
Joint Prediction of Token Order and Next Token
The Weekly Salt #84


This week, we review:
⭐Predicting the Order of Upcoming Tokens Improves Language Modeling
UltraMemV2: Memory Networks Scaling to 120B Parameters with Superior Long-Context Learning
Repositories (full list of curated repositories here):
⭐Predicting the Order of Upcoming Tokens Improves Language Modeling
LLMs are typically trained using next-token prediction (NTP), a simple yet effective objective. While some have criticized NTP for accumulating inference-time errors, others argue the real issue lies in training-time misalignment due to teacher forcing. This mismatch limits the model’s ability to truly learn accurate next-token distributions.
To address some of these limitations, Multi-Token Prediction (MTP) has been proposed, where models predict several future tokens at different offsets. MTP has shown improvements on look-ahead tasks like coding and summarization, and has been integrated into models like DeepSeek-V3. However, it doesn’t generalize well across standard NLP tasks, struggles in smaller models, adds significant compute due to extra heads, and requires careful hyperparameter tuning, without guaranteed performance gains.
This paper introduces Token Order Prediction (TOP), a new auxiliary objective that predicts the relative order of upcoming tokens using a ranking loss, rather than their exact identities. Unlike MTP, TOP encourages future-aware internal representations without increasing model complexity or relying on brittle architectural choices. It’s designed to strengthen next-token prediction while avoiding the over-specification and inefficiencies inherent in MTP.
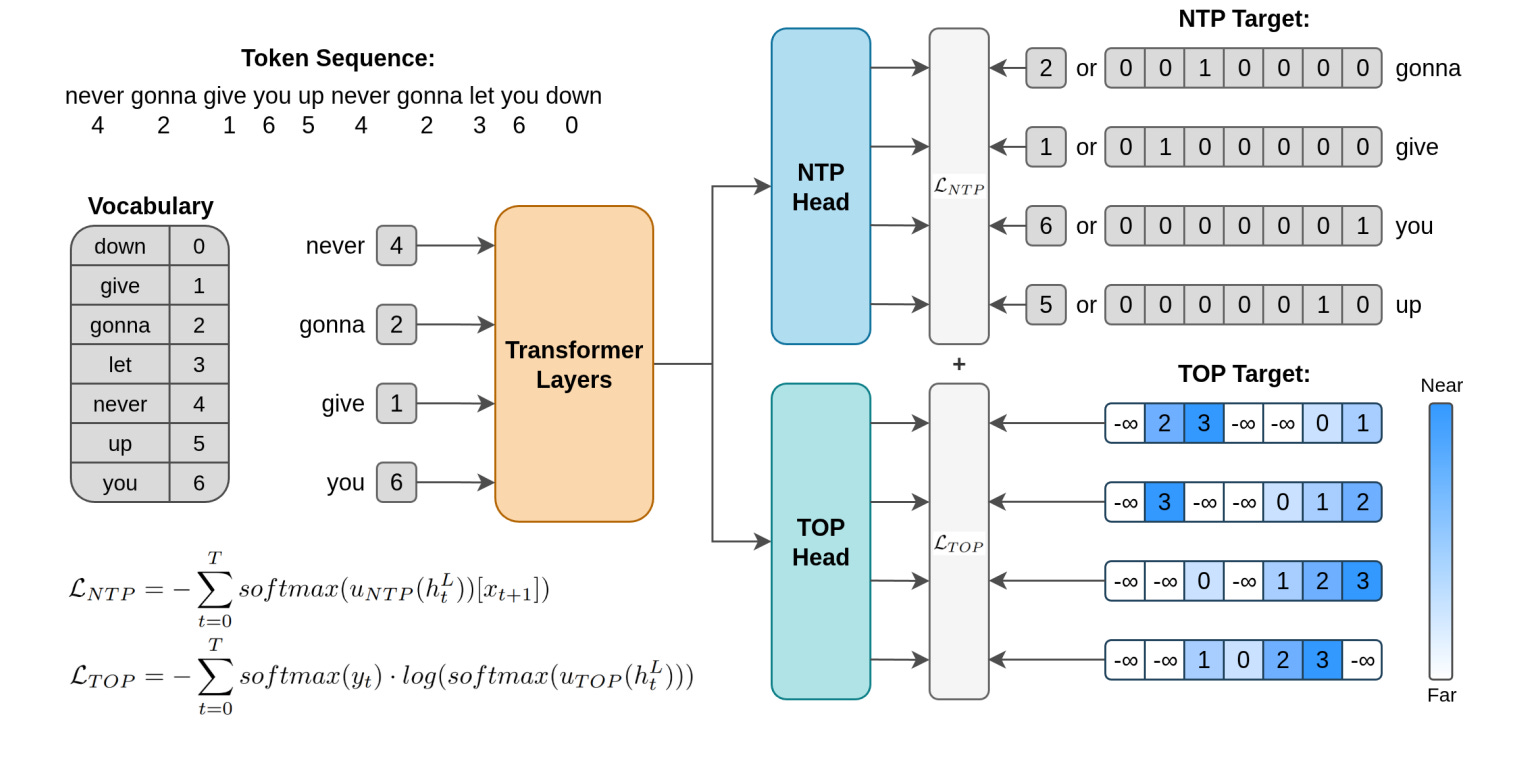
Experiments across model sizes (340M, 1.8B, 7B) show that TOP outperforms both NTP and MTP on standard NLP benchmarks, including at larger scales. While early results are promising, questions remain about implementation details, generalization across tasks, and sensitivity to decoding settings. Still, TOP presents a compelling, low-overhead alternative to MTP for enhancing LLM training.
The authors released their code here:
GitHub: zaydzuhri/token-order-prediction
UltraMemV2: Memory Networks Scaling to 120B Parameters with Superior Long-Context Learning
LLMs face increasing deployment challenges due to their growing parameter counts and computational demands. Mixture of Experts (MoE) architectures address this by activating only a subset of experts per input, decoupling model size from compute cost. While MoEs with 8 active experts offer strong performance-efficiency trade-offs, they suffer from high memory access costs due to complex expert routing.
Memory-layer architectures provide a more memory-efficient alternative by activating embeddings from large parameter tables rather than full expert networks. These architectures, like UltraMem, reduce memory overhead but historically underperform compared to top-tier MoEs, especially those with 8 active experts.
To close this gap, the authors introduce UltraMemV2, a redesigned memory-layer model that incorporates tighter integration with Transformer blocks, streamlined value processing, expert-like FFN computation, optimized initialization, and better compute balancing. These enhancements enable UltraMemV2 to match 8-expert MoE performance while preserving the low-memory-access advantages of memory layers.
Empirical results show that UltraMemV2 excels on memory-intensive tasks such as long-context and multi-round memorization, and in-context learning, with notable performance gains. The model scales effectively to large parameter counts (up to 120B) and highlights activation density, not just parameter count, as a key factor in sparse model performance.
They released their code here: