
How to Teach LLMs When to Think
The Weekly Salt #69


This week, we review three papers proposing distinct methods for teaching LLMs when to enter a "reasoning" mode:
⭐AdaCoT: Pareto-Optimal Adaptive Chain-of-Thought Triggering via Reinforcement Learning
AdaptThink: Reasoning Models Can Learn When to Think
Thinkless: LLM Learns When to Think
⭐: Papers that I particularly recommend reading.
New code repositories (list of all repositories):
⭐AdaCoT: Pareto-Optimal Adaptive Chain-of-Thought Triggering via Reinforcement Learning
LLMs still struggle with tasks that require multi-step reasoning. CoT prompting helps by forcing the model to generate intermediate reasoning steps before answering, which boosts performance in complex domains. But CoT is costly, token-wise, especially when it's applied indiscriminately. Most current approaches don’t really adapt CoT usage based on task complexity; they just reduce reasoning length across the board or rely on hard-coded triggers.
AdaCoT changes this by formalizing adaptive reasoning as a multi-objective optimization problem: one axis is accuracy, the other is inference cost (measured in tokens). They frame this as a Pareto frontier problem, which allows them to search for optimal trade-offs rather than making a single hard decision about when to trigger CoT.
The training pipeline is based on reinforcement learning. The agent’s action is whether (and how much) to engage CoT. The reward function is shaped by two components: response quality and token efficiency. Importantly, these are combined using a principled, tunable penalty coefficient rather than heuristic thresholds. The RL agent effectively learns a query complexity-aware policy. It adapts CoT usage depending on the prompt, which is something previous approaches don’t do well.
During inference, AdaCoT uses the learned policy to selectively trigger CoT. For easy queries, it outputs the answer directly; for harder ones, it kicks off full reasoning. This selective behavior results in large efficiency gains: in production-like settings, CoT triggering drops to ~3%, and total token usage is cut by over two-thirds, all while retaining nearly the same task performance on standard benchmarks.

AdaptThink: Reasoning Models Can Learn When to Think
AdaptThink proposes to train the model to decide dynamically whether to enter a “Thinking” mode or a “NoThinking” mode, depending on input difficulty. The technical insight here is twofold:
Mode Control via Constrained RL
AdaptThink frames this decision as a constrained RL problem. The model receives rewards for skipping the thinking phase (favoring efficiency), but a constraint ensures that accuracy doesn’t degrade overall. This constraint-based formulation prevents the model from greedily favoring shorter outputs at the cost of correctness. The optimization problem is solved using a Lagrangian relaxation approach to maintain a trade-off frontier.Balanced Exploration with Importance Sampling
A major challenge in early training is data imbalance: since “Thinking” is the default in pretrained models, “NoThinking” gets little exploration. AdaptThink addresses this with an on-policy importance sampling strategy that artificially balances the sampling of both modes. This helps stabilize training and avoids local minima where the model always chooses one mode.
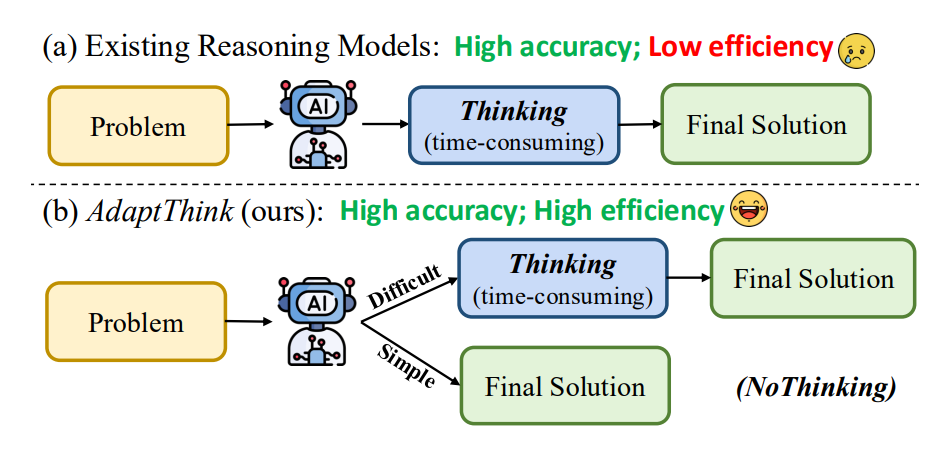
On the inference side, the model receives the same kind of problem prompt, but it first predicts which mode to engage in. If it chooses NoThinking, it generates the answer directly (potentially with a dummy <think></think> placeholder, like with Qwen3). If it selects Thinking, it enters a CoT loop before generating the answer.
Using a 1.5B parameter distilled model, AdaptThink cuts average token usage by 45–65%, depending on the dataset, and still improves accuracy slightly. That suggests many tasks don’t benefit from reasoning at all, and that over-reasoning may actually introduce unnecessary noise.
They released their code here:
GitHub: THU-KEG/AdaptThink
Thinkless: LLM Learns When to Think
Thinkless is another approach published this week to learn when to reason and when to skip it. It introduces a two-stage training process:
Supervised Warm-up with Distillation
The model first learns to imitate two expert models, one for detailed reasoning (<think>) and one for concise answers (<short>). It’s trained on paired examples to ensure it can generate both styles and condition its outputs on the corresponding control tokens.Reinforcement Learning with Decoupled GRPO
The second phase uses a modified Group Relative Policy Optimization (GRPO) approach called Decoupled GRPO (DeGRPO). This separates learning into two sub-objectives:Mode Selection: Decides whether to use
<think>or<short>based on the task at hand.Accuracy Improvement: Optimizes the quality of the generated answer under the selected mode.
Standard GRPO doesn't distinguish between the short control token and the long response, which can cause early mode collapse—where the model defaults to a single mode and stops exploring alternatives. DeGRPO fixes this by assigning different gradient weights to the control token and the rest of the output, ensuring both parts get meaningful updates. This encourages the model to explore both short and long reasoning strategies during training.

Once trained, the model can dynamically select the reasoning depth based on task difficulty. On simpler tasks (e.g., GSM8K, Minerva Algebra), it favors short-form responses, reducing token use by 50–90%. On harder tasks like AIME, it naturally shifts toward full CoT reasoning.
The authors released their code here:
GitHub: VainF/Thinkless