


DeBERTaV3 Remains a Top Performer Among Encoder-Only Models
The Weekly Salt #64


This week, we read:
⭐ModernBERT or DeBERTaV3? Examining Architecture and Data Influence on Transformer Encoder Models Performance
Self-Steering Language Models
Iterative Self-Training for Code Generation via Reinforced Re-Ranking
⭐: Papers that I particularly recommend reading.
⭐ModernBERT or DeBERTaV3? Examining Architecture and Data Influence on Transformer Encoder Models Performance
This paper presents a detailed and controlled comparison of encoder-only transformer models, specifically ModernBERT, DeBERTaV3, and RoBERTa, to assess how much of their performance is due to architectural improvements versus the quality and composition of their training data.
The study is motivated by the growing popularity of newer encoder-only models like ModernBERT, which claims state-of-the-art performance over DeBERTaV3, a previously leading model. However, according to the authors, such claims are hard to interpret due to inconsistencies in training data across evaluations.
The authors design a controlled experimental setup where they pretrain all models on the same French-language dataset, using CamemBERTaV2 (a DeBERTaV3-based model with publicly available training data and checkpoints) as their primary benchmark. This setup includes a new French ModernBERT model trained on the same dataset as CamemBERTaV2 and a version trained on a higher-quality, filtered French corpus. They also include CamemBERTv2, a RoBERTa-based model trained on the same data, to broaden the architectural comparison.
Their results show that DeBERTaV3 consistently outperforms ModernBERT in terms of benchmark accuracy and sample efficiency when all models are trained on identical data. This suggests that the performance edge comes from architectural and training objective optimizations rather than differences in data. However, ModernBERT still offers clear practical advantages, particularly in terms of training and inference speed, due to design optimizations focused on efficiency. While it doesn’t surpass DeBERTaV3, ModernBERT does outperform older architectures like BERT and RoBERTa.
Interestingly, while using a higher-quality training dataset led to faster convergence, it did not result in significant gains in final performance metrics. This points to a possible benchmark saturation effect, where existing evaluation datasets are no longer sensitive enough to capture subtle but meaningful architectural differences.
This paper introduces DISCIPL, a new meta-reasoning framework designed to improve language model performance on tasks that require precise, constrained reasoning, such as composing poetry, solving puzzles, or generating sentences with specific structural requirements.
Current methods like chain-of-thought prompting are flexible but slow and often unreliable, while structured inference methods (like tree search or Monte Carlo sampling) are more efficient but typically domain-specific and reliant on external verifiers.

DISCIPL addresses this by letting a Planner LM dynamically generate a custom inference program, a probabilistic plan encoding how to solve the task, which is then executed by a set of Follower LMs. This structure combines the adaptability of serial reasoning with the efficiency of parallel search. For example, instead of having a model blindly generate constrained text, DISCIPL allows the Planner to explicitly specify where constraints apply and how to guide sampling, which the Followers carry out in parallel, leading to faster and more reliable results.
The authors evaluate DISCIPL on two domains: COLLIE, a constrained generation benchmark where standard LMs often fail, and PUZZLES, a suite of complex language tasks involving creative and logical reasoning. DISCIPL shows notable improvements.
Iterative Self-Training for Code Generation via Reinforced Re-Ranking
This paper presents RewardRanker, a reranker model designed to improve the quality of AI-generated code by addressing the inconsistency and lack of coherence often found in other models. These conventional models tend to produce highly variable outputs, leading to a significant gap between metrics like Pass@1 and Pass@100 on benchmarks such as HumanEvalX and MultiPL-E.
To tackle this, RewardRanker selects the best outputs from a pool of generated code samples, improving both the immediate quality and long-term performance of code generation systems. The model is trained using an iterative self-training loop, which follows these main steps:
Supervised fine-tuning of a base model.
Training the RewardRanker to evaluate code samples.
Using a PPO-based model to generate new outputs.
Identifying strong (positive) and challenging (hard negative) examples.
Feeding these examples back into training for further refinement.
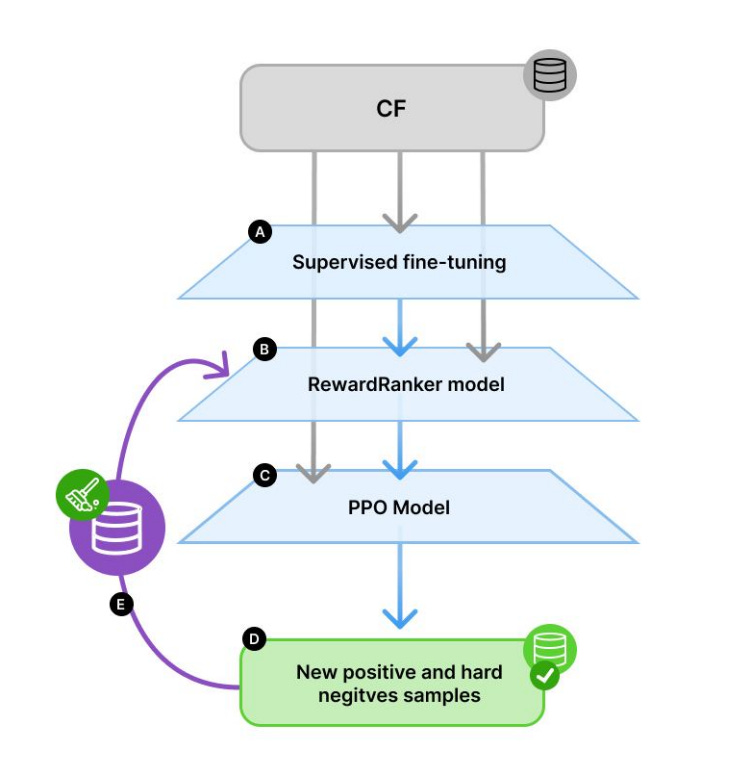
This cycle helps the model learn from both successes and mistakes, strengthening its ability to generalize and make better reranking decisions over time.
They trained a 13.4 billion parameter model with this method and achieved very promising results.