


Efficient Long Context Generalization with LongRecipe
The Weekly Salt #34


Reviewed this week:
⭐OLMoE: Open Mixture-of-Experts Language Models
LongRecipe: Recipe for Efficient Long Context Generalization in Large Language Models
Statically Contextualizing Large Language Models with Typed Holes
⭐: Papers that I particularly recommend reading.
New code repositories:
I maintain a curated list of AI code repositories here:
⭐OLMoE: Open Mixture-of-Experts Language Models
Despite significant progress in LLMs, a trade-off persists between performance and cost in both training and inference, making high-performing models inaccessible to many. One approach to address this is through sparsely activated Mixture-of-Experts (MoEs), which activate only a subset of expert subnetworks at a time, offering greater efficiency compared to dense models that activate all parameters for every input.
Although MoEs are currently very used and studied, especially since the release Mixtral, most remain closed-source, with limited information available about their training data, code, or design. This lack of openness hinders the development of cost-efficient, open MoEs that can compete with closed-source models.
The authors introduce OLMOE, a fully open Mixture-of-Experts language model. OLMOE-1B-7B, with 6.9 billion total parameters (1.3 billion of which are activated per input), achieves state-of-the-art performance among similarly-sized models while maintaining a low inference cost comparable to dense models with around 1 billion parameters.

Experiments show that MoEs train approximately twice as fast as dense models with the same number of active parameters. OLMOE-1B-7B significantly outperforms all open 1-billion-parameter models and performs competitively against larger dense models with higher costs. The post-trained version, OLMOE-1B-7B-INSTRUCT, outperforms several larger instruct models on standard benchmarks.
The paper also explores key design choices for MoEs, such as the importance of fine-grained routing with small, specialized experts, and demonstrates that token-based routing outperforms expert-based routing. Their findings also challenge previous work. They point out the ineffectiveness of shared experts and show that sparsely converting a dense model into an MoE is only beneficial under small compute budgets.
The authors released all the resources used to make OLMoE, here:
GitHub: allenai/OLMoE
LongRecipe: Recipe for Efficient Long Context Generalization in Large Language Models
The paper discusses the challenge of extending the context window in LLMs, which often results in a significant increase in computational and memory costs. While previous methods like continued pre-training or fine-tuning can expand the context window, they are resource-intensive. Some techniques, such as PI, Yarn, and LongLoRA, offer more efficient ways to extend the context window, but they still require full-length fine-tuning, making the process costly in both time and memory. Other approaches, such as Randomized Positional Encoding and PoSE, simulate longer inputs within a fixed window, but these methods disrupt local sentence structures and fail to capture longer dependencies accurately.
To address these issues, the authors present LongRecipe, an efficient framework designed to improve LLMs' ability to handle long contexts.
LongRecipe optimizes the learning process by analyzing impactful tokens and applying Position Index Transformation. This allows the model to simulate long-sequence training using shorter texts. The framework also includes training optimizations like pretraining data replay and model merging to improve long-text processing capabilities.
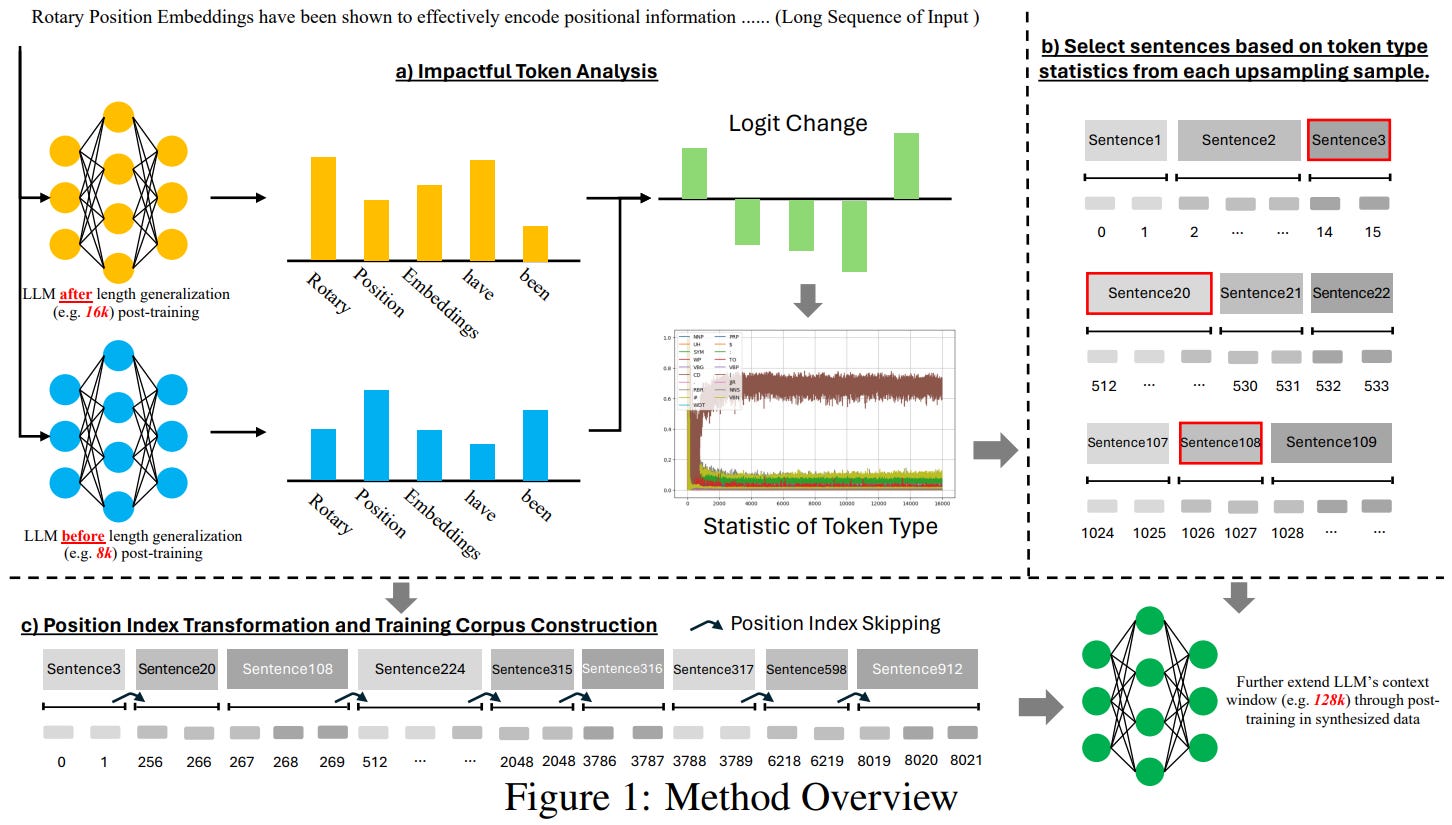
Empirical evaluations using various models and benchmarks demonstrate that LongRecipe extends context windows from 8k or 32k to 80k or 128k, achieving significant improvements in performance while using fewer computational resources. The results show that the framework improves long-context generalization by approximately 5.5% on average, with training efficiency significantly enhanced, achieving similar performance as full context window training with fewer tokens and less GPU power. Additionally, LongRecipe largely preserves the models' general abilities in other tasks.
The authors released their code, here:
GitHub: zhiyuanhubj/LongRecipe
Statically Contextualizing Large Language Models with Typed Holes
Recent advances in generative AI have led to a surge in AI programming assistants, with Copilot being one of the most prominent. These assistants generate code completions by prompting LLMs that are pre-trained on a diverse corpus of both natural language and code from various programming languages.

Once trained, LLMs transform input sequences, or prompts, into next-token probability distributions, allowing them to predict and complete code. As these models scale, limited reasoning abilities emerge, making them powerful enough to boost developer productivity significantly. However, this impact is more pronounced for developers working with well-represented libraries and languages in the training data.
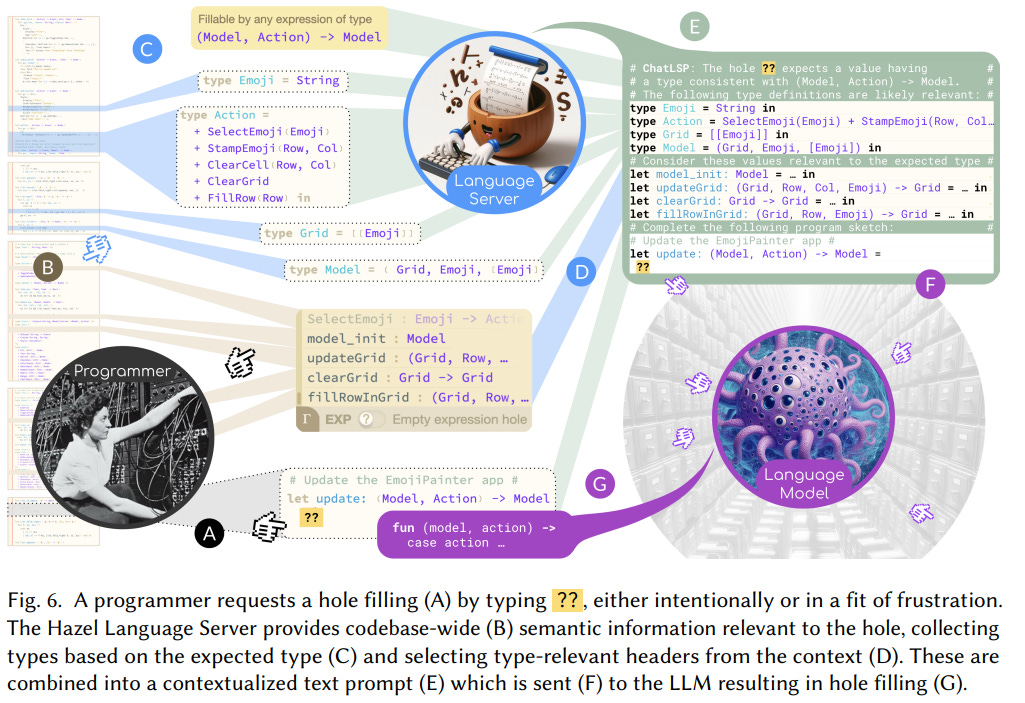
Most AI programming assistants rely on the "cursor window" method, using the program text immediately around the developer’s cursor to construct prompts. This leads to poor performance when critical context comes from definitions not present in the cursor window or the LLM's training data, a problem known as "semantic contextualization." For example, if a developer is implementing a function that requires knowing the definitions of types in other files, such as `Model` and `Action`, the LLM might either fail to generate completions or hallucinate plausible but incorrect code.
To overcome this issue, designers use retrieval-augmented generation (RAG) techniques to fetch relevant code from other files in the repository. However, real-world codebases can span hundreds of thousands of lines, leading to scaling problems, as larger prompts increase both generation time and energy consumption. While prompt size limits are growing, LLMs still struggle to differentiate between relevant and irrelevant information within large prompts, and maintaining token efficiency is crucial.
The paper investigates two language-aware approaches to improve LLM code completion. The first is static retrieval, where a language server determines the type and context of a "hole" at the cursor and retrieves relevant type definitions and function headers from other parts of the codebase. This approach allows the model to gather information about types like `Model` and `Action`, along with related helper functions. The second approach, static error correction, combines static retrieval with error-checking by having the language server identify syntactic and static errors in generated code, which are then corrected through iterative feedback loops to improve the accuracy of completions.
If you have any questions about one of these papers, write them in the comments. I will answer them.
Thanks BENJAMIN.
But I've been wondering since it seems that their experiments are mostly based on completion tasks. In theory, could these methods (context length extension methods such as LongRecipe, YARN and more) also apply to instruction finetuning rather than just completion tasks?