


This week, we read:
⭐Pre-DPO: Improving Data Utilization in Direct Preference Optimization Using a Guiding Reference Model
BitNet v2: Native 4-bit Activations with Hadamard Transformation for 1-bit LLMs
TTRL: Test-Time Reinforcement Learning
⭐: Papers that I particularly recommend reading.
New code repositories (list of all repositories):
Reinforcement Learning from Human Feedback (RLHF) is critical for aligning LLMs with human values. Methods like DPO (Direct Preference Optimization) reframe RLHF as directly training models based on preference data, using a reference model (usually identical to the starting model) to constrain learning via KL regularization.
However, newer methods like SimPO show that you don't even need a reference model; you can optimize preferences directly, which improves efficiency but risks catastrophic forgetting. We reviewed SimPO here:

Recent findings show that the reference model in DPO isn't just a static constraint. It acts more like a data weighting mechanism, boosting examples aligned with it and down-weighting conflicting ones. But when you initialize the policy and reference model identically (standard practice), early training ends up treating all data equally, which isn't ideal for learning dynamics. Worse, over time, the identical reference starts to over-constrain the policy, capping its performance.
To address this, Pre-DPO proposes a simple idea:
First, train the policy once (using DPO or SimPO).
Then, the trained model can be used as a new "guiding reference model", one that's better than the initial policy but not fully fixed.
Re-run DPO using this smarter reference, leading to better data reweighting and more effective learning.
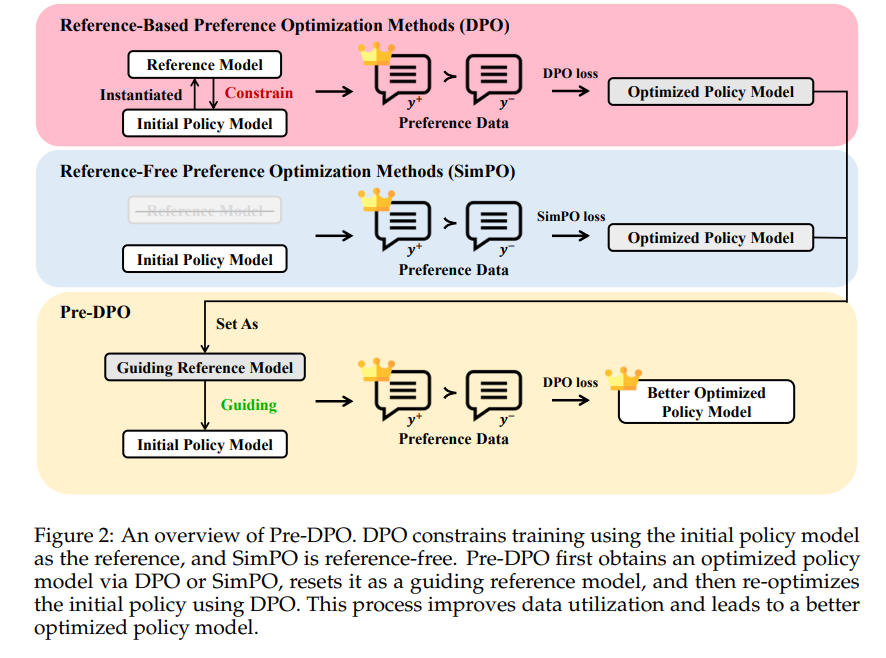
Pre-DPO turns the reference model into a dynamic guide rather than a rigid constraint, leading to more efficient learning without needing external models or extra data. Experiments on Llama3.2 and Qwen2.5 models show Pre-DPO consistently improves win rates by about 2.5–2.6 points on tough benchmarks like AlpacaEval 2 and Arena-Hard v0.1.
The main weakness of this method is that you have to run preference optimization twice. This is not cheap. I would run the first optimization with SimPO to reduce the cost.
BitNet v2: Native 4-bit Activations with Hadamard Transformation for 1-bit LLMs
Deep learning is rapidly shifting towards quantization-aware training and ultra-low-bit inference, thanks to next-gen hardware like Blackwell GPUs with native 4-bit support. Recent work, such as BitNet b1.58, has shown that even 1.58-bit quantized LLMs can match full-precision accuracy while massively cutting inference costs. However, these models still rely on 8-bit activations, limiting their ability to fully exploit 4-bit hardware, turning computation itself into the new bottleneck.

A key challenge for activation quantization in LLMs is handling outliers, especially in intermediate outputs of attention and feed-forward layers. Past attempts, like BitNet a4.8, used sparse 8-bit activations to deal with outliers, but this hurt throughput in batch inference due to inefficiencies in sparse computation.
BitNet v2, proposed in this paper, solves this by introducing H-BitLinear layers, which perform an online Hadamard transformation before activation quantization, reshaping the activation distributions to be more Gaussian-like and less impacted by outliers.
Hadamard transformation
You take your input vector
xand multiply it by a Hadamard matrixHto get a transformed vectorHx.Because of how Hadamard matrices are structured, this spreads out ("mixes") the information from different dimensions evenly.
It’s super fast to compute.
It's cheap, efficient, and makes data distributions more "uniform" (e.g., helps kill sharp outliers by redistributing their impact across all dimensions).
This makes true 4-bit activation quantization feasible. Training BitNet v2 initially with 8-bit activations and then fine-tuning briefly for 4-bit activations achieves performance similar to BitNet a4.8, but significantly boosts computational efficiency for batched inference.

TTRL: Test-Time Reinforcement Learning
Test-Time Scaling (TTS) is emerging as a way to boost LLM reasoning without the massive costs of pretraining scale-ups. While current TTS methods (like reward models, majority voting, and tree search) help, models still struggle with unseen, unlabeled, complex data. RL during standard training can't fully bridge this gap because it doesn't adapt at inference time.
Test-Time Training (TTT) approaches aim to fine-tune models on incoming test data but usually need labeled data, which is impractical at scale.
To solve this, Test-Time Reinforcement Learning (TTRL) is introduced by this paper:
It applies RL during test-time, using repeated sampling and majority voting to estimate rewards without ground-truth labels.
Models self-generate experiences, learn from their own outputs, and evolve in real time.
TTRL boosts generalization and self-improvement for unlabeled, streaming data.

In experiments (e.g., Qwen2.5-Math-7B on AIME 2024), TTRL achieved up to 159% performance gains, all without any labeled training data, and works across model types and scales.
The authors released their code here:
GitHub: PRIME-RL/TTRL