


Compress the KV Cache with SnapKV
The Weekly Salt #15

Reviewed this week
Multi-Head Mixture-of-Experts
⭐SnapKV: LLM Knows What You are Looking for Before Generation
AdvPrompter: Fast Adaptive Adversarial Prompting for LLMs
Make Your LLM Fully Utilize the Context
⭐: Papers that I particularly recommend reading.
New code repositories:
I maintain a curated list of AI code repositories here:
In contrast to dense models, the sparse mixture of experts (SMoE) architecture integrates parallel feedforward neural networks, the experts, into its modules, relying on a router network to selectively activate specific experts for different input tokens at each layer of the model.
This strategy makes SMoEs more efficient for inference. For instance, Mixtral-8×7B is an implementation of SMoE with eight experts among which 2 are active during inference, demonstrating comparable or superior performance to both Llama 2 70B and GPT-3.5.

However, SMoEs have some limitations, including low activation rates for their experts, with only a small fraction, such as 8.33%, being regularly activated. This underuse limits the model's overall effectiveness and scalability, particularly when the number of experts is large. Additionally, SMoEs struggle with fine-grained analytical tasks due to the coarse or overly fine tokenization patterns that either overlook subtle details or require excessive computation.
To address these drawbacks, this paper proposes a new approach called Multi-Head Mixture-of-Experts (MH-MoE). It introduces a multi-head mechanism that divides each input token into multiple sub-tokens, each assigned to different experts. This allows for denser expert activation without increasing computational load or parameter count. For example, MH-MoE can activate four experts for a single input token by dividing it into four sub-tokens, compared to just one expert in the traditional SMoE approach.

MH-MoE maintains several advantages, including higher expert activation rates, improved scalability, and a finer-grained understanding of complex data patterns. It’s also easy to implement according to the authors.
The effectiveness of MH-MoE has been validated across various settings, including English-focused language modeling, multilingual language modeling, and masked multi-modality modeling.

The authors will release the code here (404 error when I was writing this article):
GitHub: yushuiwx/MH-MoE
SnapKV: LLM Knows What You are Looking for Before Generation
There are various strategies to address memory efficiency problems in LLMs, such as using a KV cache during token generation. However, many of these approaches do not thoroughly evaluate the context in scenarios involving extensive content and tend to focus primarily on optimizing the KV cache during the generation phase rather than on compressing the KV cache for input sequences, which is often the main challenge in terms of memory usage.
This issue becomes particularly significant in applications like chatbots and agents, where inputs can include lengthy conversations, articles, or codebases, and these inputs are usually much larger than the generated responses, leading to substantial memory overhead. Compressing such large inputs without omitting essential information for accurate output is an additional challenge.
In this research, the authors analyzed the attention patterns allocated to prompt tokens during inference and designed SnapKV to compress the KV cache efficiently for long input sequences without sacrificing accuracy.
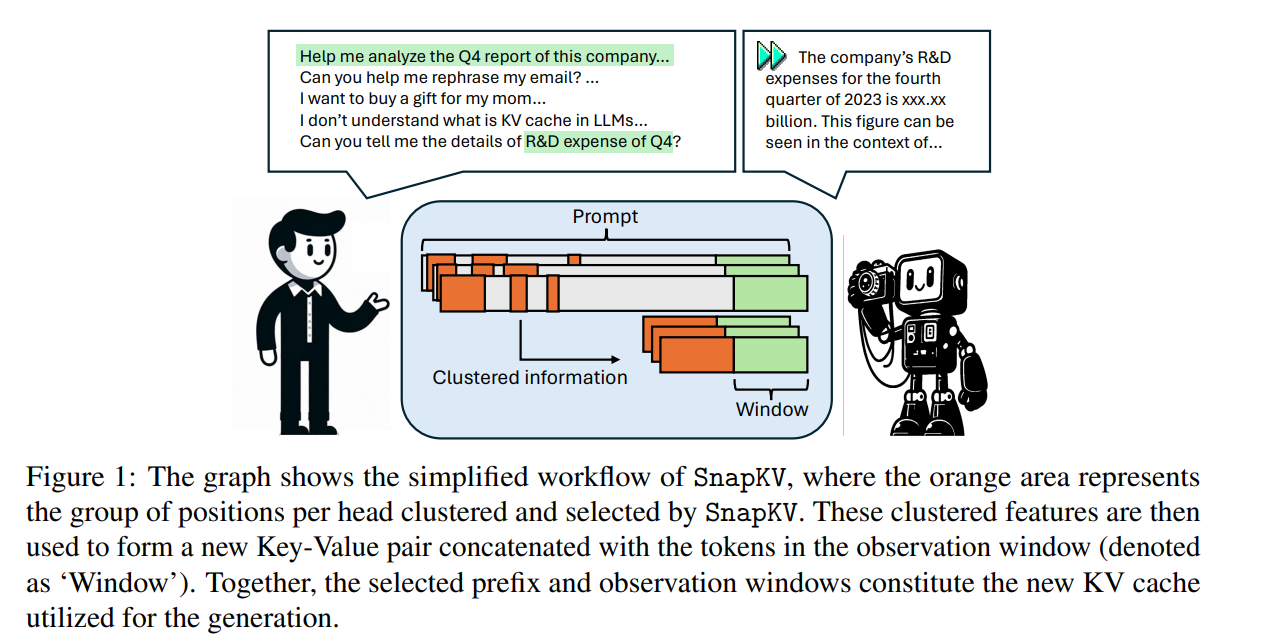
SnapKV selectively compresses important KVs with minimal alteration, which allows for straightforward integration into existing deep learning frameworks with minimal code modifications.
They validated the effectiveness of SnapKV across various LLMs and datasets for long sequences, demonstrating improvements over prior methods and performance comparable to traditional KV caching techniques.

The authors released their code here:
GitHub: FasterDecoding/SnapKV
AdvPrompter: Fast Adaptive Adversarial Prompting for LLMs
As jailbreaking attacks on LLMs increase in frequency and ease of replication, it became necessary for developers to engage in red-teaming to proactively spot and rectify LLMs’ flaws to maintain their security.
Red-teaming often involves the creation of adversarial prompts by humans. It is not only time-consuming but also susceptible to oversight, which can lead to a misleading sense of security.
This paper introduces a new automated red-teaming method, named AdvPrompter. This method is designed to generate a variety of human-readable adversarial prompts quickly.
AdvPrompter generates adversarial suffixes that can challenge a target LLM, guided by user instructions. The training method, AdvPrompterTrain, involves an optimization algorithm, AdvPrompterOpt, which iteratively produces adversarial suffixes while maintaining readability, assessed through the perplexity of a base LLM. This is alternated with supervised fine-tuning using the adversarial suffixes as targets.

The benefits of this approach include the generation of coherent, human-like adversarial prompts that effectively mimic human-generated ones without requiring direct human intervention.
This method, unlike previous ones, produces attacks that are less susceptible to simple perplexity-based defenses. Moreover, the AdvPrompter has demonstrated a higher attack success rate, better adaptability to various instructions, quicker generation times, and the ability to generate adversarial prompts without relying on gradient information from the target LLM.
This process has been shown to increase the robustness of the target LLM against attacks while maintaining general knowledge.
The authors mentioned that they will release their code here:
GitHub: facebookresearch/advprompter
Make Your LLM Fully Utilize the Context
Recent research has identified a significant challenge faced by long-context LLMs, known as the "lost-in-the-middle" challenge. Studies suggest that while these models effectively grasp information at the beginning and end of extensive contexts, they tend to overlook middle sections. This oversight can impact their performance, as shown by their failure in tasks like Needle-in-the-Haystack and passkey retrieval.
The authors of this work have developed a training strategy called INformation-INtensive (IN2) training. This approach teaches the model that important information can be located throughout the entire context, not just at its extremities. IN2 training involves a synthesized long-context question-answer dataset, where long sequences (ranging from 4,000 to 32,000 tokens) are formed from multiple short segments. The dataset includes question-answer pairs that focus on extracting information from randomly placed segments, either from a single segment or by integrating multiple segments.

Their experiment results showed that IN2 training addressed the lost-in-the-middle issue while performing well on short-context tasks.
The code related to this paper is available here:
GitHub: microsoft/FILM
If you have any questions about one of these papers, write them in the comments. I will answer them.