
From GQA to MLA for a Better and More Memory-Efficient Attention Computation
The Weekly Salt #56


This week, we read:
⭐TransMLA: Multi-Head Latent Attention Is All You Need
Ignore the KL Penalty! Boosting Exploration on Critical Tokens to Enhance RL Fine-Tuning
BenchMAX: A Comprehensive Multilingual Evaluation Suite for Large Language Models
⭐: Papers that I particularly recommend reading.
New code repositories (list of all repositories):
TransMLA: Multi-Head Latent Attention Is All You Need
LLMs’ effectiveness comes from Next Token Prediction, where each token attends to previous ones, but as models grow, caching key-value (KV) pairs becomes a major memory bottleneck.
To address this, methods like Multi-Query Attention (MQA) and Group-Query Attention (GQA) reduce KV Cache size but sacrifice performance. Note: For GQA, this performance degradation is often minimal but mainly depends on the group size.
Techniques such as KV compression and pruning can help but often require fine-tuning to maintain accuracy. Multi-head Latent Attention (MLA), introduced in DeepSeek V2 and extended in later versions seems better though prior studies lacked theoretical proof.

This paper provides proof that MLA consistently outperforms GQA for the same KV Cache overhead. By converting GQA-based models like Llama 3, Qwen-2.5, and Mistral to MLA.
They published their code here:
GitHub: fxmeng/TransMLA
I’ll definitely try it!
Ignore the KL Penalty! Boosting Exploration on Critical Tokens to Enhance RL Fine-Tuning
Recent work has redefined LLMs as more than just text generators, viewing them instead as agents capable of achieving long-term goals. Studies have shown that LLMs can be fine-tuned with reinforcement learning (RL) to pursue objectives, even when guided by sparse success and failure signals. However, exploration remains a challenge. Pre-training helps maintain fundamental language abilities, but it can also limit a model’s ability to deviate from familiar patterns. Many LLM agents struggle to discover solutions beyond what their pre-trained models would typically generate.
This study examines how pre-training impacts a model’s ability to adapt to tasks requiring exploration. The authors use a controlled arithmetic task, first pre-training a model on simple problems and then fine-tuning it with RL on a slightly modified version. They find that performance largely depends on specific "critical tokens" where the model must diverge from its pre-trained behavior. Without sufficient flexibility, LLMs tend to process numbers as if they were the same length as those seen during pre-training, leading to systematic errors in longer sequences.
To address this issue, the authors propose a modification to the KL-divergence penalty, a common technique used to prevent excessive deviation from the pre-trained model. Instead of applying a fixed penalty, they make it dependent on the model’s token-wise confidence, allowing it to explore more freely in uncertain situations while staying grounded in areas where pre-training remains useful. This adjustment significantly improves the model’s ability to adapt to new problem distributions, enhancing its exploration efficiency without sacrificing stability.

The findings suggest that refining RL fine-tuning strategies can make LLMs more effective at solving real-world problems that require adaptability.
BenchMAX: A Comprehensive Multilingual Evaluation Suite for Large Language Models
LLMs are highly capable in tasks like reasoning, instruction following, and code generation, but their performance varies significantly across languages. Studies show inconsistencies, especially in low-resource languages. Existing benchmarks don’t fully capture these differences, often relying on multiple-choice tasks and covering a limited set of languages.
To address this, the authors developed BenchMAX, a multilingual evaluation suite that tests LLMs across 17 languages, covering diverse language families and writing systems: English, Hungarian, Vietnamese, Spanish, Czech, French, German, Russian, Bengali, Serbian, Korean, Japanese, Arabic, Thai, Swahili, Chinese, and Telugu.
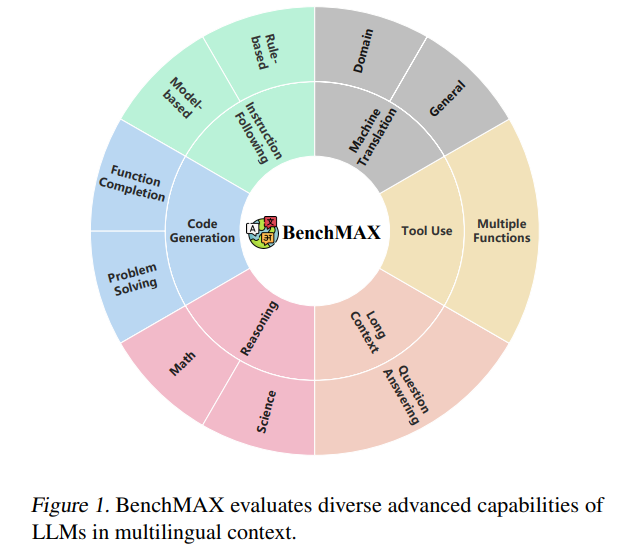
BenchMAX assesses instruction following, code generation, reasoning, tool use, long-context understanding, and domain translation. Unlike previous benchmarks, It includes a rigorous data curation process in which translations are machine-generated, refined by native speakers, and validated by LLMs to ensure accuracy.
Evaluations reveal that language significantly affects performance, and while increasing model size improves overall accuracy, it doesn’t eliminate disparities between languages. Domain translation, which requires precise terminology control, also presents challenges.

The benchmark works with the Evaluation Harness (lm_eval):
GitHub: CONE-MT/BenchMAX