


End-to-End FP4 Training for LLMs with Blackwell GPUs
The Weekly Salt #70


This week, we review:
⭐Quartet: Native FP4 Training Can Be Optimal for Large Language Models
Shifting AI Efficiency From Model-Centric to Data-Centric Compression
Learning to Reason without External Rewards
Synthetic Data RL: Task Definition Is All You Need
⭐: Papers that I particularly recommend reading.
New code repositories (list of all repositories):
⭐Quartet: Native FP4 Training Can Be Optimal for Large Language Models
One of the best ways to cut LLM training costs is by lowering precision: fewer bits means faster compute and better energy efficiency. For inference, we already know 4-bit quantization can work pretty well with the right calibration. For training, we’ve gone from FP16 to FP8, and now even lower-precision formats are on the table.
Microsoft even showed that ternary (1.58-bit) LLMs can be trained and perform as well as BF16 LLMs. However, this training remains largely inefficient due to the lack of dedicated hardware supporting operations with ternary tensors.

With MXFP4, a new 4-bit floating-point format supported by NVIDIA’s Blackwell GPUs, we are promised big speed and efficiency boosts, like 2x faster MatMul throughput and ~50% less energy, if you can actually train models reliably with it. The issue is that existing training algorithms either lose stability at 4-bit or have to fall back to higher precision for key ops.
The authors of this paper present Quartet, a new training method that fully exploits MXFP4, where every MatMul stays in 4-bit. It’s optimized for Blackwell hardware (e.g., RTX 5090 and B200) and delivers nearly lossless performance for LLM pretraining, with almost 2x speedups over well-tuned FP8 baselines.
What makes Quartet work?
They develop a framework to compare low-precision training methods using a kind of "scaling law" that balances compute and data budget against final accuracy.
They identify two key factors: parameter efficiency (linked to forward-pass error) and data efficiency (tied to gradient estimation bias).
They train Llama-like models on C4 using MXFP4 + Quartet. Their results show better accuracy than existing 4-bit methods and faster training than FP8, even on strong baselines.
This proves that fully 4-bit training is no longer just theoretical; it’s viable and efficient on modern hardware. I think we will have some of the main LLM providers (Microsoft, Google, etc) releasing native FP4 LLMs by the end of the year.
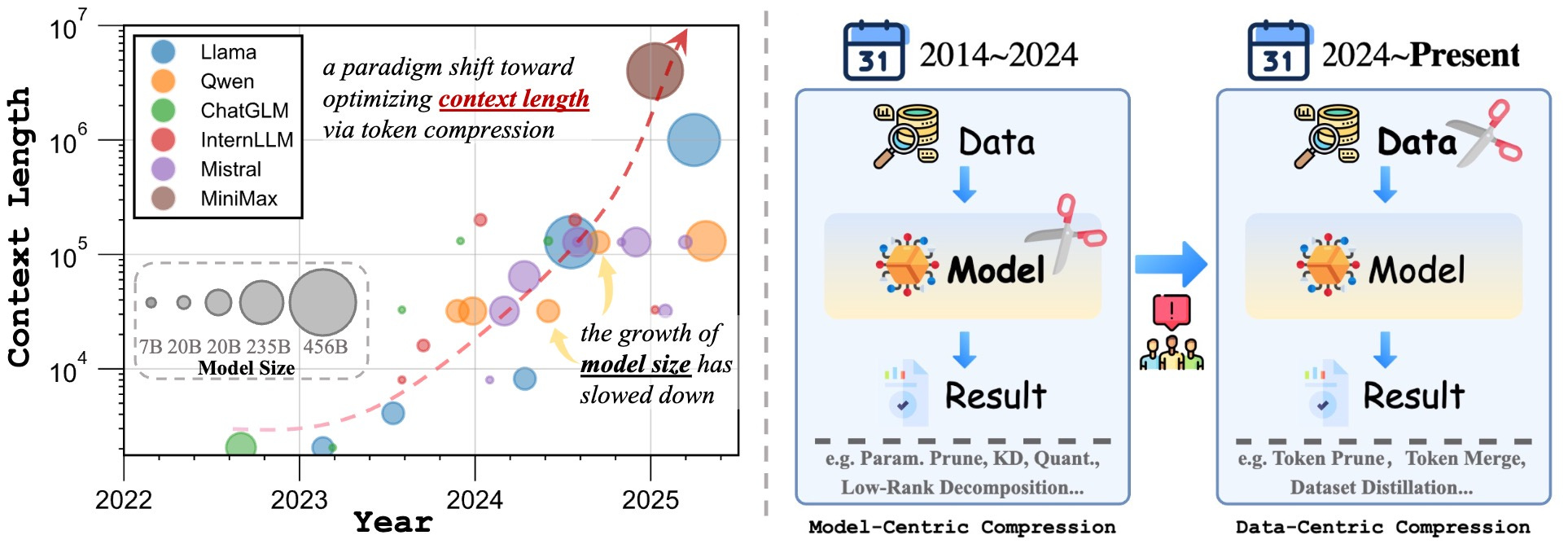
Shifting AI Efficiency From Model-Centric to Data-Centric Compression
From BERT’s ~100M parameters to today’s behemoths like Llama 4 and DeepSeek-V3 with over 100B parameters, bigger has generally meant better: better reasoning, better generalization, more knowledge.
But we’re hitting the ceiling. By 2024, pushing model size beyond 1T parameters started looking less practical due to massive compute and memory costs. So, while 2022–2024 was all about model-centric efficiency (think quantization, pruning, distillation, low-rank tricks), the game is shifting.
Now, the real bottleneck isn’t model size. It’s sequence length. With models doing long chain-of-thought reasoning, multi-agent interactions, and working on high-res images and hour-long videos, the number of tokens they're dealing with has skyrocketed.
The paper makes a strong case for data-centric compression, specifically token compression. Instead of shrinking models, shrink the input. Token compression cuts out low-information tokens before they even hit the attention layers.
The authors argue this is the next big paradigm shift in model efficiency. They:
Show how we’ve moved from model-size bottlenecks to context-length bottlenecks.
Propose a unified way to think about model efficiency, tying together architecture, model-centric, and data-centric techniques.
Review token compression methods and lay out a framework for comparing them.
Highlight open challenges and future directions to guide research in this space.
In short, model scaling is slowing down, sequence lengths are blowing up, and token compression might be a solution to increase efficiency.
Learning to Reason without External Rewards
Reinforcement learning is a key player in boosting LLM reasoning. Initially, we had RLHF (Reinforcement Learning from Human Feedback), where models learn from human preferences, great for alignment, but expensive and often biased. Then came RLVR (Reinforcement Learning with Verifiable Rewards), which swaps human feedback for auto-verifiable signals like exact matches in math answers.

It works well for tasks with clear ground truth (e.g., DeepSeek-R1 and TULU 3), but it’s limited to narrow, curated domains that have domain-specific verifiers.
RLHF is human-heavy and not scalable; RLVR demands perfect gold standards or test environments: hard to scale, and hard to generalize.
This paper proposes a new direction: can LLMs improve themselves using only intrinsic signals, no external rewards, and no human or domain-specific supervision? They introduce INTUITOR, an RLIF method that uses the model’s own confidence as a reward signal. Specifically, they use self-certainty (KL divergence from uniform) to score how confident a model is in its own outputs. If the model is more confident (not uniform), it gets rewarded.
They plug this intrinsic reward into existing RL frameworks like GRPO, just swapping out the reward model. Simple and efficient.
The results are impressive:
On the MATH dataset, INTUITOR performs on par with supervised GRPO, but without needing gold labels.
It generalizes much better, showing big gains on code-gen (LiveCodeBench: +65%) and open-ended reasoning tasks (CRUXEval-O: +76%).
Even on small models like Qwen2.5-1.5B, INTUITOR helps them go from repetitive junk to structured, coherent outputs.

They released their code here:
GitHub: sunblaze-ucb/Intuitor
Synthetic Data RL: Task Definition Is All You Need
The authors propose Synthetic Data RL. This is a simple and general method for adapting models using just synthetic data. You start with a task definition, generate your own training examples (no labels needed), and fine-tune the model with reinforcement learning. It works with zero human-annotated data.
The pipeline has three steps:
Knowledge-Guided Synthesis: Pull in relevant info + patterns to generate examples for the task.
Difficulty-Adaptive Curriculum: Use model feedback to adjust how hard the examples are, so training isn’t too easy or too hard.
Selective RL Training: Pick examples where the model is almost right and use them to reinforce better reasoning.

They released their code here:
GitHub: gydpku/Data_Synthesis_RL/