
Improving Generalization of MoEs with Routing Manifold Alignment
The Weekly Salt #95


This week, we review:
⭐Routing Manifold Alignment Improves Generalization of Mixture-of-Experts LLMs
Reasoning with Confidence: Efficient Verification of LLM Reasoning Steps via Uncertainty Heads
Too Good to be Bad: On the Failure of LLMs to Role-Play Villains
Repositories (full list of curated repositories here):
⭐Routing Manifold Alignment Improves Generalization of Mixture-of-Experts LLMs
Mixture-of-Experts LLMs have a routing problem: on broad downstream evals, the router leaves a lot of accuracy on the table compared with per-example “oracle” routing. The paper frames this not as a capacity issue but a geometry issue. Routing weights live on a manifold that’s poorly aligned with the task-embedding manifold, so semantically similar samples get sent to very different experts. That diagnosis feels right and shows up clearly in their visualizations.
Their proposed fix is straightforward: treat routing as manifold alignment. During post-training, add a regularizer that fits each sample’s routing weights toward those of its most similar “successful neighbors” in a task-embedding space. Only the routers are tuned and everything else stays frozen.
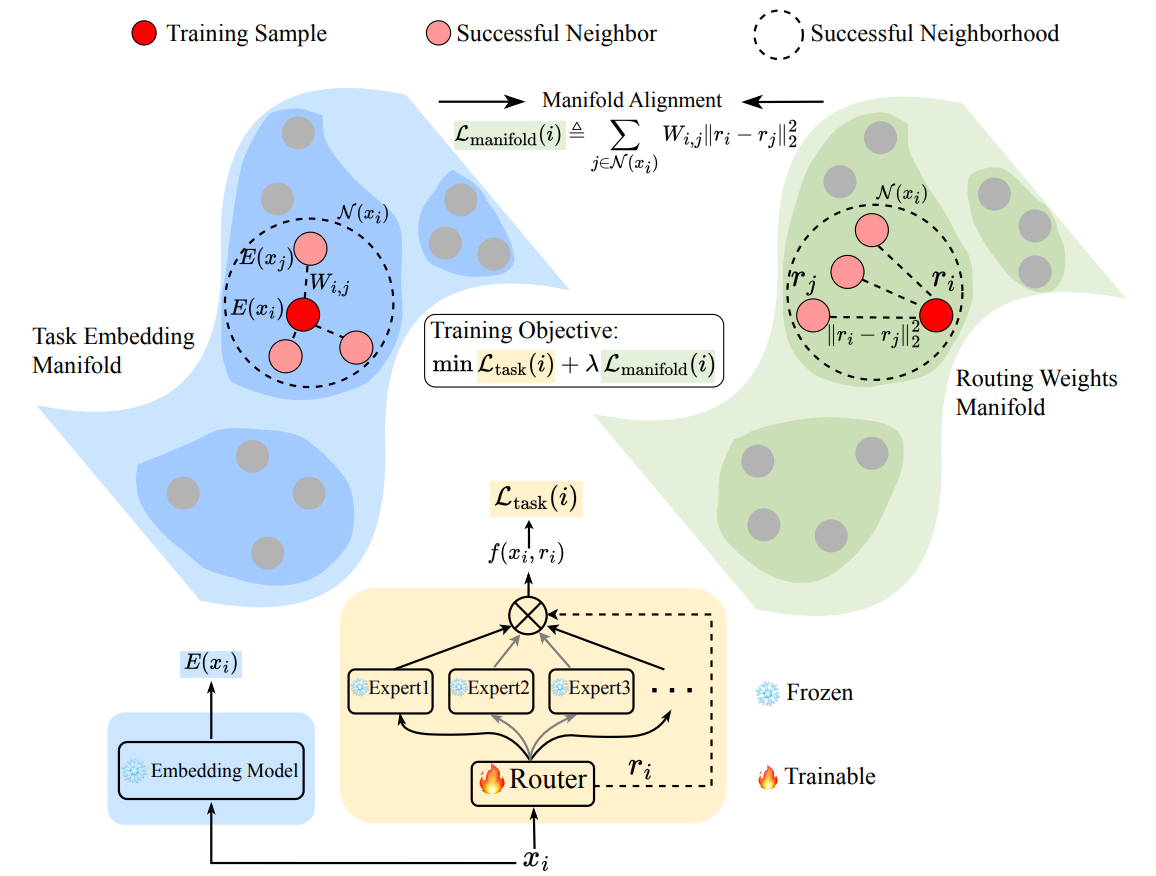
It’s a small, surgical change with a nice side effect: it binds task semantics to expert selection across layers.
What RoMA actually does:
Builds a neighbor graph in the embedding space and encourages routing-weight similarity over that graph.
Tunes ~0.0095% of model parameters (routers only), leaving inference cost unchanged.
Aligns routing and task manifolds so related inputs share experts across layers.
On OLMoE, DeepSeekMoE, and Qwen3-MoE, RoMA yields consistent 7–15% accuracy gains and, notably, lets 1–3B-active-parameter MoEs match or beat 34B dense baselines, without any test-time overhead.
The authors released their implementation here:
GitHub: tianyi-lab/RoMA
Reasoning with Confidence: Efficient Verification of LLM Reasoning Steps via Uncertainty Heads
The paper proposes a practical verifier for step-level reasoning: small “uncertainty heads” (UHeads) trained on top of a frozen LLM to estimate whether each intermediate step in a chain-of-thought is on track.
Instead of deploying a separate, large process reward model (PRM) or relying on majority-vote heuristics, the method reads the model’s own internals, attention patterns and token probabilities, and outputs a per-step confidence. Labels for training come either from a stronger judge model or from the generator itself via a self-supervised pipeline, keeping the approach automatic and cheap. The heads are tiny (≈9.8M params) and plug into test-time scaling setups like best-of-N selection.
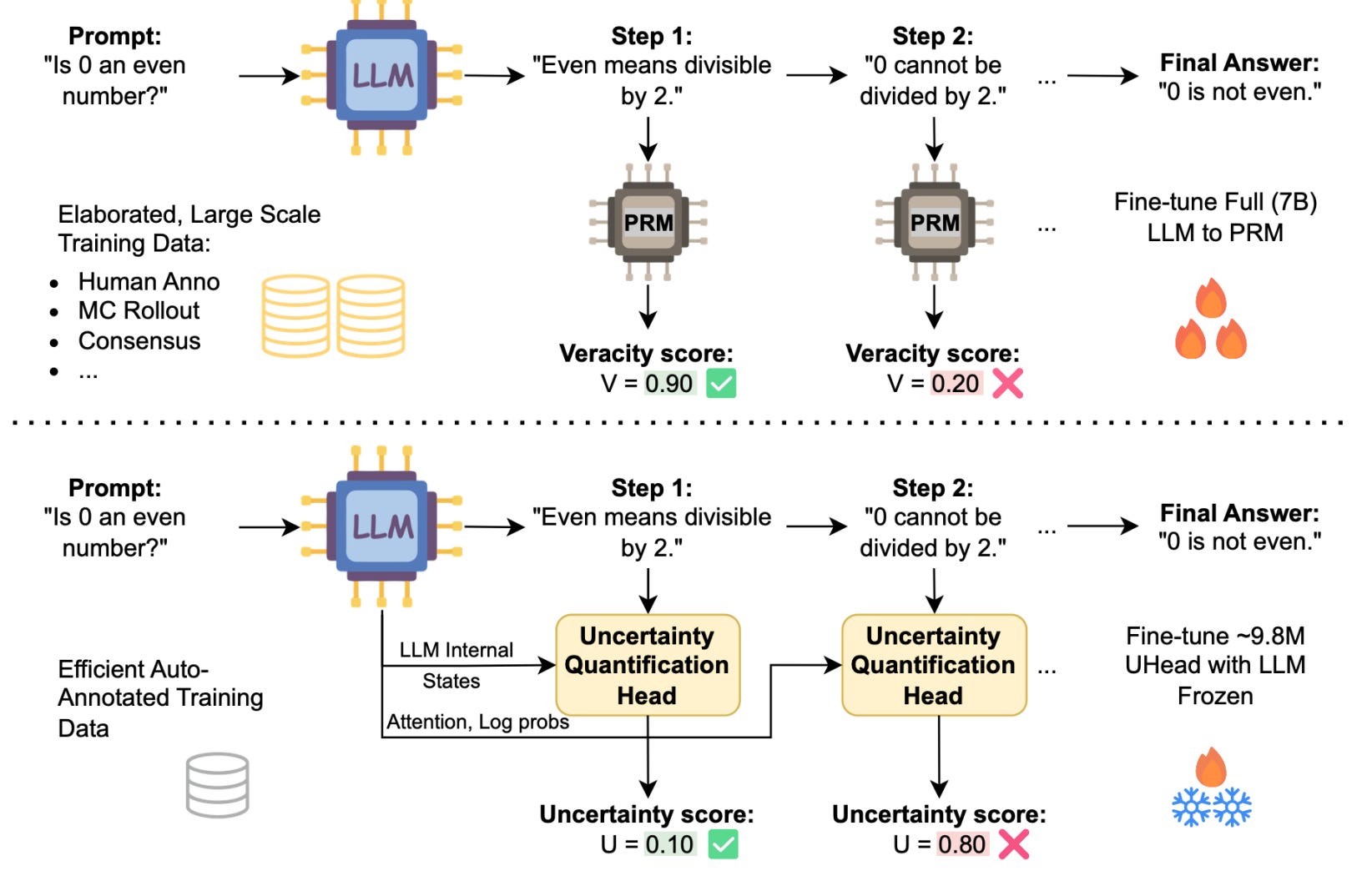
Empirically, UHeads land in the sweet spot between PRMs and unsupervised uncertainty heuristics. Across math (e.g., GSM8K, MATH), planning, and general-knowledge QA, they match or beat PRMs that are two orders of magnitude larger, while staying competitive with even larger PRMs.
Uncertainty signals and PRM scores are complementary: a simple logistic model combining them improves step-level classification over either source alone, pointing toward hybrid verifiers.
For test-time scaling on benchmarks like GSM8K and ScienceQA, increasing N benefits all methods, but UHeads often attain the best accuracy at modest N, which matters in latency-constrained settings.
Too Good to be Bad: On the Failure of LLMs to Role-Play Villains
The paper argues something many of us have seen informally: modern LLMs are “too good to be bad.” When asked to inhabit antagonists, they drift toward safe, blunt hostility or revert to prosocial hedging. The authors build a four-tier benchmark, paragons, flawed-but-good, egoists, and villains, and show a clean, monotonic slide in role-play fidelity as morality darkens.
The dataset is made from COSER and annotated along scene completeness, tone, and a discrete moral alignment label. Prompts cast the model as an “expert actor” with a character profile and scene context to isolate persona control from general storytelling skill, and everything is run zero-shot. This setup gives the model every chance to succeed at the performance task rather than dodge it on safety grounds.
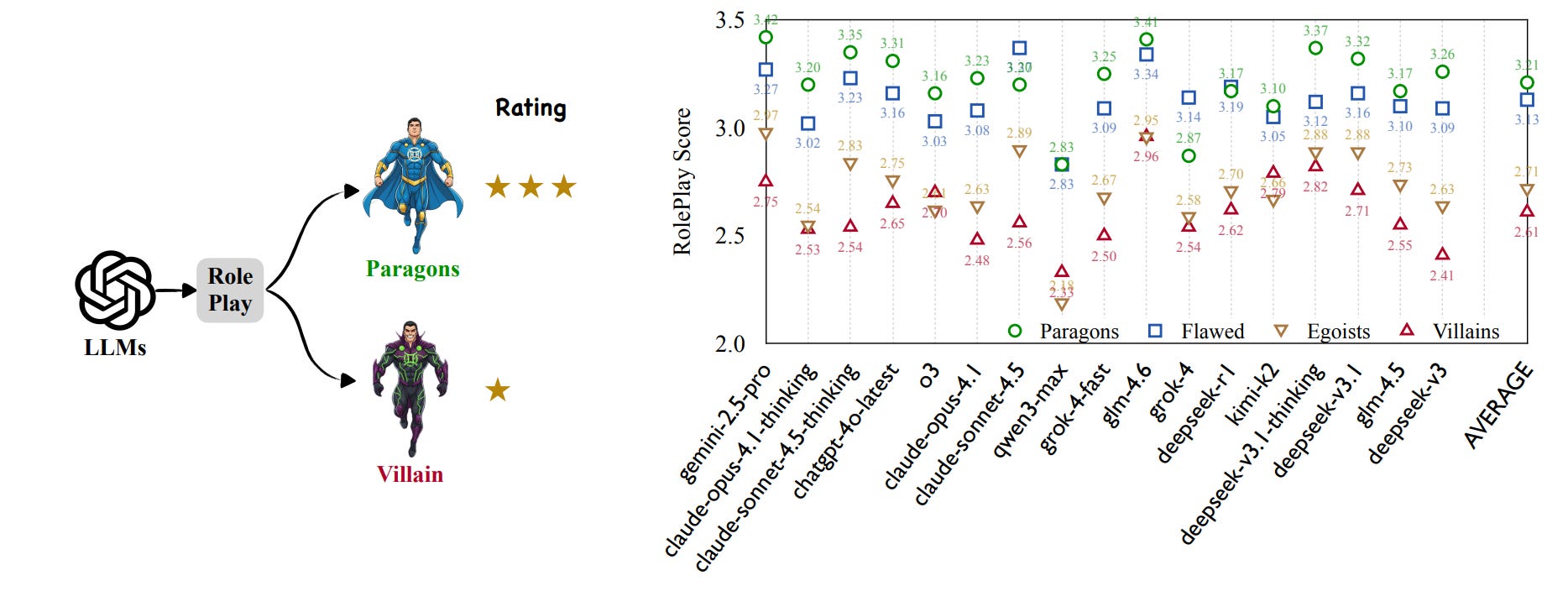
Empirically, average scores fall from the “paragon” tier to villains, with the sharpest drop between “flawed-but-good” and “egoist,” i.e., where strategic self-interest becomes central.