


This week, we read:
⭐Learning Dynamics in Continual Pre-Training for Large Language Models
SIMPLEMIX: Frustratingly Simple Mixing of Off- and On-policy Data in Language Model Preference Learning
DanceGRPO: Unleashing GRPO on Visual Generation
⭐: Papers that I particularly recommend reading.
The Qwen3 paper has been released today:
I’m preparing a full review. Stay tuned!
⭐Learning Dynamics in Continual Pre-Training for Large Language Models
Continual Pre-Training (CPT) extends a pre-trained LLM by further training on domain-specific data (like math, code, or finance) to improve downstream performance while avoiding the high cost of full retraining.

However, a persistent challenge is catastrophic forgetting, where gains in the new domain come at the expense of performance on more general tasks.
This paper explores the dynamics of CPT more deeply than prior work, which often only compares before-and-after snapshots. Specifically, it asks two core questions: (1) Can we model how various training factors (e.g., learning rate, distribution shift, replay ratio) influence CPT outcomes? And (2), can we trace how model performance evolves during CPT rather than just measuring it at the end? By analyzing loss curves over time and factoring in learning rate schedules and domain shifts, the authors propose a new scaling law that helps explain and predict these dynamics. They find, for instance, that larger shifts between the pretraining and CPT domains produce more dramatic loss behavior, and that models with more “loss potential” (capacity for further improvement) adapt better.

Their framework helps guide hyperparameter tuning during CPT. For example, it can suggest optimal replay ratios or learning rate schedules depending on how different your CPT dataset is from the original one.
This paper investigates how the origin of preference data, whether it comes from the target model itself (on-policy) or from other models (off-policy), affects language model alignment. While on-policy data reflects the behavior of the current model, off-policy data can include responses from other models, potentially offering broader or more diverse perspectives. Prior research has been split: some studies show that on-policy data leads to better alignment, while others find little benefit or even better results with off-policy data. However, many of these studies lack a controlled comparison and do not account for how task type influences the effectiveness of each data source.
To address these gaps, the authors design a controlled setup where the only difference is the data source, not the alignment algorithm or model. They evaluate alignment outcomes across a range of task types, such as reasoning tasks (e.g., math, coding) and open-ended tasks (e.g., story generation, recommendations). The key finding is that on-policy data is more effective for tasks with objective answers, where model outputs can be clearly evaluated for correctness. In contrast, off-policy data performs better on tasks with subjective or diverse answers, where there's no single correct response.
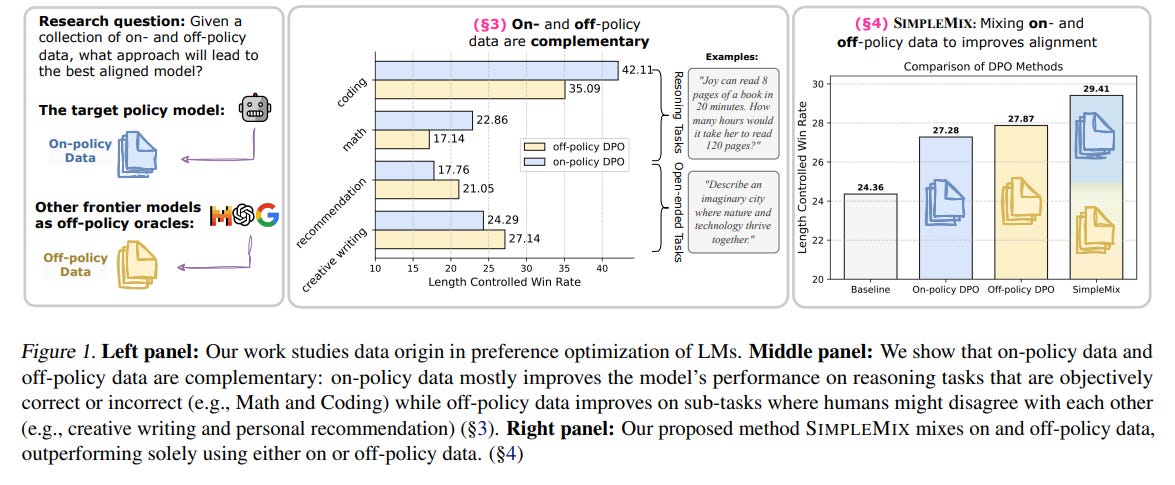
Motivated by these complementary strengths, the authors introduce SIMPLEMIX, a minimal method that mixes on- and off-policy data during preference optimization (e.g., DPO training). SIMPLEMIX uses equal-sized datasets from each source, avoiding complex weighting or heuristics. Surprisingly, this straightforward approach consistently outperforms using only one type of data, and also beats more elaborate hybrid methods from recent work. The improvements are particularly notable in low-data regimes, where making the most of limited training examples matters most.
DanceGRPO: Unleashing GRPO on Visual Generation
This paper introduces DanceGRPO, a reinforcement learning framework that adapts Group Relative Policy Optimization (GRPO) to visual generative models, specifically diffusion models and rectified flows. While existing visual alignment methods like ReFL or Diffusion-DPO either require heavy engineering or offer limited improvements in visual quality, DanceGRPO provides a more scalable and generalizable approach. It overcomes known challenges in applying RL to visual generation, such as mismatches between ODE-based sampling and MDP formulations, by reformulating sampling via Stochastic Differential Equations (SDEs).
It also addresses prior RL instability issues and is shown to perform well at scale.
The authors studied the harmonization of GRPO with visual generation, enabling stable policy optimization across different noise scales, timesteps, and feedback types. Notably, DanceGRPO can even learn from sparse binary feedback (0/1 rewards), which is often difficult for other RL methods.
Experiments show strong results: up to 181% improvement over baselines across standard visual generation benchmarks like CLIP score, HPSv2.1, and VideoAlign. The method also improves Best-of-N inference by learning better denoising trajectories.