
Collaborative Parallel Thinking for Efficient Test-Time Scaling
The Weekly Salt #119


This week, we review:
⭐Share More, Search Less: Collaborative Parallel Thinking for Efficient Test-Time Scaling
Less is More: Early Stopping Rollout for On-Policy Distillation
Negligible in Size, Significant in Effect: On Scale Vectors in Large Language Models
⭐Share More, Search Less: Collaborative Parallel Thinking for Efficient Test-Time Scaling
This paper studies a bottleneck in parallel test-time scaling: multiple reasoning branches often rediscover the same intermediate information because they do not communicate until final answer aggregation.
The proposed method, Collaborative Parallel Thinking (CPT), keeps the branches separate but periodically extracts compact intermediate findings, deduplicates them into a query-level shared pool, and broadcasts selected entries back into the context for subsequent decoding.
CPT is training-free and uses the same policy model both for reasoning and for extracting information units. Sharing is not active throughout the whole run: the method first lets branches explore independently, starts broadcasting when marginal new information drops, and stops synchronization when further sharing appears unlikely to help. This design targets the latency cost of redundant exploration while trying to avoid early collapse of branch diversity.
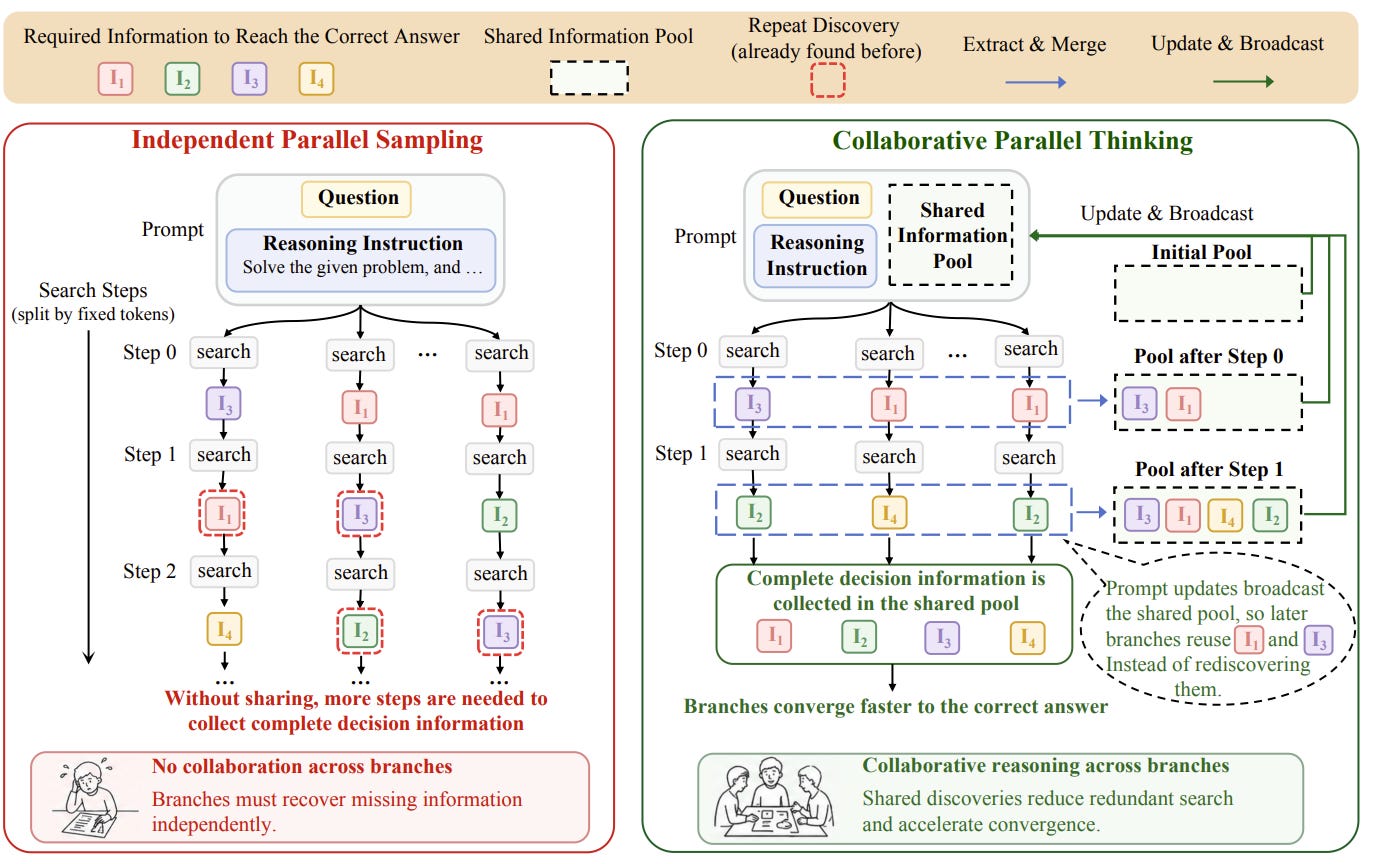
Experiments on HMMT and AIME math benchmarks with Qwen3-Thinking models compare CPT against parallel sampling, DeepConf, and LeaP across rollout budgets. CPT improves the accuracy–latency frontier in these settings, with gains in both individual branch accuracy and majority-vote accuracy. The analysis suggests that its benefit comes from reducing duplicate intermediate discoveries rather than only making branches agree earlier.
The main caveat is implementation cost. CPT shares information through prompt-context updates, which can require re-prefilling and add FLOPs even when generated-token usage and wall-clock latency improve. The idea is most compelling where parallel decoding is already available and latency matters more than raw FLOPs.
Less is More: Early Stopping Rollout for On-Policy Distillation
The paper studies a failure mode in on-policy distillation, where a student generates rollouts and a teacher provides token-level supervision on those rollouts.
The authors argue that late-token supervision can become unreliable because the teacher is conditioned on a prefix produced by the student rather than by itself. As the student prefix drifts away from the teacher’s preferred trajectories, the teacher increasingly behaves like a next-token completer rather than a corrective evaluator.
The proposed fix, Early Stopping Rollout: generate and train only on the first part of the student response, typically the first 100 tokens, while leaving the rest of the on-policy distillation loop unchanged. Across math, coding, and function-calling experiments, this truncated-rollout version usually matches or outperforms full-rollout distillation, with the largest gains in cross-generation and cross-family teacher–student pairs where full-rollout training is less stable. The method also reduces generation and training cost substantially because it avoids long student rollouts.
The analysis suggests that early tokens carry disproportionate value because they often encode framing, planning, and commitment to a solution strategy. Training only on this early window can still reduce teacher–student divergence at later positions, an effect the authors call cascading alignment. They also report that the student can converge to a useful supported sub-mode of the teacher distribution rather than copying the teacher’s dominant behavior, which may explain cases where the distilled student exceeds the teacher on the reported metrics.
Negligible in Size, Significant in Effect: On Scale Vectors in Large Language Models
This work studies the learnable scale vectors in normalization layers of LLMs, a small parameter group that is usually treated as an implementation detail. The central result is that these vectors matter primarily through optimization, not expressivity: in Pre-Norm Transformers they can be absorbed into adjacent linear maps, yet removing them worsens pre-training loss and token efficiency.
The authors analyze how scale vectors act as lightweight, state-dependent preconditioners for nearby linear mappings. This framing leads to several design choices: using branch-specific scale vectors, changing where scale vectors are placed around linear maps, reparameterizing their magnitude and direction, and applying weight decay differently depending on whether a scale vector sits before or after a linear map.
Experiments validate these choices in dense and MoE Llama-style models from 0.12B to 2B parameters, under long-token pre-training budgets and across AdamW, Muon, and warmup-stable-decay schedules. The combined strategy consistently lowers terminal validation loss relative to tuned baselines, with small wall-clock and memory overhead.