
Efficient Exploration, Reasoning, and Training-Free MTP
The Weekly Salt #113


This week, we review:
⭐Efficient Exploration at Scale
Efficient Reasoning with Balanced Thinking
Efficient Training-Free Multi-Token Prediction via Embedding-Space Probing
The week of “efficiency,” it seems.
⭐Efficient Exploration at Scale
The paper proposes an online RLHF pipeline that updates the reward model and policy incrementally as preference data arrives, instead of collecting a fixed batch and retraining offline. The core idea is to combine on-policy data collection with uncertainty-aware query selection: they keep a point-estimate reward model for training the policy, add an epistemic neural network head to model reward uncertainty, and choose response pairs for labeling by maximizing the variance of predicted choice probabilities across ensemble particles.
A smaller but important detail is the “affirmative nudge,” a constant positive offset in the policy update that is introduced to avoid the training collapse they say appears in prior online RLHF variants.
Empirically, the comparison is against offline RLHF, periodic RLHF, and a simpler online RLHF baseline, all built on Gemma 9B. Feedback is not from humans but from a Gemini 1.5 Pro–based preference simulator trained on human data, using about 200K training prompts and win rate against the SFT baseline as the main metric. In that setup, the uncertainty-guided method reaches roughly the same win rate at about 20K choices that offline RLHF reaches only after more than 200K choices, while plain online RLHF and periodic RLHF help but do not close the gap. The paper’s main contribution is therefore not a new preference objective so much as a systems-level argument that RLHF becomes much more label-efficient when reward learning, policy improvement, and exploration are all kept online.
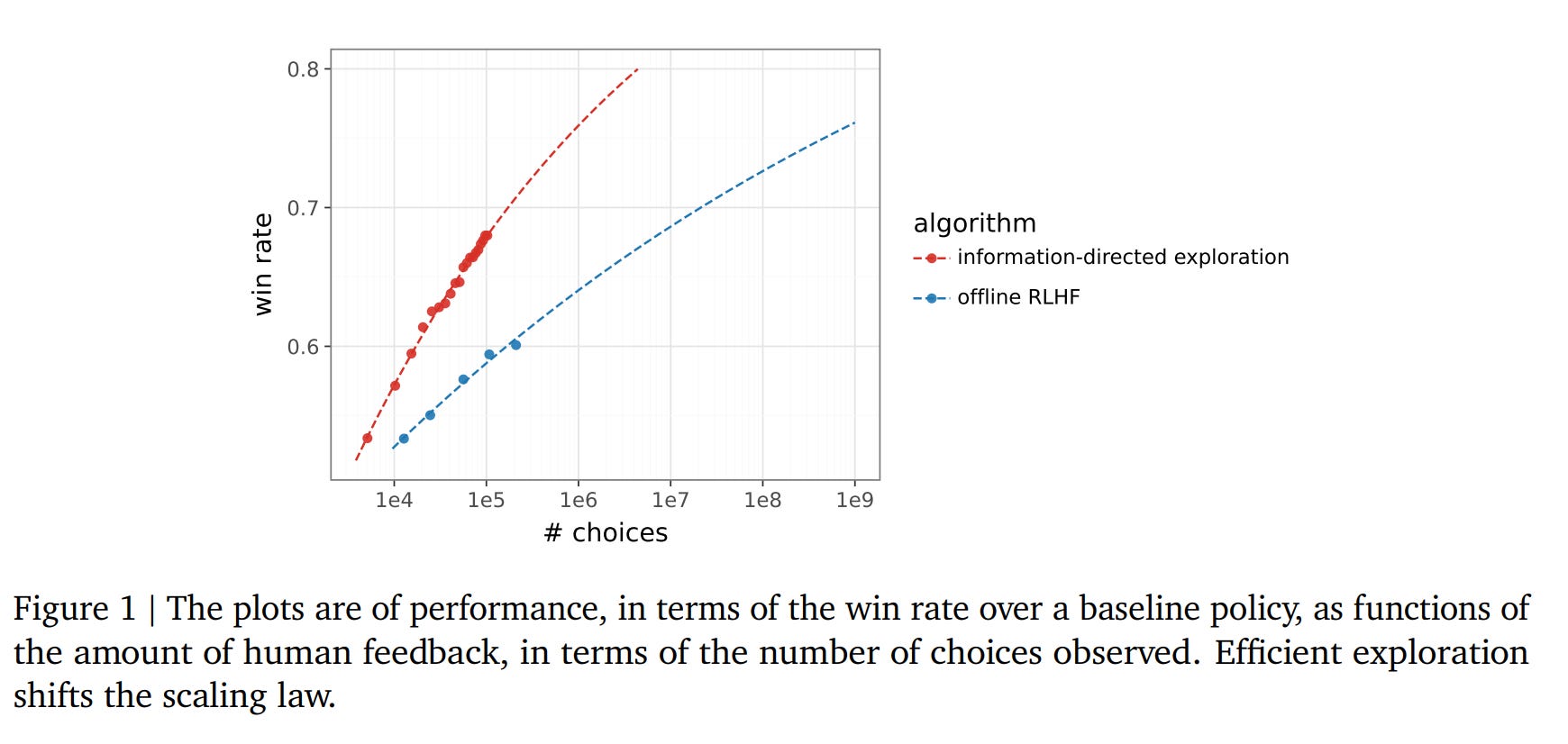
What seems most solid here is the local claim: online, uncertainty-guided exploration materially improves data efficiency in their simulator. The broader scaling claim should be read more carefully. The headline 1,000x figure is not measured directly; it comes from extrapolating fitted curves, and the entire study depends on a single simulator-based evaluation loop rather than fresh human labels.
So the paper is strongest as evidence that RLHF data efficiency is being bottlenecked by exploration and update schedules, and weaker as evidence that the same scaling law will survive real annotators, different prompt mixes, or stronger base models.
Efficient Reasoning with Balanced Thinking
This paper presents ReBalance, a training-free test-time control method for reasoning models. Instead of trying only to shorten chain-of-thought, it treats inefficient reasoning as a balance problem between overthinking and underthinking.
The mechanism is simple in outline: use stepwise confidence and confidence variance to detect which regime the model is in, build a steering vector from hidden-state prototypes associated with those regimes, and then modulate that vector during decoding so the model trims redundant detours when it is wavering and explores more when it is prematurely confident. The steering vector and control surface are fit once per backbone from a small seen set of 500 sampled MATH problems, then reused across evaluation tasks, with no extra forward passes beyond ordinary decoding.
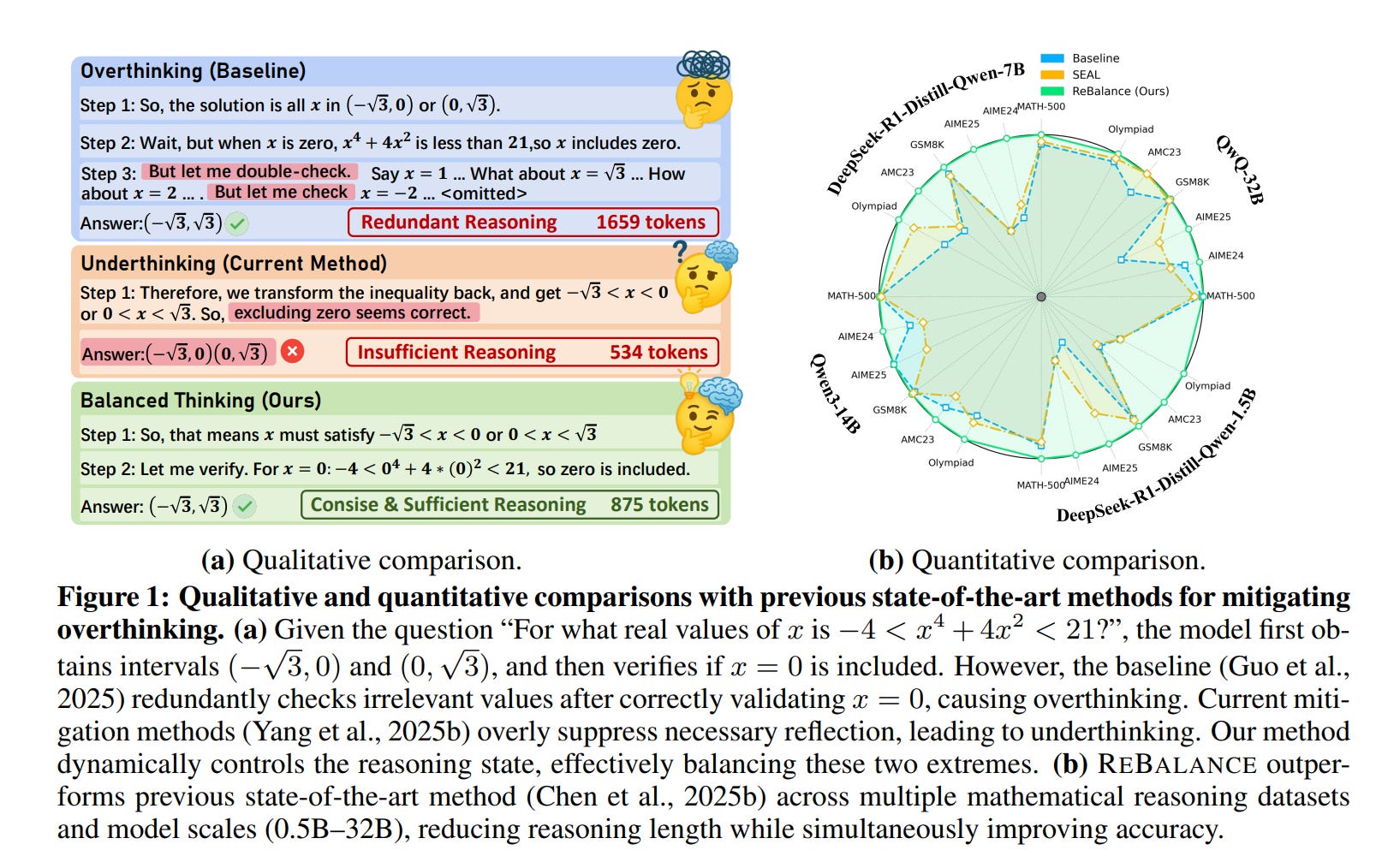
The main empirical result is that this control scheme usually improves efficiency without paying the usual accuracy tax. On six math benchmarks, the authors report gains of up to 7.0 Pass@1 points and token reductions of up to 52.3% relative to the base model. Representative examples are DeepSeek-R1-Distill-Qwen-1.5B on MATH-500, which moves from 79.6 to 83.0 while cutting tokens from 4516 to 3474, and QwQ-32B on MATH-500, which goes from 94.8 to 95.2 with tokens reduced from 4535 to 3662. The effect is not limited to math: with the same math-derived steering and control surface, the method is reported to transfer across science, commonsense, and code tasks while shortening traces by as much as 29.9%.
Efficient Training-Free Multi-Token Prediction via Embedding-Space Probing
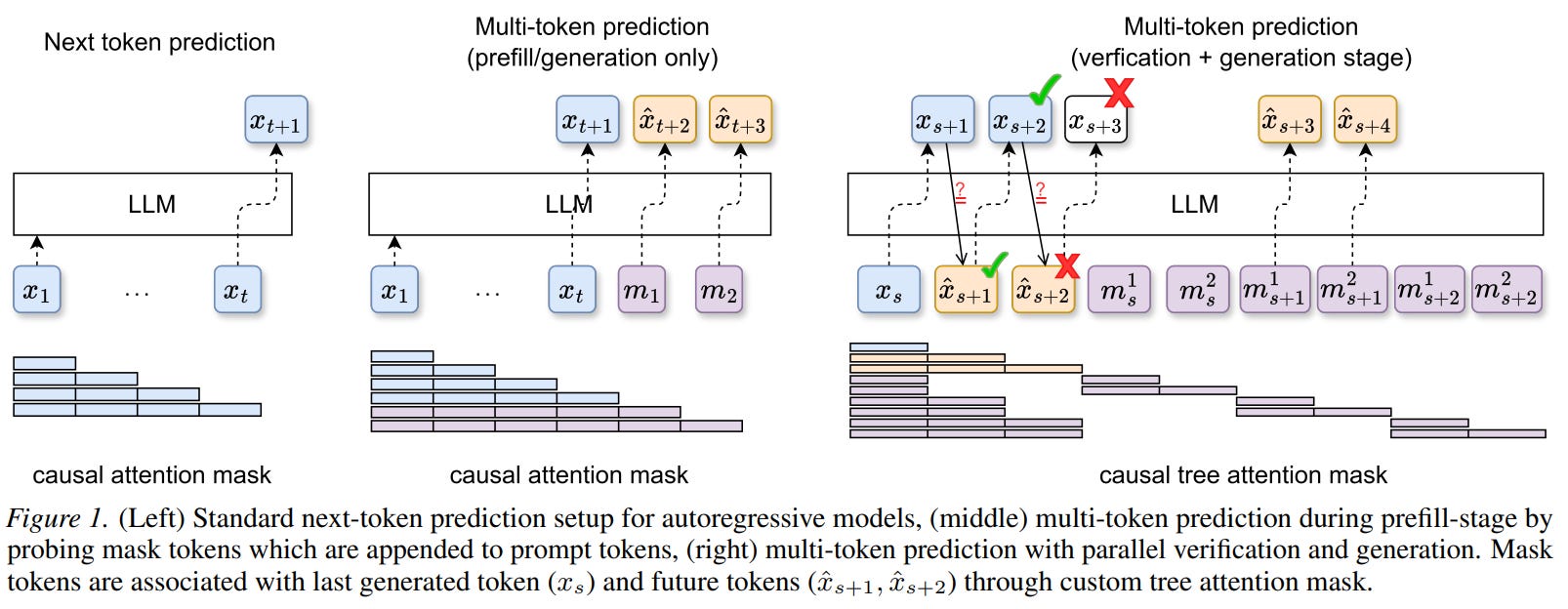
This paper is about getting multi-token decoding out of a standard autoregressive LLM without retraining it.
The method appends synthetic mask-token embeddings to the prompt, uses the frozen model to predict several future tokens in parallel, organizes those guesses into a speculative tree, then verifies them against the base model so decoding stays lossless. The interesting claim is that the model already contains enough latent structure for this to work: later decoder layers push the mask-token states toward the states of the true future tokens, and the algorithm turns that into a practical inference scheme rather than a training objective.
Empirically, the paper evaluates Llama 3 and Qwen3 models on SpecBench against other training-free baselines such as Prompt Lookup Decoding, STAND, and Lookahead Decoding.
Higher accepted-token counts per model call and higher throughput at matched block complexity, with especially clear gains on the Llama models. For example, on Llama 3.1-8B-Instruct, average accepted length rises from 1.38 to 1.62 at BC=30 and from 1.51 to 1.71 at BC=60 relative to LADE, while throughput rises from 32.6 to 38.9 and from 35.6 to 40.5 tokens per second; the method also reduces forward calls more than the baselines. The paper also argues that the right tree shape depends on task type: open-ended tasks tend to like a single, wider mask-token probe, while more constrained tasks can benefit from deeper probing with two masks.
The paper shows that frozen models can be probed more effectively than current training-free decoders assume, but it does not compare against trained multi-token systems such as auxiliary-head or draft-model methods, and some tasks still favor cache-based baselines. It is also evaluated in a fairly controlled setup: single-GPU measurements, fixed generation length, and a simplified tree policy that expands only the top path at deeper levels.