
Generative Adversarial Distillation for Easier Closed-Weight Model Distillation
The Weekly Salt #96


This week, we review:
⭐Black-Box On-Policy Distillation of Large Language Models
The Path Not Taken: RLVR Provably Learns Off the Principals
Beyond English: Toward Inclusive and Scalable Multilingual Machine Translation with LLMs
Repositories (full list of curated repositories here):
⭐Black-Box On-Policy Distillation of Large Language Models
Black-box distillation for LLMs usually degenerates into plain supervised fine-tuning on API outputs, which is fundamentally off-policy and blind to how the student actually behaves at inference.
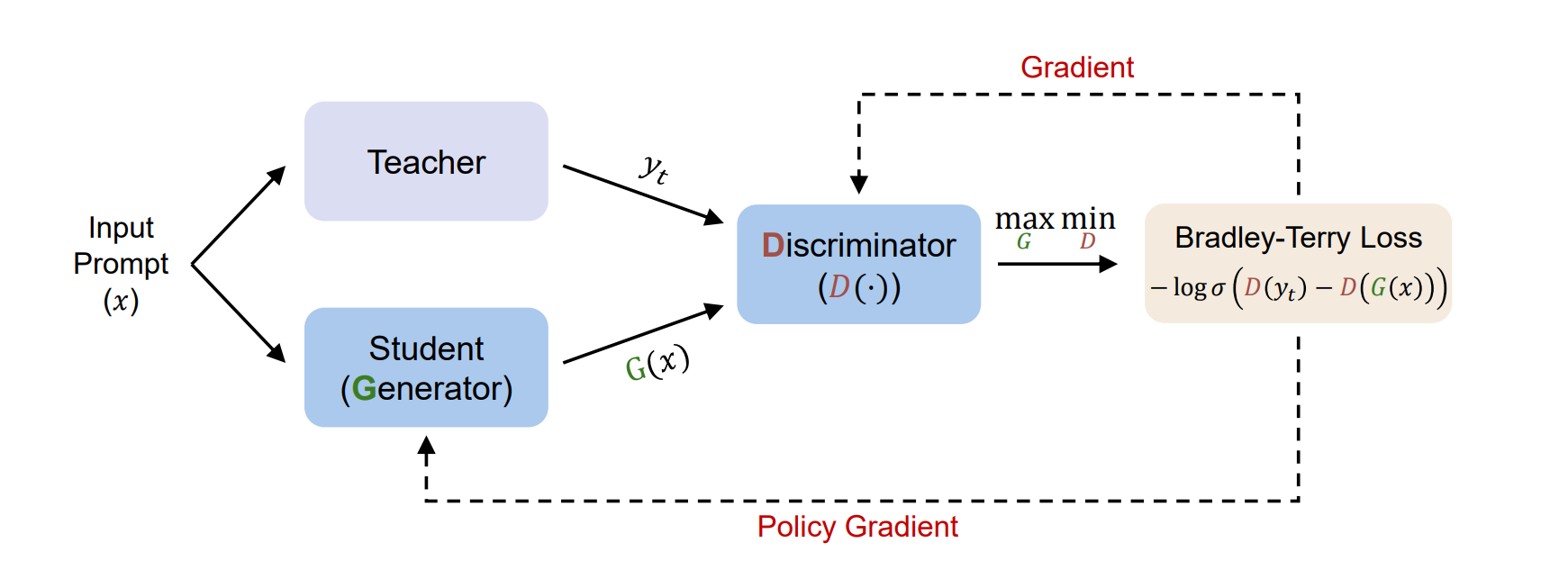
This work proposes Generative Adversarial Distillation (GAD): treat the student as a conditional generator and learn a discriminator that tries to tell teacher and student responses apart, then optimize the student to fool that discriminator. Here, we want to recover the benefits of on-policy distillation and RL-style mode seeking, but in a setting where you never see teacher logits and may not even share a tokenizer with the teacher.
Method-wise, GAD is essentially a sequence-level GAN for instruction-following models, implemented via standard RL tooling. The discriminator takes the concatenated prompt and response and outputs a scalar quality score. It is trained with a Bradley–Terry style preference objective to rank teacher responses above student ones. The student uses that scalar as a reward and is trained with a policy-gradient algorithm (GRPO) in an RLHF-like loop. There is a joint warmup phase: first fine-tune the student on teacher responses and train the discriminator on the same pairs, then move into adversarial on-policy training.
In RL terms, the generator is the policy model, the discriminator is an online reward model that co-evolves with the policy, and the whole thing runs inside an existing RLHF framework (verl), which makes the proposal less exotic than the “GAN” branding suggests.
The experimental setup is deliberately grounded in realistic closed-source → open-source distillation. GPT-5 is used as the teacher, while Qwen2.5 (3B/7B/14B) and Llama 3.x (3B/8B) instruction-tuned models serve as students. Training data are 200k prompts sampled from a cleaned version of LMSYS-Chat-1M, with teacher responses collected via API. Models are trained for three epochs with modest context lengths and a single temperature; evaluation is done on held-out LMSYS-Chat as well as Dolly, Self-Instruct, and Vicuna subsets to probe out-of-distribution generalization. Quality is primarily judged by GPT-4o-as-a-judge, with additional small-scale human evaluation on LMSYS prompts to confirm that the gains are not merely artifacts of the automatic metric.
On these benchmarks, GAD systematically beats both the original instruction-tuned students and the SeqKD baseline that simply fine-tunes on teacher outputs. For Qwen2.5, GAD shifts the effective parameter–performance frontier: a 3B student with GAD matches or exceeds a 7B student with SeqKD, and similarly 7B+GAD rivals 14B+SeqKD; the 14B Qwen2.5 distilled with GAD comes close to the GPT-5 teacher on the LMSYS test according to GPT-4o scores.
The analysis sections try to unpack why RL-style distillation behaves differently from SFT. N-gram overlap measurements show SeqKD students cling more tightly to teacher local patterns while still scoring worse under GPT-4o, consistent with SFT’s tendency to memorize lexical details rather than higher-level behavior.
The authors released their implementation here:
GitHub: microsoft/LMOps/tree/main/gad
The Path Not Taken: RLVR Provably Learns Off the Principals
Reinforcement Learning with Verifiable Rewards (RLVR) has been marketed as a way to reliably push LLMs into stronger reasoning regimes, yet when we inspect training logs we see a puzzling picture: most parameters barely move, and the few that do appear scattered and sparse.

In this work, the authors argue that this “sparsity” is largely a mirage created by the geometry of the pretrained model and the way RLVR is optimized. For a fixed base model, RL updates are repeatedly funneled into a small set of preferred weight regions, and this localization is remarkably stable across datasets, prompts, and RL variants. What looks like a few isolated active weights is better understood as the visible tip of an off-principal drift that the model’s own structure encourages.
To make sense of this behavior, they propose a Three-Gate Theory of RLVR’s training dynamics:
Gate I, KL Anchor: The KL penalty clips the effective step size and constrains updates into a narrow area around the base model’s distribution.
Gate II, Model Geometry: Within that area, the optimizer avoids principal directions, those aligned with top eigenvectors of the Hessian or Fisher, and instead steers into low-curvature, spectrum-preserving subspaces where it can accumulate reward without paying a large curvature tax.
Gate III, Precision: Outside the model’s preferred regions, the same pressure manifests as many tiny, high-precision adjustments that fall below usual inspection thresholds, making the off-principal bias look like genuine sparsity rather than fine-grained, distributed change.

Empirically, RLVR updates lie systematically off principal directions while preserving the spectrum of the weight matrices: eigenvalues drift minimally, principal subspaces rotate less than under supervised fine-tuning, and update directions align with low-curvature components rather than with the dominant modes that SFT tends to hit. By contrast, standard supervised fine-tuning directly pushes on principal weights, distorts the spectrum more aggressively, and in our measurements can even underperform RLVR on reasoning benchmarks despite touching far more of the parameter mass.
RLVR should be treated as a first-class, geometry-specific optimization problem. If RLVR naturally learns “off the principals” with minimal spectral disturbance, then parameter-efficient fine-tuning for RLVR should be designed around those constraints rather than retrofitting SFT-era heuristics. That means building PEFT schemes that explicitly respect low-curvature subspaces, track spectral drift, and expose, not hide, the micro-updates in non-preferred regions. In other words, if we want white-box RLVR rather than another round of opaque recipes, we have to stop asking how to compress SFT ideas into RL and start asking what an RLVR-native, geometry-aware toolkit actually looks like.
Beyond English: Toward Inclusive and Scalable Multilingual Machine Translation with LLMs
This paper introduces LMT, a family of Qwen3-based multilingual MT models that try to move beyond the familiar “everything funnels through English” setup. The models are explicitly dual-centric on Chinese and English, cover 60 languages with 234 translation directions, and come in 0.6B, 1.7B, 4B, and 8B parameter sizes.
The most interesting technical contribution, in my view, is the analysis of “directional degeneration” in multilingual SFT. Starting from Qwen3-4B, the authors fine-tune using standard symmetric multi-way bitext (each pair used in both directions). As expected, forward directions (En/Zh→X) improve, but reverse directions (X→En/Zh) collapse: outputs become fluent but unfaithful, with frequent hallucinations. They trace this to a shallow many-to-one shortcut: an English or Chinese sentence appears as the target for up to 59 different sources, so the model is rewarded for mapping diverse inputs into a small, high-frequency target space. Replacing the reverse data with a non-overlapping sample from a larger bilingual pool restores performance, which supports the diagnosis that the problem is the symmetric reuse pattern, not inherent asymmetry of directions.
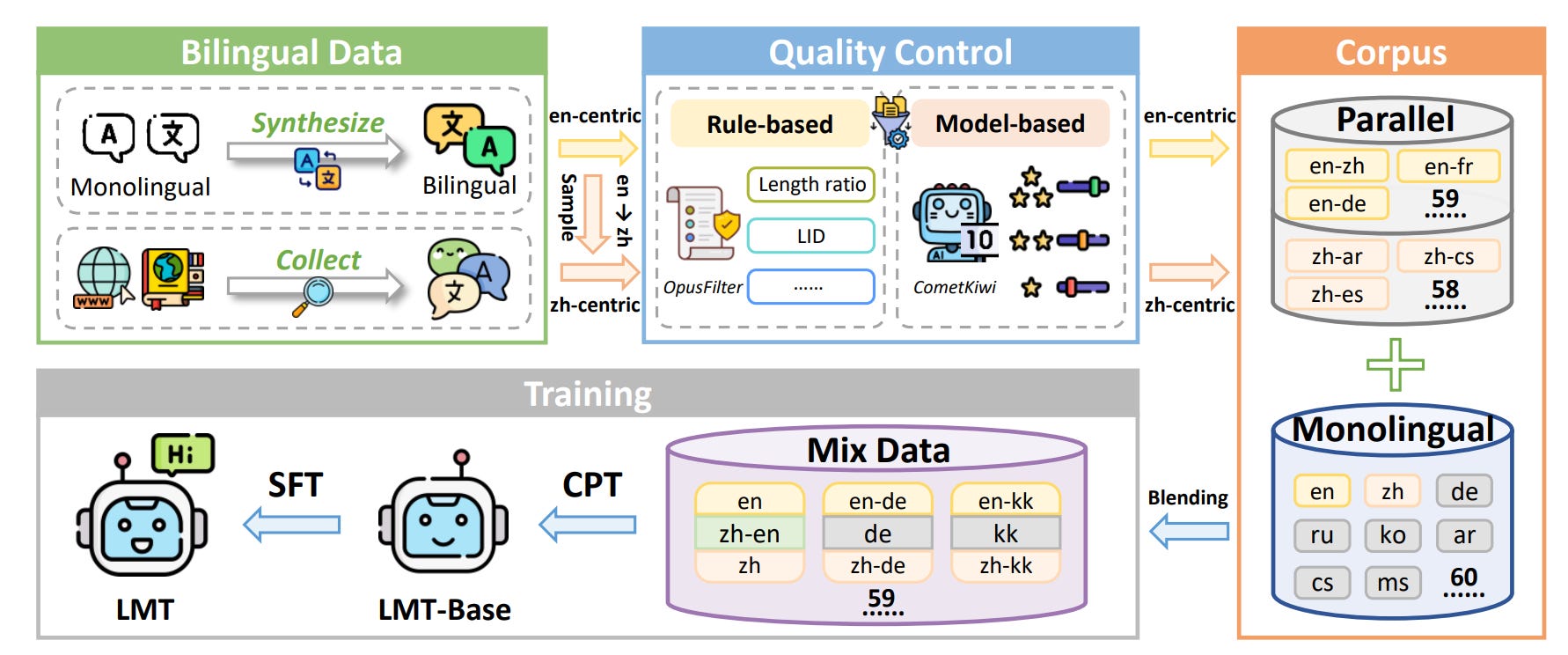
The fix, Strategic Downsampling, is simple. During SFT they keep all En/Zh→X examples but only retain a small fraction of X→En/Zh (a Bernoulli subsample with retention probability p). Sweeping p shows that even 0.5% retention is enough to avoid collapse. Performance peaks around 5%, and then gradually deteriorates as reverse repetition grows. They settle on p=5% across the board. In an ablation on the 4B model, introducing Strategic Downsampling on top of a naïve Base+SFT setup yields large gains into Chinese and English (+11.45 COMET into Chinese, +5.83 into English), while later adding CPT gives a further +3.8–8.2 points depending on direction. P