


BurstAttention for Very Long Sequences and Faster Speculative Decoding with ReDrafter
The Weekly Salt #9

Reviewed this week
Recurrent Drafter for Fast Speculative Decoding in Large Language Models
⭐Branch-Train-MiX: Mixing Expert LLMs into a Mixture-of-Experts LLM
BurstAttention: An Efficient Distributed Attention Framework for Extremely Long Sequences
Stealing Part of a Production Language Model
⭐: Papers that I particularly recommend reading.
New code repository:
None of the papers reviewed this week released their code.
I maintain a curated list of AI code repositories here:
Recurrent Drafter for Fast Speculative Decoding in Large Language Models
In this study, the authors build upon the concept introduced in Medusa by Cai et al. (2024) to improve speculative decoding. This method, named “recurrent drafter” (ReDrafter), aims to overcome the challenges identified in the Medusa framework. Medusa requires multiple draft heads with separate parameters for predicting different positions while ReDrafter leverages a single set of parameters for its draft heads, applicable across various predictive positions.

This design also introduces interdependencies among the predictive heads.
ReDrafter further simplifies Mesuda by enabling the direct application of beam search to eliminate subpar candidate sequences, thus effectively narrowing down the pool for the target model's evaluation. Additionally, it exploits a tree attention algorithm that leverages beam search outcomes, dynamically generating these during runtime instead of relying on a preset configuration. Unlike Medusa, which facilitates deployment post-training, ReDrafter doesn’t require extra data.
According to empirical experiments, ReDrafter is faster and better than Medusa:

The authors didn’t release their framework.
⭐Branch-Train-MiX: Mixing Expert LLMs into a Mixture-of-Experts LLM
In this study, Meta introduces Branch-Train-MiX (BTX), a method that seeks to blend the benefits of the Branch-Train-Merge approach and the Mixture-of-Experts (MoE) techniques, while overcoming their respective drawbacks.

This is accomplished by initially training several specialized LLMs independently, akin to the Branch-Train-Merge strategy, and then integrating these experts into a unified model employing an MoE framework.
Specifically, they aggregate the feedforward sublayers from each expert LLM into a cohesive MoE module at every layer of the model, with a routing network determining the appropriate feedforward expert for each token. Additionally, they combine the self-attention layers of these expert LLMs by averaging their weights. The composite model then undergoes MoE-finetuning to optimize the router network and the mix of expert feedforward modules.
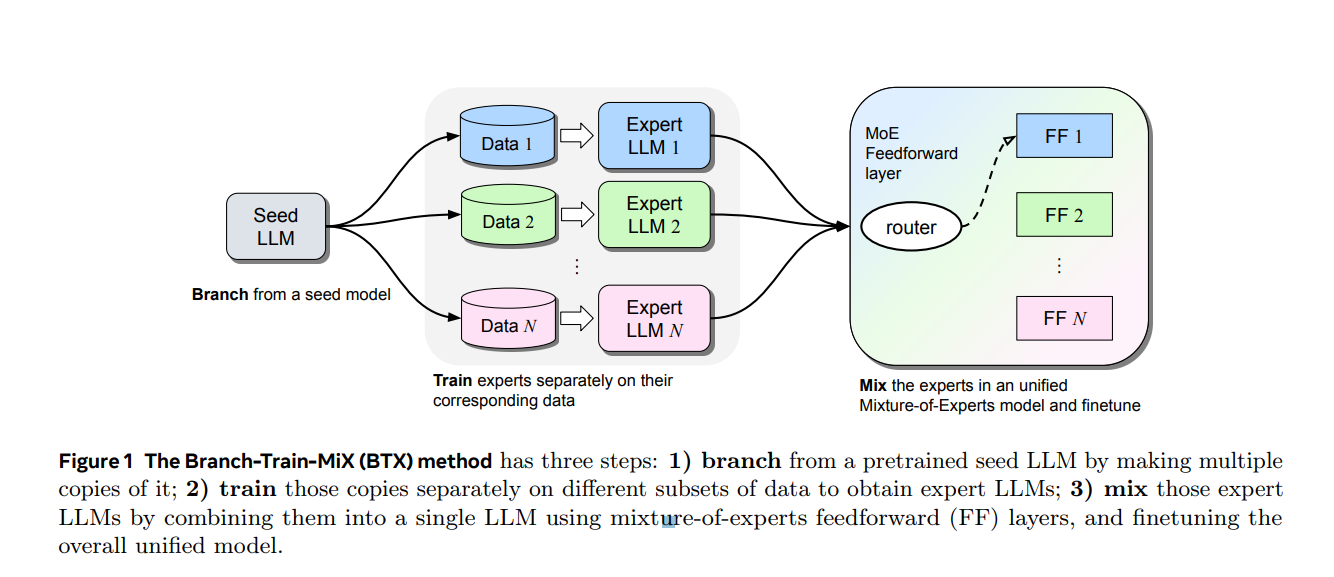
BTX has a significant advantage over traditional MoE models since it allows for the parallel and asynchronous training of expert modules. Furthermore, unlike the Branch-Train-Merge approach, BTX culminates in a singular, coherent neural network that can be further fine-tuned or utilized as any conventional LLM, without substantially increasing the inference computational cost, thanks to its sparse activation despite a higher parameter count.
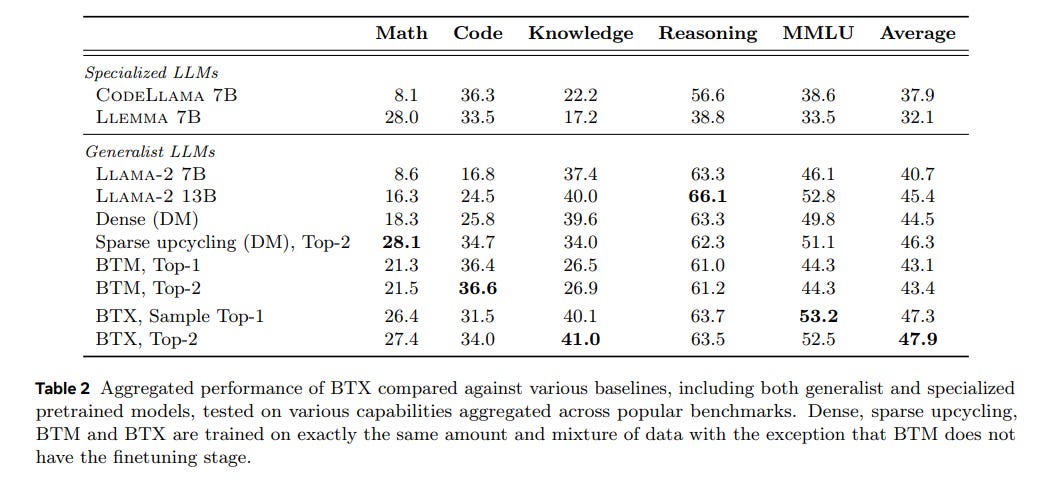
The experiments are based on Llama 2 7B. They trained expert LLMs on distinct data subsets from various fields such as mathematics, coding, and Wikipedia.
The resulting BTX model has better performance across diverse domains compared to the original model, particularly in bridging the performance gap on specialized tasks in mathematics and coding, while maintaining its initial competencies and avoiding the significant knowledge loss often observed in specialized models.
The authors didn’t release their code.
BurstAttention: An Efficient Distributed Attention Framework for Extremely Long Sequences
Efforts to improve the efficiency of attention mechanisms in LLMs have focused on two main approaches: optimizing single-device computation and storage capabilities, such as with FlashAttention, and leveraging distributed systems with multiple devices, like RingAttention.
FlashAttention improves attention computation speed by using static random access memory (SRAM) for storing intermediate states, rather than relying on high-bandwidth memory (HBM).

In contrast, RingAttention processes long sequences by dividing them into subsequences and distributing these across multiple devices for parallel processing.
While they both improve the processing speed and efficiency, integrating them together into a single framework presents challenges. Specifically, the straightforward combination of these methods in a distributed environment may not fully capitalize on their strengths, and there are compatibility issues.
To address these challenges, this paper introduces BurstAttention, an efficient distributed attention framework designed for processing very long sequences. BurstAttention splits a sequence among the devices in a cluster, with each device handling a portion of the sequence by projecting it into query, key, and value embeddings. These segments are then circulated among devices to compute local attention scores, which are aggregated into a global attention score.

BurstAttention optimizes both computation and communication across devices. It improves memory usage, minimizes communication overhead, and enhances cache efficiency. BurstAttention's approach is compatible with other distributed training methods.
In their experiments, they show that BurstAttention reduces communication overhead by 40% and doubles the training speed for sequences of 128K length on 8×A100 GPUs.

The authors don’t mention whether they will release their implementation.
Stealing Part of a Production Language Model
This paper presents a new type of attack for black-box language models able to uncover the entire embedding projection layer of a transformer language model.
Their strategy focuses on a top-down approach, targeting the model's final layer for extraction. It leverages the characteristic that this layer transitions from the hidden dimension to a higher-dimensional logit vector, which is inherently low-rank, allowing us to deduce the model's embedding dimension or its ultimate weight matrix through strategic queries to the model's API.
This approach offers several advantages. It provides insights into the transformer model's width and, by extension, an estimate of its total parameter count. Even though this attack only retrieves a small segment of the model, its success in extracting any parameters from a production model is remarkable;e, suggesting the possibility of more comprehensive future breaches.
This attack targets production models with APIs that allow access to full log probabilities or logit biases. This includes models like Google’s PaLM-2 and OpenAI’s GPT-4, which, following the responsible disclosure by authors (i.e., they have contacted OpenAI and Google before releasing the paper), have fortified their defenses against such attacks. It seems that a way to make this type of attack inefficient is to keep private the logit vectors. OpenAI used to give access to the logits but not anymore.
If you have any questions about one of these papers, write them in the comments. I will answer them.