


Decode-decoder and How to Detect Under-trained Tokens
The Weekly Salt #17

Reviewed this week
Lory: Fully Differentiable Mixture-of-Experts for Autoregressive Language Model Pre-training
You Only Cache Once: Decoder-Decoder Architectures for Language Models
Large Language Models are Inconsistent and Biased Evaluators
⭐Fishing for Magikarp: Automatically Detecting Under-trained Tokens in Large Language Models
⭐: Papers that I particularly recommend reading.
New code repositories:
I maintain a curated list of AI code repositories here:
Lory: Fully Differentiable Mixture-of-Experts for Autoregressive Language Model Pre-training
Lory introduces two new techniques for mixture-of-experts models:
Causal segment routing divides a sequence of input tokens into fixed-length segments. The weight of the router for each segment is determined by the previous one, which also calculates the merged expert for the following segment. During inference, the prompt alone can guide the entire generation's routing decisions. This method maintains the sequential structure of language models while optimizing merging operations.
Similarity-based data batching groups semantically similar documents to improve the model's ability to handle transitions between documents.

The Lory models are pre-trained using a budget of 150 billion tokens, with configurations using 0.3 billion and 1.5 billion active parameters, and 8 to 32 experts.
These models demonstrate significant improvements over comparably sized dense models, showing gains in perplexity in various tasks like commonsense reasoning, reading comprehension, closed-book question answering, and text classification.
Despite relying on segment-level routing, Lory competes effectively with state-of-the-art MoE models that use token-level, non-differentiable discrete routing.
You Only Cache Once: Decoder-Decoder Architectures for Language Models
In this study, the authors introduce YOCO, a decoder-decoder architecture for LLMs. This architecture caches key-value (KV) pairs only once. It is made of a self-decoder that uses self-attention to cache KV pairs efficiently, followed by a cross-decoder that utilizes these KV pairs through cross-attention.
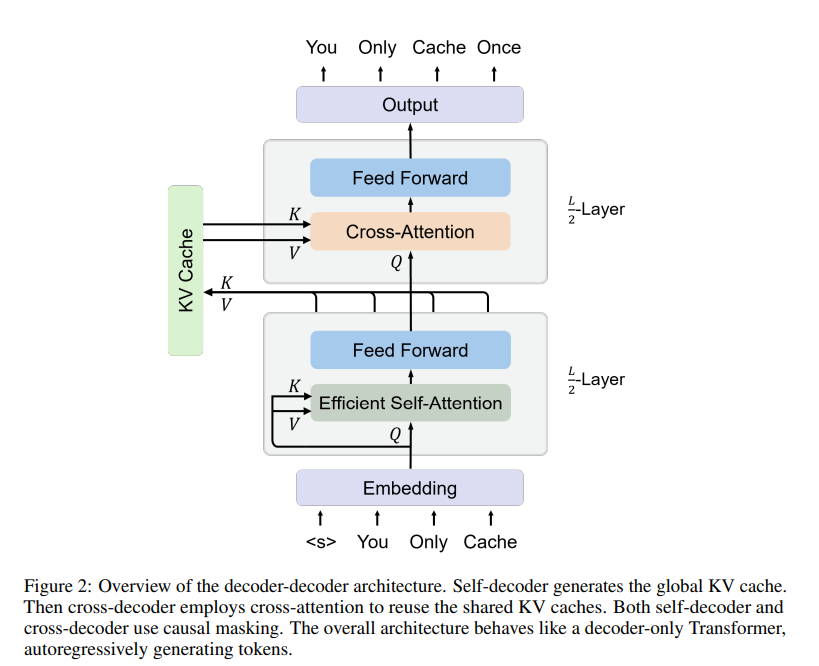
This setup is conceptually akin to the traditional encoder-decoder but operates similarly to a decoder-only model from an external perspective. It makes YOCO suitable for autoregressive generation tasks like language modeling.
One of the key advantages of YOCO is its reduced GPU memory usage due to caching KV pairs just once. Moreover, YOCO's architecture accelerates the prefill stage which is especially effective with long-context models.
The experiments show that YOCO delivers robust language modeling capabilities with better inference efficiency. The model has been scaled up to trillions of training tokens, matching the performance of leading Transformer models and maintaining competitive results across a broad range of model sizes and context lengths.

The authors released their implementation:
GitHub: microsoft/unilm/tree/master/YOCO
Large Language Models are Inconsistent and Biased Evaluators
In this paper, the authors examine the biases and consistency of LLM evaluators. They discover that LLM evaluators show a familiarity bias, preferring texts that are more familiar, i.e., close to text seen during training, evidenced by a decreasing trend in average perplexity with higher evaluation scores.
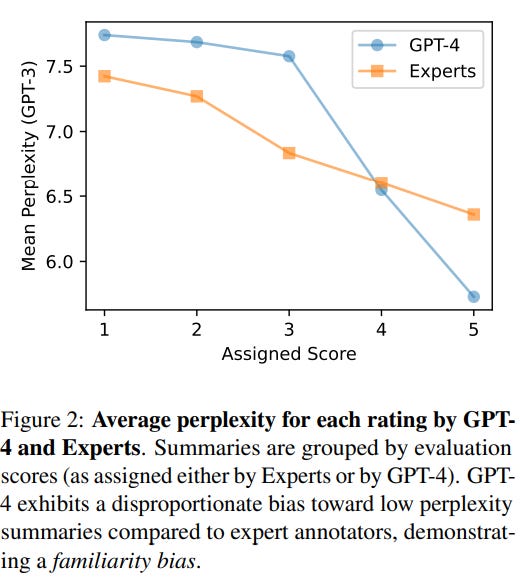
Additionally, they identify specific biases in scoring, such as the tendency to favor round numbers and the anchoring effect when multiple labels are predicted simultaneously.
The LLM evaluators also demonstrate lower consistency across different samples compared to human experts, with significant variations in judgments depending on prompt configurations.
The authors propose a new LLM evaluator using insights from their analysis, which significantly outperformed existing models on the RoSE dataset in text summarization tasks.
⭐Fishing for Magikarp: Automatically Detecting Under-trained Tokens in Large Language Models
Recent research has proposed methods that eliminate the need for tokenization by adopting raw byte inputs. Although this approach can slow down inference speeds, it can be balanced by designing specialized architectures for the initial and final layers or by varying the computational effort in the intermediate layers. However, these methods have not seen widespread adoption, and most current models still rely on standard BPE tokenization.
Despite its common use, tokenization has been largely deemed unsatisfactory due to its contribution to many undesirable behaviors and problems in LLMs. A particular issue is the misalignment between tokenizer and model training, which may result in certain tokens being rarely or never seen during training. These 'under-trained' or 'untrained' tokens—terms reserved for tokens with no occurrences in training data—can cause unexpected model behavior such as hallucinations or the production of incoherent outputs, earning them the label 'glitch tokens'.
These glitch tokens take up valuable space in a fixed-size tokenizer, which could be better allocated to more frequently used tokens, thereby reducing input/output length and inference costs. Their unintentional or intentional inclusion in input data can lead to undesirable outputs and disrupt downstream applications.
In this study, the authors introduce effective methods for detecting problematic tokens using model (un)embedding weights and tokenizer configurations. These techniques have been applied to a variety of both well-known and newer open-weight models such as Cohere Command R, Google Gemma, Meta Llama 2, Mistral, Alibaba Qwen, and OpenAI GPT-2.
The proposed method is a three-step process. First, it analyzes the tokenizer by examining its vocabulary and assessing its encoding and decoding behavior. Following this, it computes various indicators to pinpoint tokens that likely went unseen during model training. Finally, it confirms whether these identified tokens fall outside the model's trained distribution by prompting the target model with them.
The authors released their code:
GitHub: cohere-ai/magikarp
If you have any questions about one of these papers, write them in the comments. I will answer them.