
Flow-Based Token Credit for Reasoning RL
The Weekly Salt #120


This week, we review:
⭐How Does Reasoning Flow? Tracing Attention-Induced Information Flow for Targeted RL in LLMs
Dynamic Linear Attention
Compress-Distill: Reasoning Trace Compression for Efficient Knowledge Distillation
⭐How Does Reasoning Flow? Tracing Attention-Induced Information Flow for Targeted RL in LLMs
The paper introduces FlowTracer, a token-level credit assignment method for reinforcement learning on LLM reasoning tasks. The problem it targets is that RLVR and GRPO-style training usually apply outcome rewards broadly across generated tokens, even though only some tokens materially affect the final answer. FlowTracer instead uses the model’s own attention structure to estimate which generated tokens route information from the prompt toward the answer region. It represents the sequence as a token graph, derives directed edge strengths from aggregated attention, conditions the graph on the final answer span, and suppresses attention paths that do not reach that answer region.
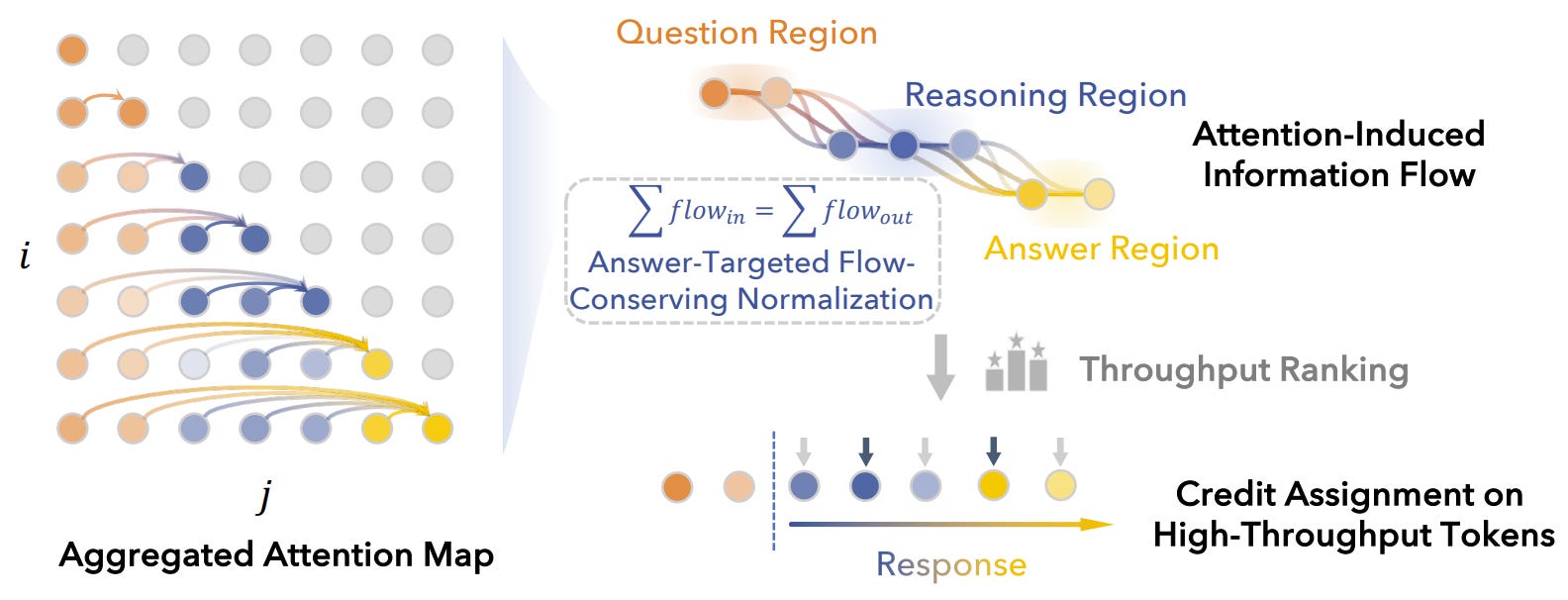
Technically, the method converts raw attention into an answer-targeted flow graph. Raw attention is treated as a local token-to-token interaction signal, but the authors argue that it is insufficient by itself because many attention paths end in irrelevant branches or overemphasize tokens near the answer. FlowTracer reweights the graph so that effective influence is conserved through intermediate tokens and only answer-reaching paths are retained. It then propagates flow from question tokens to answer tokens and scores each token by throughput, treating high-throughput tokens as routing hubs in the reasoning trace.
The authors use these throughput scores to modify GRPO training. After response sampling, they run one extra forward pass to extract middle-layer attention maps, compute flow scores, select the top 40% high-flow tokens, and give those tokens a larger policy-update weight. In their implementation, the high-flow token multiplier is fixed at 1.5. Their qualitative and intervention analyses suggest that high-flow tokens often include structural delimiters, repeated symbols, variables, punctuation, or aggregation points rather than ordinary fluent filler. When they mask attention from the top 20% high-flow tokens on GSM8K, outputs change more often than when masking random or low-flow tokens, supporting the claim that the selected tokens have stronger causal influence on the final answer.
Experiments compare FlowTracer with GRPO and token-prioritization heuristics based on random selection, entropy, gradients, correlation, and attention scores. The main evaluations use Qwen3-4B and Qwen3-8B on math benchmarks including AIME24, AIME25, AMC23, MATH500, and OlympiadBench, with additional tests on Countdown and CrossThinkQA; supplementary results use Llama-3.1-8B and Llama-3.2-3B. Reported gains are consistent but moderate in most settings, with larger gains in some long-context and puzzle-solving cases. The paper also reports that middle-layer attention works better than early, late, or all-layer aggregation, that hard top-40% selection is more stable than continuous weighting, and that the added computation is about 2.1% to 4.5% per training step.
The stated limitations are that the method assumes a localized answer region, remains tied to outcome rewards, and may require adaptation for very long contexts or open-ended tool-use trajectories.
The paper proposes Dynamic Linear Attention (DLA), a memory modeling framework for long-context language models using linear attention. Its starting point is that standard self-attention has quadratic cost, while linear attention reduces cost but often compresses too much history into a limited state representation.
The authors focus on multi-state linear attention, where past tokens are summarized into multiple memory states, and argue that prior methods such as Log-Linear Attention use fixed merging schedules that do not adapt to uneven information density across a sequence. This can merge semantically important transitions into coarse summaries too early and accumulate errors over long contexts.
DLA replaces fixed state construction with information-aware dynamic state merging. For each incoming token representation, the method computes a lightweight score measuring how much it differs from the most recent memory state. Tokens with low variation are merged into the current state, while tokens with larger representational drift start a new state. The intended effect is to keep finer resolution around semantic changes and compress locally redundant spans more aggressively. The paper’s analysis frames this as reducing within-block heterogeneity during summarization, which is the main source of approximation error in blockwise memory compression.

The second component is capacity-bounded memory modeling. DLA maintains a chronological cache of memory states with a fixed maximum size. Each state tracks both how many tokens it summarizes and an aggregate information score. When the cache reaches capacity, the method merges the adjacent pair with the lowest information density, preserving temporal order while freeing space for newer states. At decoding time, the model reads from these stored states using learned query-dependent weights, so the cache remains bounded while still allowing the model to emphasize more relevant states.
The authors evaluate DLA by pretraining variants of Mamba-2-780M and Gated DeltaNet-1.3B from scratch on 50B tokens with 16K sequence length, using the same maximum state count as Log-Linear Attention. Evaluation covers 16 datasets: commonsense reasoning, in-context retrieval, RULER, and LongBench. The reported results show that DLA improves over vanilla and Log-Linear variants on these evaluations, including gains on retrieval-heavy long-context tasks and LongBench categories such as QA, summarization, and few-shot learning. Efficiency tests on a single A100 report higher throughput and lower memory use than the Log-Linear variant, though both multi-state approaches remain heavier than vanilla Mamba-2 because they cache multiple summary states. Ablations indicate that both dynamic state merging and the bounded-memory component contribute to the final results, and that moderate changes to cache size and merge threshold have limited impact.
Compress-Distill: Reasoning Trace Compression for Efficient Knowledge Distillation
The paper studies whether long teacher reasoning traces can be compressed before supervised knowledge distillation to reduce training and inference cost.
The proposed Compress-Distill pipeline first generates verified-correct reasoning traces from large teacher models, then rewrites those traces with separate instruction-tuned compressor models, and finally fine-tunes student models on either raw traces, compressed traces, or answer-only outputs. The two teachers are Qwen3.5-397B-A17B and gpt-oss-120B; the compressors are Llama-3.3-70B-Instruct and Ministral-3-14B-Instruct-2512. The authors report about 283k correct traces per teacher, with compressed traces reduced to 8.6–21.0% of original character length depending on teacher and compressor.
Experimentally, the study covers two teachers, four student models, LoRA and full fine-tuning, raw and compressed trace sources, answer-only ablations, and additional length-matched truncation ablations. The students include Qwen3.5-0.8B-Base, Qwen3.5-9B-Base, Llama-3.1-8B, and gpt-oss-20B. Training uses next-token prediction on assistant tokens, sample packing, BF16, FlashAttention 2, and a one-epoch setup; evaluation uses greedy decoding with an 8,192-token cap across in-distribution reasoning datasets and out-of-distribution reasoning and knowledge benchmarks.
The main result is an accuracy-efficiency trade-off. Compressed traces reduce training tokens to 12–30% of raw traces, reduce wall-clock training time by 2.0–7.6x, and shorten inference outputs by roughly 3–19x, with smaller gains for the already-shorter gpt-oss teacher traces. However, raw teacher traces give the highest overall downstream accuracy in every evaluated teacher, student, and training-method configuration. For example, under full fine-tuning, Qwen3.5-9B trained from Qwen raw traces reaches 0.866 overall accuracy, compared with 0.834 for Llama-70B-compressed traces and 0.817 for Ministral-14B-compressed traces; gpt-oss-20B trained from gpt-oss raw traces reaches 0.844, compared with 0.776 and 0.767 for the two compressed variants.