


This week, we read:
⭐How to Get Your LLM to Generate Challenging Problems for Evaluation
Ignore the KL Penalty! Boosting Exploration on Critical Tokens to Enhance RL Fine-Tuning
You Do Not Fully Utilize Transformer's Representation Capacity
⭐: Papers that I particularly recommend reading.
New code repositories (list of all repositories):
⭐How to Get Your LLM to Generate Challenging Problems for Evaluation
CHASE (CHallenging AI with Synthetic Evaluations) is a new way to test LLMs by generating difficult, synthetic benchmarks. The problem with traditional evaluation methods is that models have become so good they’re acing existing tests, making it hard to tell if they’re actually improving.
Instead of just throwing out random hard questions, CHASE carefully hides parts of the solution within the problem itself, forcing models to think multiple steps ahead. This bottom-up approach means LLMs can’t just recognize a familiar pattern, they actually have to reason through it. On top of that, CHASE breaks down the problem creation process into smaller, easier-to-verify steps, ensuring that the generated problems are actually valid. This avoids one of the big pitfalls of synthetic data generation, where AI-made problems often end up being flawed or nonsensical.
To prove that CHASE works, the authors tested it in three different areas. CHASE-QA challenges LLMs with long-context question-answering, where they have to sift through multiple documents, some of which contain misleading information. CHASE-CODE tests models on writing code at a repository level, making them complete functions or algorithms based on real-world coding tasks. CHASE-MATH focuses on simple grade-school arithmetic problems, but structured in a way that requires deep reasoning rather than just memorizing common problem types. Each of these benchmarks is designed to expose weaknesses in how LLMs process and generate information.
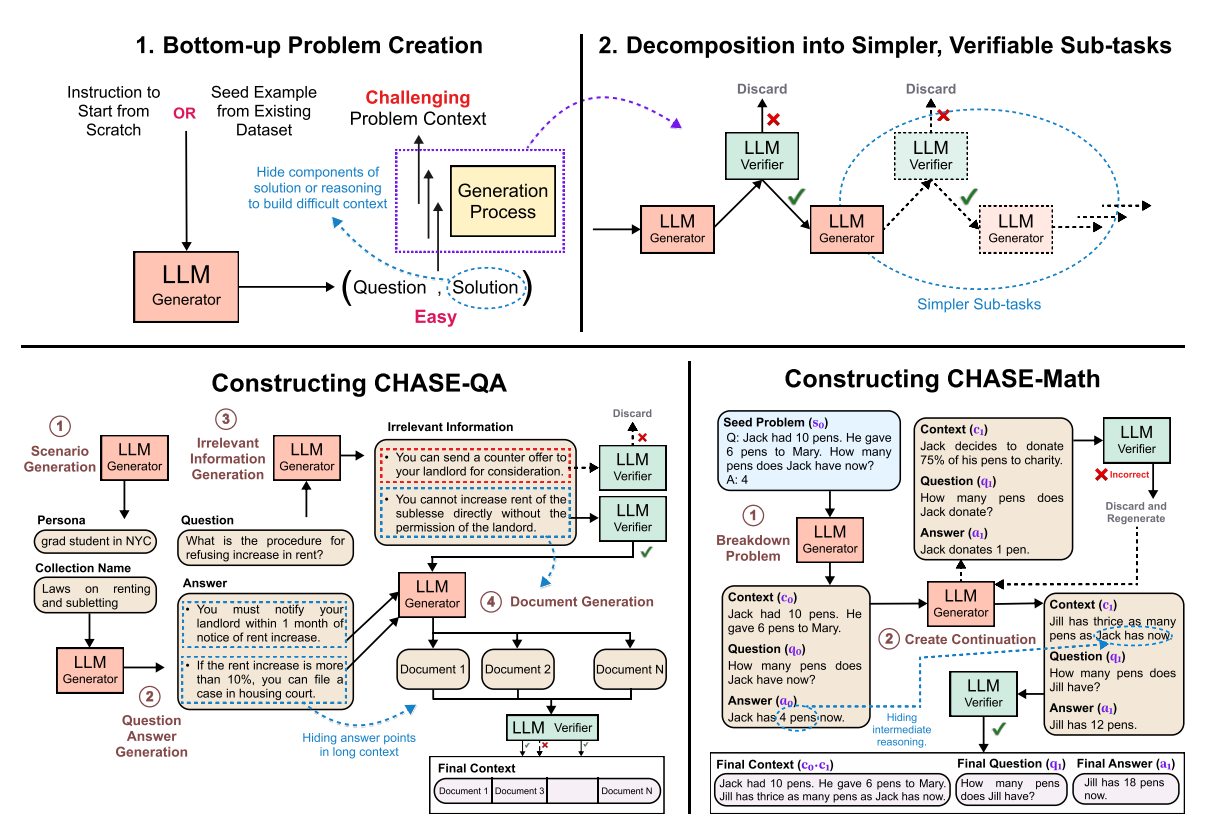
When tested on 15 state-of-the-art LLMs, CHASE proved to be way harder than existing benchmarks, with the best models only managing 40–60% accuracy. CHASE also outperformed other synthetic data generation methods, like Evol-Instruct, which often creates easier or error-prone problems. In other words, CHASE doesn’t just make problems—it makes good ones that actually challenge AI in meaningful ways.
One of the most surprising findings was how poorly LLMs handle long-context reasoning. When the input size goes over 50k tokens, accuracy drops by up to 70%, showing that even the best models struggle to keep track of information over long stretches. This is a major limitation that doesn’t show up in most benchmarks but is crucial for real-world applications, like reading long documents or analyzing large datasets.
GitHub: McGill-NLP/CHASE
Judging the Judges: A Collection of LLM-Generated Relevance Judgements
The Cranfield paradigm has been the standard method for evaluating Information Retrieval (IR) systems since the 1960s. It requires three key components: a document corpus, a set of topics (queries), and corresponding relevance judgments that indicate which documents are relevant to each topic. While acquiring the first two is relatively straightforward through methods like web crawling or query log analysis, obtaining reliable relevance judgments is more challenging. These judgments require significant human effort to ensure accuracy and consistency, making them time-consuming and costly to produce.
Over the years, three primary approaches have been used to collect relevance judgments. The most reliable method relies on editorial assessments, where professional annotators manually evaluate document relevance, as seen in large-scale evaluation campaigns like TREC, NTCIR, and CLEF. However, this approach is expensive. A cheaper alternative is crowdsourced annotations, where non-expert workers label data. While more affordable, crowd-sourced annotations are often noisy and less reliable. The third approach uses implicit feedback from user interactions, such as click logs, which is virtually cost-free but suffers from bias, noise, and privacy concerns. These methods form a spectrum, ranging from highly accurate but expensive human judgments to noisy but inexpensive implicit feedback.
Recently, LLMs have emerged as a potential fourth approach to generating relevance judgments. Early studies suggest that LLMs can achieve accuracy levels comparable to human crowd workers while significantly reducing costs. To explore this further, the LLMJudge challenge was organized as part of the LLM4Eval workshop at SIGIR 2024, where different research teams experimented with using LLMs for relevance annotation. While promising, this approach raises several unresolved questions, such as how prompt variations impact results, what biases LLM-generated judgments introduce, and whether there is a risk of evaluation circularity—where models are assessed using data similar to what they were trained on.
To contribute to this research, the authors released 42 pools of automatically generated relevance judgments created by eight different research teams from the LLMJudge challenge. Their findings confirm that while many LLM-based methods maintain ranking consistency, their absolute scoring tendencies differ, introducing potential biases in evaluation. They also explore different methodologies for assessing LLM-generated relevance judgments and provide baseline figures to guide future research.
You Do Not Fully Utilize Transformer's Representation Capacity
Standard Transformer decoders rely on a single residual stream per layer, meaning that each layer can only access information from the immediately preceding hidden state. This design limits the model’s ability to retain earlier learned features, often leading to representation collapse, where deeper layers lose the ability to distinguish between different tokens or features. The issue is particularly problematic for long sequences, where subtle distinctions can be squeezed out due to the finite capacity of hidden states and numerical precision constraints.
To address this limitation, the authors propose Layer-Integrated Memory (LIMe), an extension to masked multi-head self-attention that allows the model to retrieve and integrate representations from all previous layers, rather than just the most recent one. LIMe introduces a routing mechanism that selectively blends multi-layer features for both keys and values, preserving the core Transformer architecture while adding minimal computational overhead. This modification enables more efficient use of earlier learned representations, leading to richer contextual modeling.
Through extensive experiments in language modeling, LIMe demonstrates consistent performance improvements over standard Transformers and other recent architectural modifications. Empirical analysis reveals that LIMe reduces representation collapse, maintains higher entropy in deeper layers, enhances the separability of closely related tokens, and increases overall representational diversity. These findings indicate that LIMe enables models to maintain crucial lexical and syntactic cues from earlier layers, improving both accuracy and interoperability.
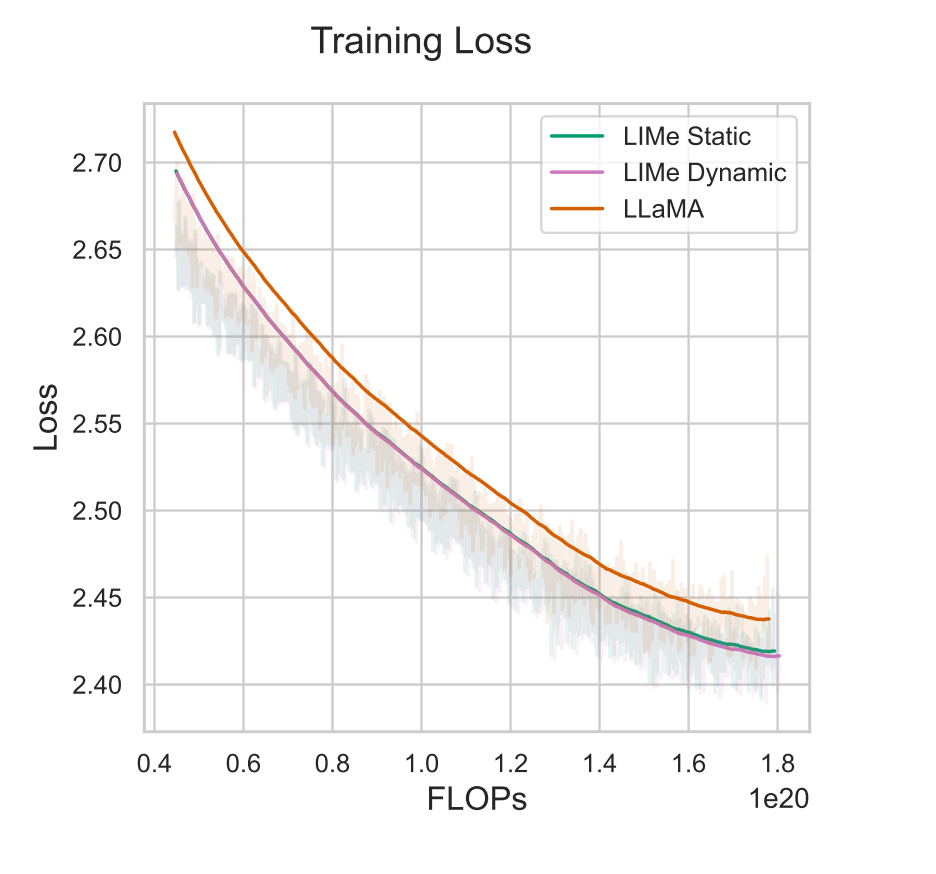
The study also explores how depthwise circuits learned by LIMe function, showing that the model dynamically reintroduces critical features from earlier layers at later stages. This insight highlights how LIMe effectively distributes the burden of long-range context retention across multiple layers, rather than forcing deeper layers to compress all necessary information into a single stream.
GitHub: corl-team/lime