
Cross Capabilities of LLMs and Contextual Document Embeddings
The Weekly Salt #38


Reviewed this week:
⭐Law of the Weakest Link: Cross Capabilities of Large Language Models
⭐Contextual Document Embeddings
Training Language Models on Synthetic Edit Sequences Improves Code Synthesis
⭐: Papers that I particularly recommend reading.
New code repositories (list of all repositories):
Get a subscription to The Salt, The Kaitchup, The Kaitchup’s book, and multiple other advantages by subscribing to The Kaitchup Pro:
⭐Law of the Weakest Link: Cross Capabilities of Large Language Models
The development and evaluation of LLMs have traditionally focused on individual capabilities. Developers typically create specialized datasets to train models for distinct skills, such as reasoning, coding, or managing factual knowledge. For example, Llama 3's post-training incorporates a blend of data aimed at enhancing specific abilities. Similarly, evaluation methods tend to assess these skills in isolation, using benchmarks to evaluate a model's performance on specific tasks like reasoning or coding.
However, complex prompts, such as asking for an analysis of long-term trends or a comprehension of coding within a web application, require a combination of expertise across areas like tool use, reasoning, and coding. These scenarios, termed cross capabilities, involve the intersection of multiple abilities, highlighting the limitations of current evaluation practices focused on individual skills.

This paper explores the dynamics of LLM performance on tasks requiring cross capabilities, questioning how well models perform when multiple skills must work together. Drawing from theories such as “Synergy Theory,” “Compensatory Mechanism,” and “Law of the Weakest Link,” it suggests that a system's overall performance can be limited by its weakest component. This research emphasizes the importance of understanding how individual capabilities affect collective performance, with a particular focus on improving weaker areas to boost performance on cross-capability tasks.
To address these issues, the authors introduce a framework called CrossEval (CC-BY-NC), designed to benchmark both individual and cross capabilities. This framework involves constructing a taxonomy of capabilities and evaluating LLM responses through human ratings and model-based evaluators. The findings reveal clear patterns: cross-capability performance is often limited by the weakest individual ability, with areas like tool use posing significant challenges.
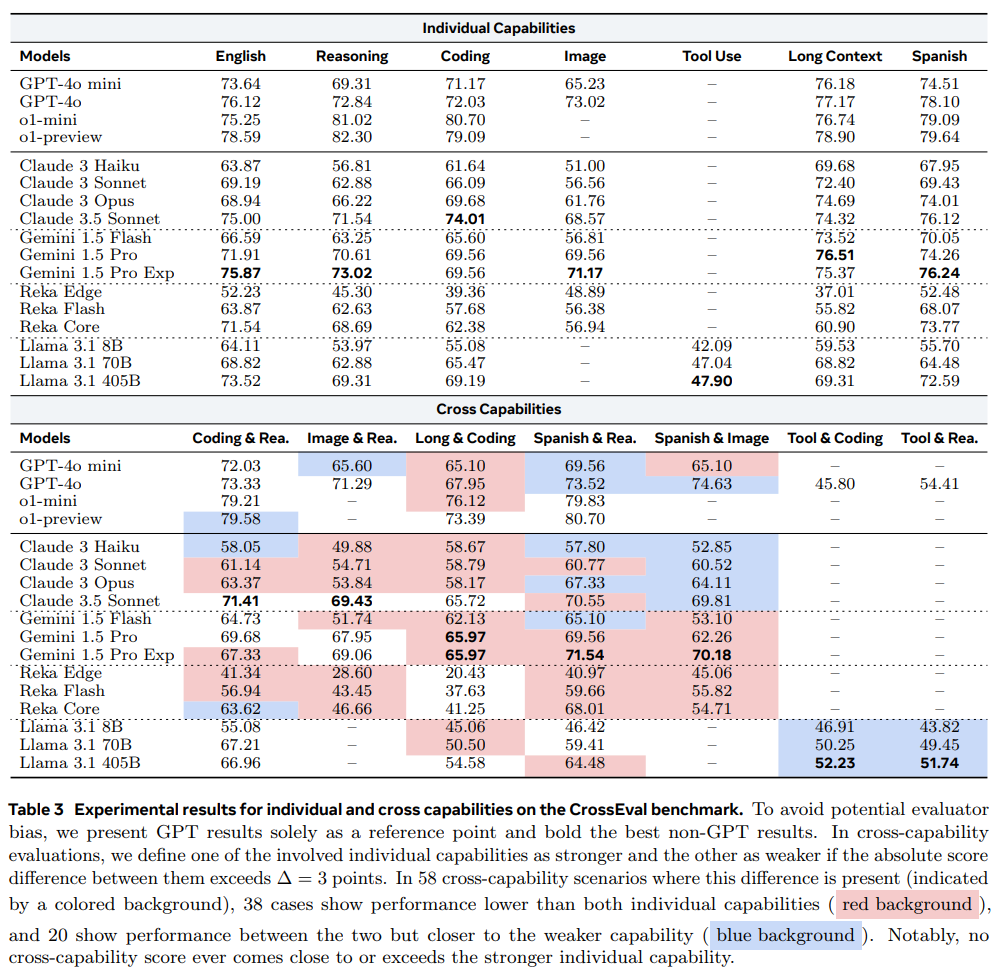
Additionally, the research shows that improving weaker capabilities leads to significant gains in tasks requiring multiple skills, reinforcing the "Law of the Weakest Link" effect. Enhancements to stronger abilities, however, result in only minor improvements. The paper concludes by emphasizing the need to prioritize the development of cross-capability performance in LLMs, as current models generally struggle with these complex tasks. Identifying and addressing weak points in specific capabilities is crucial for advancing LLM effectiveness in real-world applications.
⭐Contextual Document Embeddings
Machine learning approaches to text retrieval have traditionally relied on statistical methods like BM25, which use sparse lexical matching based on n-gram frequencies. However, recent advances in neural networks have introduced competitive models for retrieval tasks. The primary neural method, known as a dual encoder architecture, encodes both a document and a query into a dense latent space for retrieval. While this approach offers advantages over statistical models by being learned end-to-end, it loses certain benefits, such as the ability to incorporate corpus-specific statistics like inverse document frequency (IDF), which allows for contextual weighting in different domains.
To address this limitation, this work explores enhancing the contextualization of document embeddings produced by dense neural encoders. The authors propose two key innovations: a contextual training procedure and a new encoder architecture. The contextual training method integrates the concept of neighboring documents into the contrastive learning process, allowing the model to better differentiate documents in challenging contexts by using query-document clustering to group related documents. The proposed architecture, called Contextual Document Embedding (CDE), extends the standard BERT-style encoder by conditioning the embeddings on neighboring documents, similar to how corpus-level statistics influence term weighting in statistical models. This approach maintains the same embedding size, preserving the efficiency of the retrieval process.

Experiments show that both the contextual training procedure and the contextual encoder architecture significantly improve the performance of text embedding models. These improvements are particularly notable in domain-specific retrieval tasks, such as financial and medical documents.
I expect these new embeddings to significantly improve RAG.

Training Language Models on Synthetic Edit Sequences Improves Code Synthesis
Code synthesis presents unique difficulties for LLMs because solutions are both structured and long-form. Humans approach such problems by creating abstract mental models and developing step-by-step plans, such as using object-oriented programming to incrementally build complex codebases. In contrast, LLMs typically attempt to synthesize entire programs from scratch, which becomes computationally expensive and leads to quality degradation as sequences grow.
Current LLM-powered code editing tools, such as Cursor, repeatedly prompt models to rewrite entire programs for each edit, further exacerbating this issue. This makes finding a reliable balance between generation quality and computational cost difficult, particularly with smaller models.
To address these challenges, the authors propose reparameterizing code synthesis as a sequential edit problem, training models to generate code by predicting sequences of edits rather than entire programs. However, one obstacle is the scarcity of high-quality data for code edits. To overcome this, they introduce LintSeq (MIT license; code not released yet when I wrote this), an algorithm that converts existing programs into sequences of error-free code edits. LintSeq operates in two phases: first, it samples sequences of error-free program states from a source file using a static program verifier (linter), then it computes edit sequences by reversing these states and using the Unix diff operator to find differences between consecutive versions of the program.

The authors conducted experiments comparing LLMs fine-tuned on edit sequences with those fine-tuned on full programs using standard instruction data. They evaluated the models on code synthesis benchmarks like HumanEval and MBPP. The results show several key findings:
Across models ranging from 150M to 14B parameters, fine-tuning on edit sequences improves the quality and diversity of synthesized code.
The increased diversity of samples allows for smoother improvements in pass@k performance as a function of inference-time compute.
Smaller models trained on edit sequences achieve state-of-the-art performance within their size class.
For smaller LLMs, repeated sampling from edit sequence models yields HumanEval coverage that is competitive with larger models like GPT-4, while maintaining a similar cumulative cost to sampling once from models like Llama 3.1.
Removing the linter from the data generation process decreases the quality of the synthesized code, highlighting its importance.
If you have any questions about one of these papers, write them in the comments. I will answer them.