
Chain-of-Thought with a Token Budget
The Weekly Salt #49


For this last issue of 2024, I reviewed:
⭐Token-Budget-Aware LLM Reasoning
ReMoE: Fully Differentiable Mixture-of-Experts with ReLU Routing
Safeguard Fine-Tuned LLMs Through Pre- and Post-Tuning Model Merging
⭐: Papers that I particularly recommend reading.
New code repositories (list of all repositories):
Token-Budget-Aware LLM Reasoning
Reasoning is a key factor for LLMs to perform well across diverse tasks. One well-known method to improve reasoning is Chain-of-Thought (CoT), which uses prompts like "Let’s think step by step" to guide the model in breaking problems into smaller, sequential steps. This step-by-step reasoning improves the reliability of the model's answers, as illustrated by examples where CoT transforms incorrect responses into correct ones by addressing each step incrementally.
While CoT significantly boosts LLM performance, it comes with a downside: increased token usage. The intermediate reasoning steps in CoT lead to much longer outputs, resulting in higher computational, energy, and monetary costs during inference.
Is the reasoning process unnecessarily lengthy, and can it be streamlined?
Recent work shows that introducing a token budget into prompts can compress the reasoning process. For example, setting a 50-token budget reduced token usage from 258 to 86 tokens while maintaining correct answers. However, when the token budget is set too low (e.g., 10 tokens), LLMs often fail to adhere to the budget, producing outputs that far exceed it. This phenomenon, called "Token Elasticity," highlights the difficulty in finding the right balance between token usage and output quality.

To address this, the authors developed a method called TALE (Token-Budget-Aware LLM rEasoning). TALE dynamically estimates an optimal token budget for each problem based on its complexity and uses this budget to guide the reasoning process. By gradually adjusting the token budget, TALE identifies the smallest budget that allows the LLM to produce accurate answers with minimal token cost. Experimental results show that TALE achieves, on average, a 68.64% reduction in token usage, with less than a 5% drop in answer accuracy.
This is a very relevant work given that language models tend to go toward using inference budget to improve the LLM capabilities.
The code is here:
GitHub: GeniusHTX/TALE
ReMoE: Fully Differentiable Mixture-of-Experts with ReLU Routing
Transformer models improve as they scale up, but computational constraints limit their growth. Sparsely activated Mixture-of-Experts (MoE) models address this by selectively activating subsets of parameters, enabling larger capacities without higher computational costs. Central to MoE is the routing network, which decides which "experts" to activate. The commonly used TopK routing activates a fixed number of experts, but its discrete nature hinders scalability and performance.
Recent attempts to create fully differentiable MoE models, such as Soft MoE and SMEAR, have shown promise but fail to support autoregressive tasks due to broken token causality.
This work proposes ReMoE, a new MoE architecture that replaces TopK routing with ReLU routing. ReLU routing uses ReLU gates to control expert activation, allowing continuous, differentiable, and flexible allocation of resources. It supports variable expert activation per token and layer, adapting more effectively to token frequency and domain specialization. To ensure controlled sparsity, ReMoE uses an L1 regularization technique with adaptive tuning.
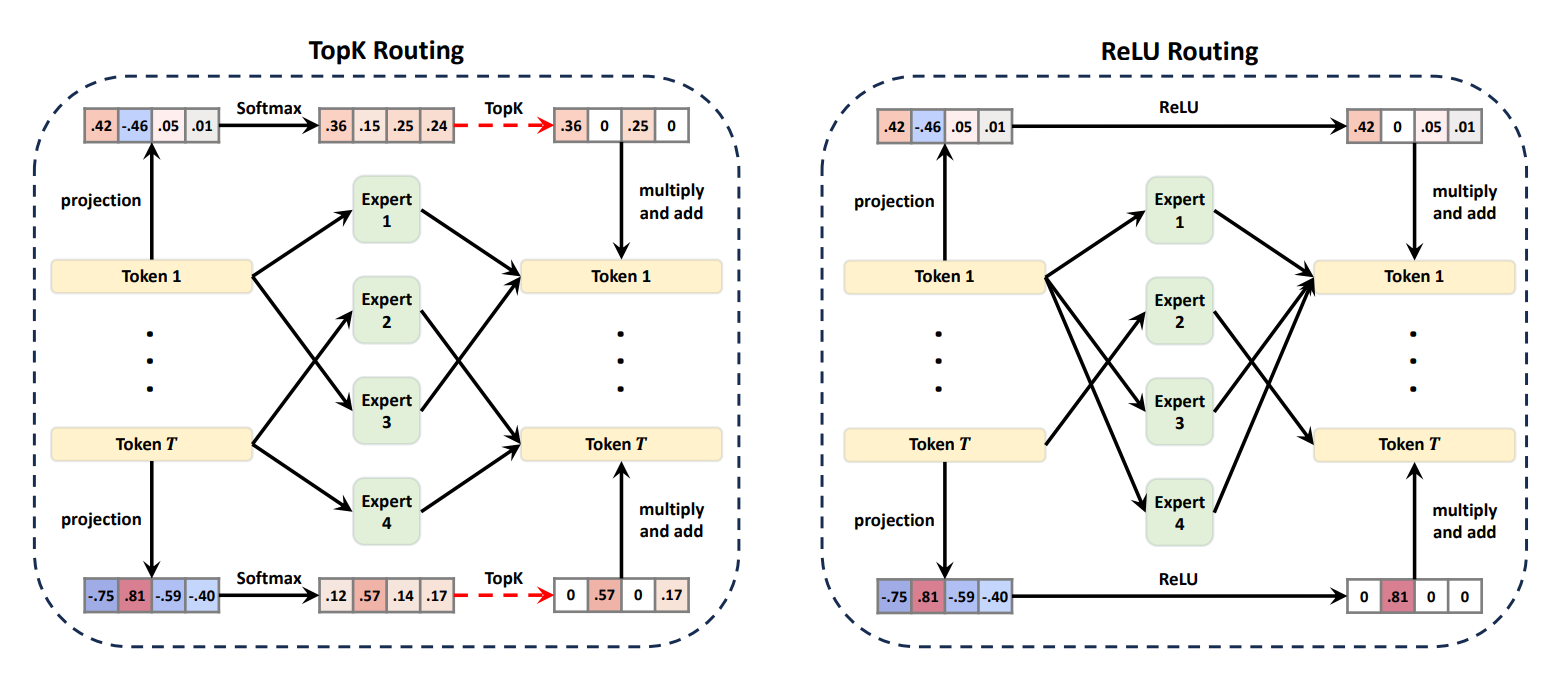
ReMoE matches TopK in computational efficiency while outperforming it in performance. Experiments on the LLaMA architecture show that ReMoE achieves better results than TopK. ReMoE also scales better, showing greater performance gains as the number of experts increases, making it a highly efficient and scalable approach for MoE models.
The code is here:
GitHub: thu-ml/ReMoE
Safeguard Fine-Tuned LLMs Through Pre- and Post-Tuning Model Merging
Safety techniques for LLMs like preference tuning have been introduced to prevent harmful or inappropriate outputs. Many applications now use safety-aligned base models.
However, recent studies reveal that fine-tuning can unintentionally degrade the safety of these models, even with benign datasets. Existing solutions often add safety data during fine-tuning or rely on complex model-merging methods that require extensive resources and specialized safety datasets. These approaches are limited by the scarcity of safety data and high resource demands.
To address this, the authors propose a straightforward two-step method: (1) fine-tune the base model on the downstream task, and (2) merge the base model with the fine-tuned model. To my surprise, this simple approach improves downstream task performance while preserving safety. Experimental results show that this method reduces the Attack Success Rate (ASR) by up to 30% while boosting task performance. Evaluations across multiple models, tasks, merging techniques, and safety benchmarks demonstrate its robustness and effectiveness.
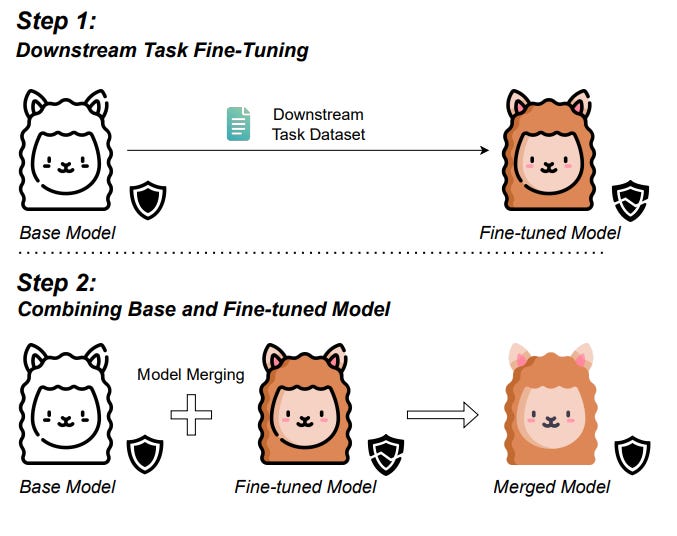
If the results can be reproduced, this is a very simple method that should be systematically applied.
I haven't taken a closer look at ReMoE yet, but if ReLU is used as the expert selection principle, it seems that there is a possibility that every expert will have a negative "score" early in the training and "no experts will be selected".
And happy New Year Benjamin! As always, I look forward to your more sharing in the New Year!