


Reviewed this week
⭐Compact Language Models via Pruning and Knowledge Distillation
PrimeGuard: Safe and Helpful LLMs through Tuning-Free Routing
SaulLM-54B & SaulLM-141B: Scaling Up Domain Adaptation for the Legal Domain
⭐: Papers that I particularly recommend reading.
New code repositories:
I maintain a curated list of AI code repositories here:
⭐Compact Language Models via Pruning and Knowledge Distillation
This paper by NVIDIA conducts an empirical exploration of structured pruning and retraining across various axes, including neurons in feed-forward layers, heads in multi-head attention layers, embedding channels, and model depth.
Pruning neurons and heads alone is more effective than including embedding channels, but this reverses after some retraining. Similarly, width pruning surpasses depth pruning only after retraining. The research details efficient retraining techniques for pruned models using minimal additional data.
Based on these findings, the paper presents a practical guide for LLM compression and retraining best practices.

These methods are applied to prune the Nemotron-4 15B model, resulting in the creation of the MINITRON family of smaller models. MINITRON 8B outperforms Nemotron-3 8B, and Llama 2 7B, and is comparable to Mistral 7B, Gemma 7B, and Llama 3 8B on MMLU.

MINITRON 4B also shows superior performance compared to similarly sized models.
The code is available here:
GitHub: NVlabs/Minitron
PrimeGuard: Safe and Helpful LLMs through Tuning-Free Routing
This work investigates Inference-Time Guardrailing (ITG) methods to align pre-trained and instruction-tuned LLMs with stringent safety protocols during deployment.
They adapted 15 safety categories from OpenAI’s guidelines, balancing restrictive instructions with helpful directive instructions. Their analysis revealed trade-offs between helpfulness and compliance in current ITG strategies.
They also introduce PrimeGuard, a tuning-free method using two language models (LLMMain and LLMGuard) to dynamically route responses based on risk categorization and specific guidance. This approach aimed to maximize adherence to safety guidelines while maintaining usefulness.
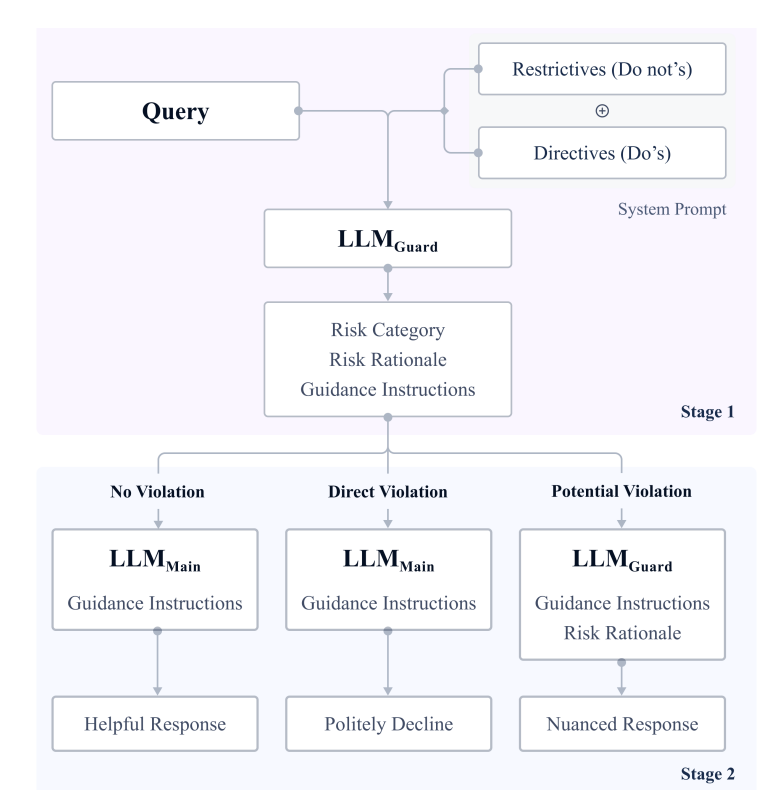
Evaluations were conducted using the safe-eval dataset, combining adversarial safety queries with existing datasets. PrimeGuard significantly improved model performance, with safer responses and reduced vulnerability to adversarial attacks, while also increasing helpfulness compared to models with only alignment tuning.
Their implementation of PrimeGuard is available here:
GitHub: dynamofl/PrimeGuard
SaulLM-54B & SaulLM-141B: Scaling Up Domain Adaptation for the Legal Domain
The paper presents an empirical study on the scalability and domain adaptation of LLMs in the legal domain.
The study makes two principal contributions. First, it provides an analysis of domain adaptation strategies for legal LLMs. It fully describes the process of developing modern LLMs, from continued pretraining to instruction fine-tuning and alignment, using both synthetic and real data. This is the most interesting part of this work.

Second, the paper introduces SaulLM-54B and SaulLM-141B, based on the mixture of expert models Mixtral 54B and Mixtral 141B, which join SaulLM-7b to form a family of legal LLMs under a permissive license (but which one exactly, we don’t know yet).

The models will be released on the Hugging Face Hub.
If you have any questions about one of these papers, write them in the comments. I will answer them.