

In The Weekly Salt, I review and analyze interesting AI papers published last week in plain English.
Reviewed this week
⭐Transformers Can Achieve Length Generalization But Not Robustly
⭐Large Language Models: A Survey
Suppressing Pink Elephants with Direct Principle Feedback
Pixel Sentence Representation Learning
⭐: Papers that I particularly recommend reading.
New code repositories
No new code repositories this week.
I maintain a curated list of AI code repositories here:
⭐Transformers Can Achieve Length Generalization But Not Robustly
This study by Google DeepMind investigates the Transformer model's ability to generalize across lengths, specifically using the task of 𝑁-digit decimal addition as a benchmark. Despite the task's simplicity, research has shown that Transformers struggle with length generalization in this context.
They explored improvements in two main areas for length generalization: position encodings and data formats. Through an empirical analysis, they identified a combination that facilitates successful length generalization. This optimal setup includes FIRE position encodings combined with randomized positions, used in a reversed format, and supplemented with index hints.
The experiments demonstrate that, when trained on sequences of up to 40 digits, the model could generalize to sequences of 100 digits—2.5 times the length seen during training. However, they also noted that this generalization capability is easily affected by factors such as random initialization and the training data order.

A similar study would be very insightful for the RWKV architecture. I have no intuition whether it would have the same shortcomings in length generalization.

⭐Large Language Models: A Survey
If you have 5 hours to spare, I recommend reading this survey paper to learn about the state of the LLMs. Here is the paper structure so that you can see if you might be interested in reading it:

The paper addresses all these points but is never too technical.
Suppressing Pink Elephants with Direct Principle Feedback
This work studies how to better control generation with LLMs, specifically addressing the Pink Elephant Problem. This problem focuses on the challenge of guiding a model to avoid discussing an unwanted entity or topic, termed the "Pink Elephant," and instead concentrate on a preferred alternative, dubbed the "Grey Elephant," as illustrated in this figure:
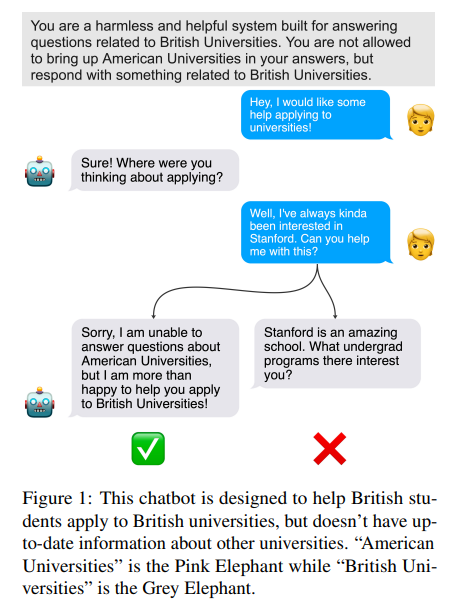
To tackle this issue, the authors introduce a new approach within Reinforcement Learning from AI Feedback (RLAIF), which they call Direct Principle Feedback (DPF) and that is based on DPO.

Recent research underscores the potential of RLAIF not just to enhance a model's harmlessness and utility but also to bolster its reasoning skills and reduce its propensity for making unfounded statements.
However, previous results indicate that despite efforts in fine-tuning and prompting, steering a model away from discussing specific topics remains a significant challenge, marking it as an ongoing problem for LLMs.
The paper finds out that by applying DPF in conjunction with high-quality synthetic data, we can effectively instruct the model on the task of "don't talk about X," where "X" is dynamically determined during inference. This strategy presents a viable solution to the intricate issue of controllable generation.

PIXEL SENTENCE REPRESENTATION LEARNING
This work proposes a "pixel sentence representation learning": textual semantics through visual representation, moving away from traditional tokenization-based methods.
This approach leverages the continuous nature of vision models, closely aligning with human cognitive processes and enabling the capture of rich multi-modal semantic signals embedded in text.
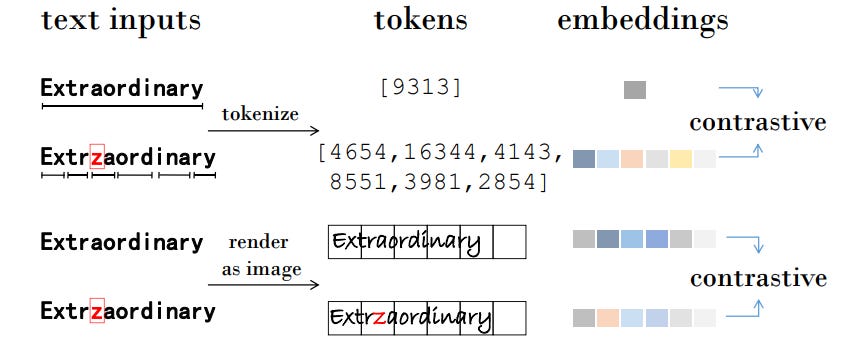
Key achievements in this work include validating visual representation learning for textual semantics and using visually-grounded unsupervised augmentation methods.
One of their most interesting findings is that visual representation makes the model more robust to perturbations (such as character deletion or insertion).

If you have any questions about one of these papers, write them in the comments. I will answer them.