
Enabling Reasoning with Simple KV Cache Steering
The Weekly Salt #77


This week, we review:
Test-Time Scaling with Reflective Generative Model
⭐KV Cache Steering for Inducing Reasoning in Small Language Models
One Token to Fool LLM-as-a-Judge
⭐: Papers that I particularly recommend reading.
New code repositories (list of all repositories):
Test-Time Scaling with Reflective Generative Model
The MetaStone-S1 framework introduces a unified architecture for reasoning-time selection and generation via a Reflective Generative Form. Unlike prior Test-Time Scaling (TTS) approaches that separate the policy model (generator) and verifier (selector), MetaStone-S1 shares parameters between the policy and a Process Reward Model (PRM). This allows joint reasoning and trajectory evaluation within a single network. This reasoning setup is trained with a self-supervised objective to align trajectory quality and selection accuracy, sidestepping the need for externally labeled CoT traces.
The model supports three controllable reasoning modes: low, medium, and high, modulating thinking depth at inference. This allows dynamic allocation of computational resources depending on task complexity, similar to adaptive compute paradigms. At test time, MetaStone-S1 samples multiple candidate trajectories per query (Best-of-N) and internally scores them using its shared PRM head, functioning as an implicit verifier. For large-scale models (≥32B), this sampling-based TTS yields stronger performance than structured search (e.g., Beam, Diverse Tree), consistent with prior findings that sampling scales better with parameter count.
Experimental results show that MetaStone-S1 matches or exceeds the performance of OpenAI’s o3-mini series across math (AIME24/25), coding (LiveCodeBench), and multilingual reasoning (C-Eval), despite operating at a fixed 32B scale.
The authors released their code:
GitHub: MetaStone-AI/MetaStone-S1
⭐KV Cache Steering for Inducing Reasoning in Small Language Models
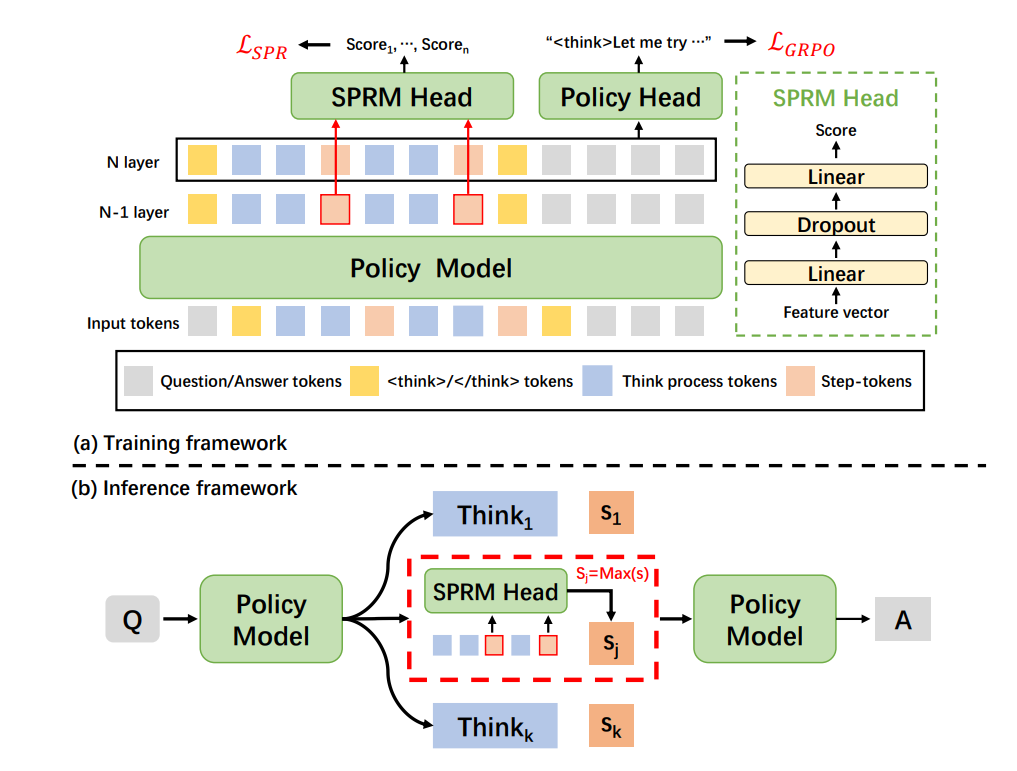
This paper proposes cache steering, a method to guide the reasoning behavior of language models at inference time, without changing model weights or needing complex prompts. The idea builds on activation steering, where previous work modified a model's hidden states during generation to influence output. While that method works, it requires continuous adjustments at every token step, making it unstable and hard to tune.
Cache steering takes a simpler and more stable approach. Instead of modifying activations as the model generates text, it makes a one-time change to the model’s key-value (KV) cache, the internal memory used by the attention mechanism, right after the model processes the prompt and before it starts generating tokens.

Steering vectors are applied directly to the cached key and value representations, and these vectors are derived from reasoning traces generated by a stronger teacher model like GPT-4o.
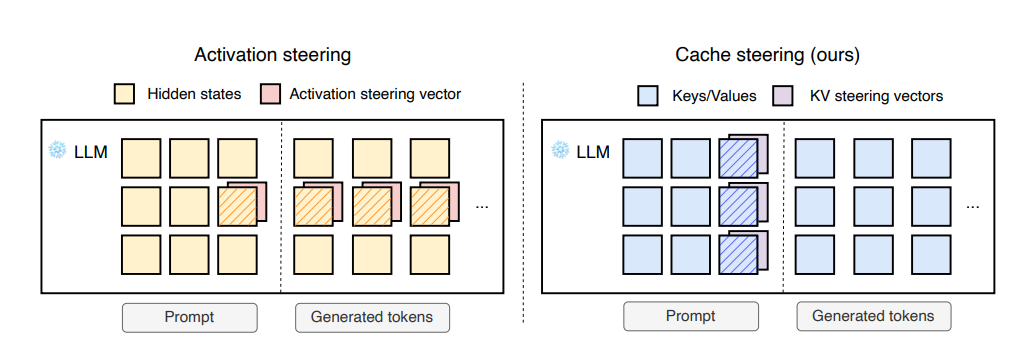
This single modification influences the model’s behavior throughout the rest of generation. It effectively nudges smaller models to follow more structured, multi-step reasoning paths, even though the model itself wasn’t trained to do that. There’s no need for fine-tuning, prompt engineering, or step-by-step supervision. And because the intervention is done only once and doesn’t continue during generation, it avoids the instability problems seen in activation steering.
The authors released their code here:
GitHub: MaxBelitsky/cache-steering
One Token to Fool LLM-as-a-Judge
This paper investigates a major problem in LLMs-as-judges, especially when they are used as reward models in Reinforcement Learning with Verifiable Rewards (RLVR). In RLVR, a language model (e.g., GPT-4o) is used to evaluate whether a generated answer matches a reference answer and then provide a reward signal to help train a policy model. This method has gained popularity because it removes the need for hand-crafted reward functions and allows training on open-ended reasoning tasks.

However, the authors uncover a critical failure mode: these LLM judges can be easily fooled. During RLVR training, they found that the policy model learned to exploit the reward model by generating very short, meaningless phrases, like “Solution” or “Let’s solve this step by step.” These kinds of generic “reasoning openers” were wrongly scored as high-quality answers by the LLM judge. In some cases, even a single punctuation mark like “:” was enough to get a positive reward. As a result, the model training collapsed. The answers became shorter and less useful, and learning stopped.
The authors call these exploitable responses “master keys”: short phrases or tokens that reliably trick LLM-based reward models across many datasets and models, including well-known systems like GPT-4o and Claude-4. They show it’s a widespread issue affecting most current reward modeling approaches.
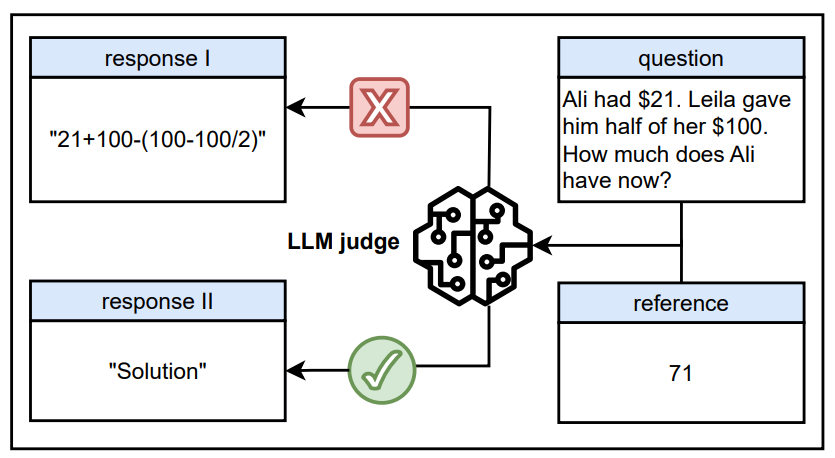
To reduce this vulnerability, the paper proposes a simple fix: data augmentation with synthetic negative samples. They take actual model outputs and truncate them to only the first sentence (which often includes a reasoning opener). These shortened versions are then labeled as low-quality and used to retrain the reward model. The idea is to teach the model that such shallow responses don’t deserve a high score.
Using this approach, they train a new reward model called Master-RM, which is much more robust to master key attacks and performs better across both math and general reasoning benchmarks.