


LongRoPE and Language Models as Universal Regressors
The Weekly Salt #6

In The Weekly Salt, I review and analyze interesting AI papers published last week in plain English.
Reviewed this week
⭐LongRoPE: Extending LLM Context Window Beyond 2 Million Tokens
Synthetic Data (Almost) from Scratch: Generalized Instruction Tuning for Language Models
FinTral: A Family of GPT-4 Level Multimodal Financial Large Language Models
OmniPred: Language Models as Universal Regressors
⭐: Papers that I particularly recommend reading.
New code repository:
I’ll consider adding the LongRoPE repository once it is officially online.
I maintain a curated list of AI code repositories here:
⭐LongRoPE: Extending LLM Context Window Beyond 2 Million Tokens
The Transformer architecture struggles with the quadratic computational complexity of self-attention and its lack of generalization to token positions unseen at training time. To scale the self-attention computation to a large context, various methods have been proposed, such as the RoPE, AliBi, attention sinks, etc. Nonetheless, none of these solutions can effectively scale to context with millions of tokens while preserving the model's accuracy.
This paper presents a new technique, LongRoPE, expanding the context window of LLMs to over 2 million tokens.
LongRoPE utilizes a progressive extension strategy to attain a 2048k context window without necessitating direct fine-tuning on exceedingly lengthy texts, which are both rare and difficult to procure. This strategy initiates with a 256k extension on a pre-trained LLM, followed by fine-tuning at this length.
To address potential performance declines in the original (shorter) context window, LongRoPE further adjusts the RoPE rescale factors on the extended LLM, scaling down to 4k and 8k context windows on the 256k fine-tuned LLM using its search algorithm to minimize positional interpolation. During inference for sequences under 8k in length, RoPE is updated with these meticulously searched rescale factors.

Testing across various LLMs and tasks requiring long contexts has validated LongRoPE's efficacy. The method significantly maintains low perplexity across evaluation lengths from 4k to 2048k tokens, achieves above 90% accuracy in passkey retrieval, and delivers accuracy comparable to standard benchmarks within a 4096 context window.

The code will be released by the authors here:
microsoft/LongRoPE (not yet there when I was writing this)
Note: I’m writing a long review of this paper for The Salt. I’ll publish it next week.
With the transformer being able to efficiently handle context with millions of tokens, it seems that we will never need to fully adopt alternative architectures such as RWKV that are more efficient with long contexts.

Synthetic Data (Almost) from Scratch: Generalized Instruction Tuning for Language Models
Synthetic data are often used to improve LLM fine-tuning while being much cheaper than data created by humans.

In this work, they introduce GLAN (Generalized instruction-tuning for Large lANguage models), a novel method for generating synthetic instruction datasets. Unlike previous approaches, GLAN leverages a carefully curated taxonomy of human knowledge and capabilities as a foundation to systematically and automatically generate instruction data across numerous disciplines.
This taxonomy is developed by breaking down human knowledge into fields, sub-fields, and disciplines, with the assistance of language models and human validation to ensure accuracy and comprehensiveness. This process is efficient due to the manageable number of disciplines.
By mirroring the human educational process—where subjects are defined, syllabuses are crafted, and core concepts are identified within class sessions—GLAN generates diverse instructions spanning various topics and human skills. This is achieved by sampling key concepts from each class session detailed in the syllabus, thereby creating teaching materials and exercises that make the instruction datasets.

GLAN is task-agnostic, capable of covering a wide range of domains, and produces instructions on a massive scale with minimal human effort required for taxonomy creation. Additionally, GLAN supports the integration of new fields or skills by adding new nodes to the taxonomy. This flexibility allows for independent expansion of each node, eliminating the need to regenerate the entire dataset for updates. Through extensive testing on LLMs, GLAN has proven effective in various tasks, including mathematical reasoning, coding, academic exams, and logical reasoning, without relying on task-specific training data.

FinTral: A Family of GPT-4 Level Multimodal Financial Large Language Models
This paper introduces FinTral, LLMs for the financial sector, employing a multimodal approach to handle textual, numerical, tabular, and visual data for document analysis.
FinTral is based on Mistral-7b further fine-tuned with domain-specific instruction datasets and DPO for alignment with human preferences. According to their experiments, FinTral surpasses similar-sized models and competes closely with the much larger GPT-4, despite its smaller scale.

Key contributions of this work include the development of the FinTral models and FinSet, a comprehensive benchmark for training and evaluating financial LLMs.

The paper is mainly interesting for its description of how they trained the models and built the datasets.
In the paper they wrote, “We plan to release our models responsibly.” but they didn’t precise when.
OmniPred: Language Models as Universal Regressors
Can language models accurately predict numerical values? i.e., can they be accurate regressors?
LLMs, with their sophisticated textual processing capabilities, offer a promising alternative to the laborious task of transforming input features into numerical tensors, a process yet unexplored in the context of developing a "universal" metric predictor across diverse datasets.
This work introduces OmniPred, a framework for metric prediction that exploits textual representations.

They demonstrate good accuracy in metric predictions using solely text and token-based representations. Moreover, by adopting a multi-task learning approach across diverse input spaces and objectives, OmniPred often surpasses conventional regression models, including Multilayer Perceptrons (MLPs) and boosted trees, in performance.
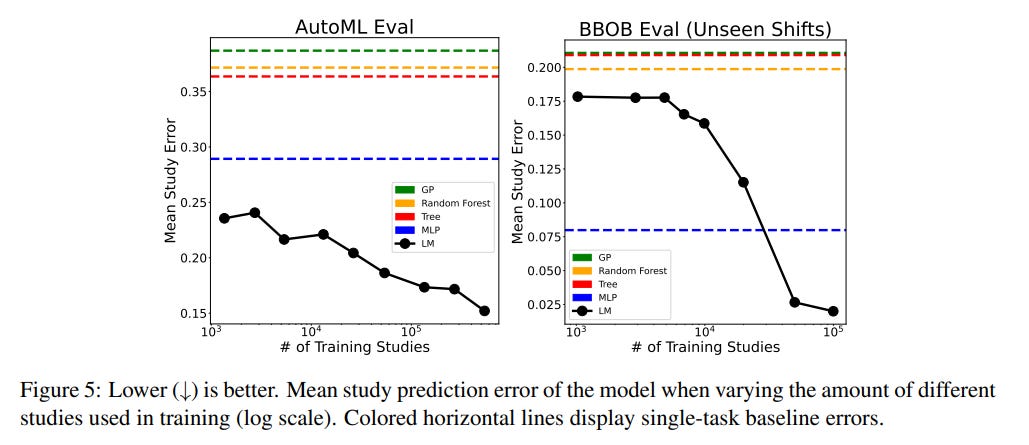
They have released the code in the optformer repository:
GitHub: optformer/omnipred
If you have any questions about one of these papers, write them in the comments. I will answer them.