger than the median within a layer.
Unlike ordinary activations, these extreme values are largely constant across inputs and act like implicit bias terms that steer attention toward specific tokens. While removing them can break a model, simply replacing them with their mean can preserve functionality, and boosting certain high-impact MAs has even been shown to enhance Chain-of-Thought reasoning. Despite their importance for quantization, inference efficiency, and training stability, their emergence during training is poorly understood.
The authors review a wide range of mitigation strategies.
Most current techniques are reactive. They suppress MAs after they appear rather than preventing or predicting them. However, the authors argue that understanding MA dynamics is central to explaining representation formation, information flow, and implicit biases in deep networks. A predictive model for MAs could improve training diagnostics, guide architecture design for quantization, and support more principled regularization and interpretability methods. A major gap is the lack of temporal analysis: most prior work examines only final model checkpoints, leaving open questions about when MAs first emerge and how they evolve.
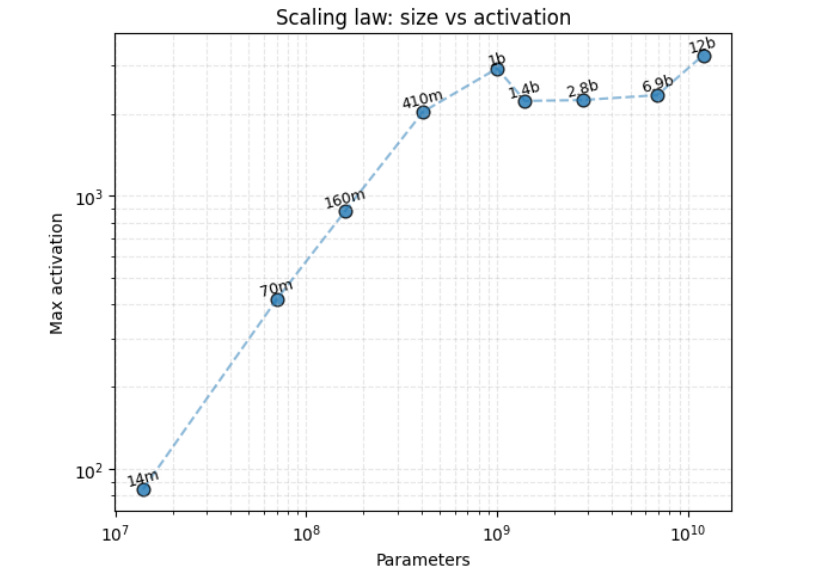
To address this, the paper studies MA development over the course of training using the EleutherAI Pythia model suite, 16 decoder-only transformers from 14M to 12B parameters, each with over 150 intermediate checkpoints. This controlled setup, with consistent data and architectures, enables precise analysis of how MA trajectories vary with model scale and architectural factors like depth, hidden size, and head count. The authors propose a unified mathematical framework for modeling MA emergence and discuss the resulting insights for transformer design, optimization, and interpretability.
MoBE: Mixture-of-Basis-Experts for Compressing MoE-based LLMs
This paper addresses the challenge of deploying extremely large Mixture-of-Experts (MoE) language models, which, while more parameter-efficient to scale than dense models, can still reach hundreds of billions of parameters and overwhelm even high-end GPU infrastructure. Existing MoE compression techniques fall into two main categories: pruning, which removes or merges experts but risks losing specialized knowledge, and decomposition, which uses methods like SVD to factorize weight matrices but often incurs substantial reconstruction error and information loss.
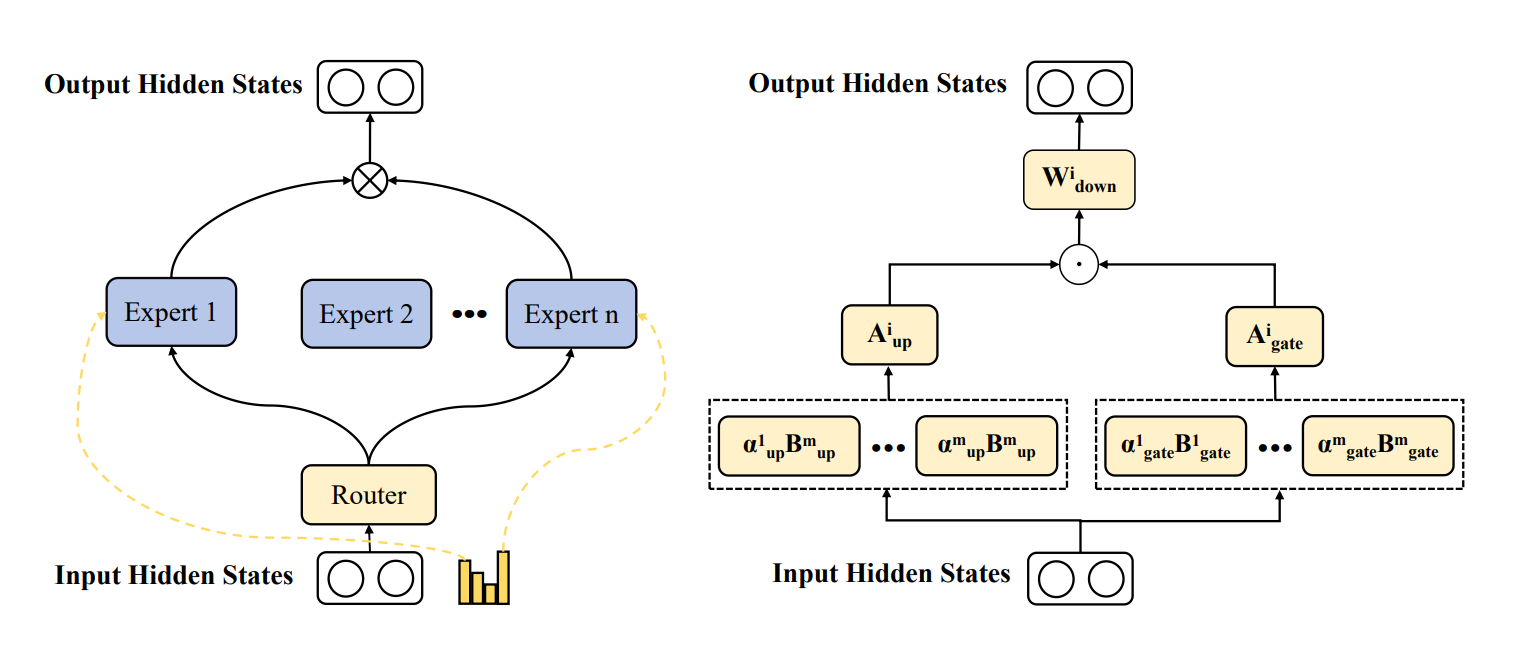
The authors propose Mixture-of-Basis-Experts (MoBE), a new decomposition method that factorizes each expert’s weight matrix W into AB, where A is unique to the expert and B is expressed as a linear combination of a small set of basis matrices shared across all experts in a layer. Since the number of basis matrices m is much smaller than the number of experts n, and A is smaller than W, this structure significantly reduces parameters while preserving information. The factorization is optimized via gradient descent to minimize reconstruction error with respect to the pretrained weights.
Experiments on several state-of-the-art MoE LLMs, including Ling-Lite-Chat, DeepSeek-V2-Lite-Chat, Qwen3-30B-A3B-2507, Qwen3-235B-A22B-2507, DeepSeek-V3-0324, and Kimi-K2-Instruct, show that MoBE consistently achieves lower reconstruction error than MoLAE and D²-MoE, often by more than 50% across all layers. In downstream evaluation across 15 benchmarks, MoBE retains up to 98% of the original model performance while reducing parameter counts by 24–30%, outperforming other compression baselines even at equal or higher compression rates.
The work demonstrates that MoBE delivers state-of-the-art compression for massive MoE models without the steep accuracy losses of pruning or the high MSE of standard SVD decompositions.