
Efficient and Robust Prompt Compression for LLMs
The Weekly Salt #10

Reviewed this week
LLM2LLM: Boosting LLMs with Novel Iterative Data Enhancement
Reverse Training to Nurse the Reversal Curse
⭐LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression
PERL: Parameter Efficient Reinforcement Learning from Human Feedback
⭐: Papers that I particularly recommend reading.
New code repository:
I maintain a curated list of AI code repositories here:
LLM2LLM: Boosting LLMs with Novel Iterative Data Enhancement
Gathering and preparing more data for fine-tuning LLMs is expensive and time-consuming.
Recent research has shifted towards leveraging LLMs themselves to generate additional training data. This method is more effective than conventional augmentation techniques. However, applying LLM-based augmentation indiscriminately across all training data doesn't always yield optimal results, particularly because LLMs tend to perform well on simpler examples within the dataset but struggle with more complex ones.
This work by SqueezeAILab, the same lab behind SqueezeLLM, introduces LLM2LLM for data augmentation.

By fine-tuning a "student" LLM on the available dataset, assessing its performance, and focusing augmentation efforts on examples the model fails to understand, LLM2LLM selectively improves the training dataset. This process involves generating additional data points for the incorrectly answered examples and reintegrating them into the training set.

Their evaluation shows improvements, especially in scenarios where training data are scarce.

They released their framework here:
GitHub: SqueezeAILab/LLM2LLM
Reverse Training to Nurse the Reversal Curse
In recent studies, researchers have identified an important limitation in LLM, known as the reversal curse: Even advanced LLMs struggle with reversing facts they have learned. For instance, these models fail to recognize that if "Paris is the capital of France" is true, then "The capital of France is Paris" should also be considered true, unless specifically trained on examples phrased in this reverse manner.
This issue underscores a significant gap between LLMs and human cognitive abilities, as humans can easily grasp such reversible relationships from minimal examples. The challenge is exacerbated by the nature of training data, which, due to Zipf's law, often includes common facts in both directions but may lack rare or less frequently mentioned information in this dual format.
To address this, the paper proposes a training method to overcome the reversal curse by incorporating reverse-direction training. This approach involves training LLMs not only in the traditional left-to-right manner but also from right-to-left, allowing the models to learn information in both directions. The researchers introduce four types of reversal training - token reversal, word reversal, entity-preserving reversal, and random segment reversal - and test their effectiveness across various tasks.

The findings suggest that entity-preserving and random segment reversal training can significantly reduce, and in some cases eliminate the reversal curse. Moreover, incorporating reverse training during the pre-training results in improved performance on benchmark tasks compared to traditional single-direction training.
LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression
In this paper, the authors address task-agnostic prompt compression. They introduce a data distillation method that leverages knowledge from an LLM (GPT-4) to compress prompts without omitting important information. This includes the creation of an extractive text compression dataset featuring pairs of original texts from MeetingBank (Hu et al., 2023) and their compressed forms, which they released.
GitHub: microsoft/LLMLingua
They treat prompt compression as a token classification task, deciding whether to keep or remove each token based on the predicted probability of it being essential. This method has three main advantages:
It relies on a Transformer encoder to fully capture necessary information from the bidirectional context for compression.
It reduces latency by employing smaller models trained specifically on compression.
It ensures the compressed prompts remain true to the original content.
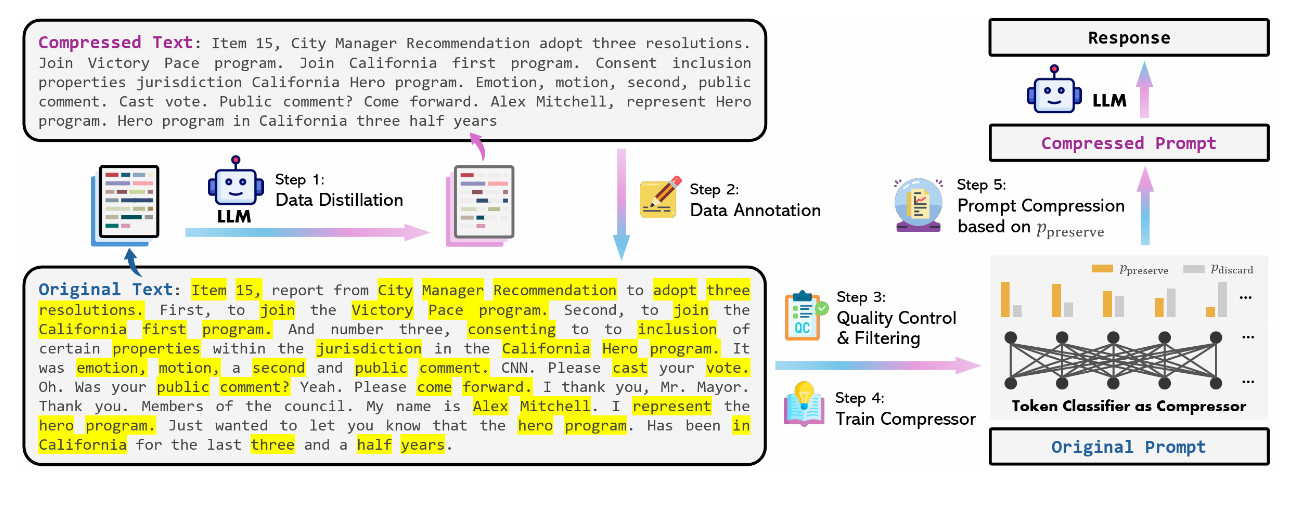
Their method shows significant performance improvements over previous work and a robust ability to generalize across different models from GPT-3.5-Turbo to Mistral-7B. Moreover, their model operates 3 to 6 times faster than existing methods for prompt compression, reducing end-to-end latency by 1.6 to 2.9 times, and achieving compression ratios between 2 to 5 times.
PERL: Parameter Efficient Reinforcement Learning from Human Feedback
RLHF demands significantly more memory than standard fine-tuning techniques due to the necessity of running multiple LLMs, including a reward model and an anchor model for Kullback–Leibler (KL) regularization. Additionally, gathering sufficient high-quality data to train an effective reward model poses another challenge.
This study by Google Research explores the potential of Parameter Efficient Fine-Tuning (PEFT) methods to make RLHF more accessible. It introduces a comparison between traditional RLHF, where all parameters of the reward model and policy undergo fine-tuning, and a more efficient approach that they named Parameter Efficient Reinforcement Learning (PERL). PERL applies a specific PEFT technique, LoRA, for fine-tuning both the reward model and an RL Policy.

This is what I have done in this article, several months ago, using DeepSpeed Chat:

The paper empirically validates that PEFT methods perform on par with full fine-tuning.
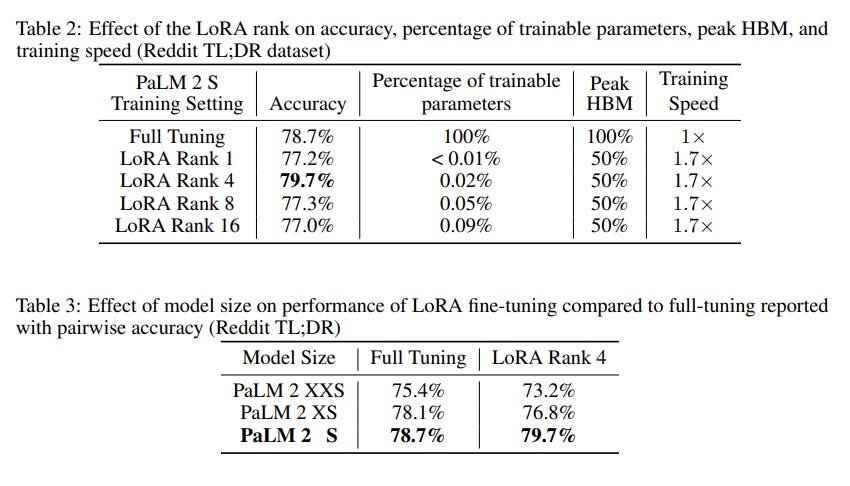
If you need to do RLHF, using LoRA is enough for both the reward and policy models.
If you have any questions about one of these papers, write them in the comments. I will answer them.