


LongRoPE2: Training on Very Long Context with NTK Scaling and Mixed-Context Windows
The Weekly Salt #58


This week, we read:
⭐LongRoPE2: Near-Lossless LLM Context Window Scaling
Liger: Linearizing Large Language Models to Gated Recurrent Structures
Large-Scale Data Selection for Instruction Tuning
⭐: Papers that I particularly recommend reading.
New code repositories (list of all repositories):
⭐LongRoPE2: Near-Lossless LLM Context Window Scaling
With LongRoPE, Microsoft has demonstrated that it is possible to train LLM with a context of millions of tokens. We reviewed it here:

Since its publication, LongRoPE has been successfully applied to Phi-3 and Phi-4, even though both models officially only support 128k tokens of context.
Expanding the context requires rescaling Rotary Positional Embeddings (RoPE) after pre-training, but this process introduces out-of-distribution (OOD) errors in higher dimensions. These errors arise because RoPE embeddings, especially in higher dimensions, do not complete their rotation cycles within the original context window, leading to degraded performance on longer sequences.
Current methods like YaRN, NTK, and LongRoPE attempt to rescale RoPE for longer contexts, but they struggle with two main issues. First, they often fail to fully extend the context window to its intended length. For example, Llama 3.1 uses YaRN to reach 128k tokens, but its performance drops beyond 64k when tested on long-context benchmarks like RULER. Second, context expansion usually reduces accuracy on shorter sequences. When extending models like Phi3-mini to 128k, standard methods cause notable drops in MMLU scores, making them less reliable for mixed-context tasks. Fixing these issues requires expensive mid-training techniques, such as multi-stage progressive extension or pre-training data replay, which increase both computational cost and complexity. Llama 3.1, for instance, needed 800B tokens for context scaling, making the process highly inefficient.

LongRoPE introduces a more refined approach to RoPE rescaling, addressing these limitations directly. Instead of applying a uniform scaling method, it identifies critical RoPE dimensions where errors occur. Lower-dimensional RoPE components are well-trained, but higher dimensions remain undertrained, leading to unexpectedly long rotation cycles. To fix this, LongRoPE uses evolutionary search to pinpoint the exact dimensions that need adjustment, ensuring better rescaling without unnecessary modifications.
A major innovation in this new version, LongRoPE2, is its "needle-driven" perplexity (PPL) evaluation, which focuses on specific key answer tokens in long documents rather than averaging across all tokens. This makes it more effective at measuring true long-context comprehension. Unlike previous approaches, which use fixed scaling factors, LongRoPE2 applies NTK scaling to lower dimensions while using optimized, empirically determined rescaling factors for higher dimensions. This ensures that OOD issues are fully addressed without degrading short-context performance.
To further preserve short-context accuracy, LongRoPE2 introduces mixed context window training. During training, the model learns to handle both short and long sequences simultaneously. Short sequences retain their original RoPE embeddings, while long sequences use rescaled RoPE. At inference, the model dynamically switches between the two based on input length, preventing performance loss on short tasks.
Microsoft plans to update their LongRoPE implementation here:
GitHub: microsoft/LongRoPE
Liger: Linearizing Large Language Models to Gated Recurrent Structures
New approaches, linearizing pretrained LLMs, allow converting existing LLMs into linear recurrent architectures. However, current methods struggle with effectively incorporating gating mechanisms, which are crucial for controlling memory retention and forgetting. These gating modules require additional training and often fail to leverage pre-trained weights, reducing efficiency.
To solve this, Liger introduces a new method for linearizing Transformer-based LLMs into gated recurrent structures. It repurposes redundant weights from pretrained models to construct gating mechanisms without adding new parameters, making the transition smoother. Liger also introduces Liger Attention, a hybrid approach that combines sliding window softmax attention with linear recurrent modeling, retaining softmax's non-linearity while ensuring linear-time efficiency.
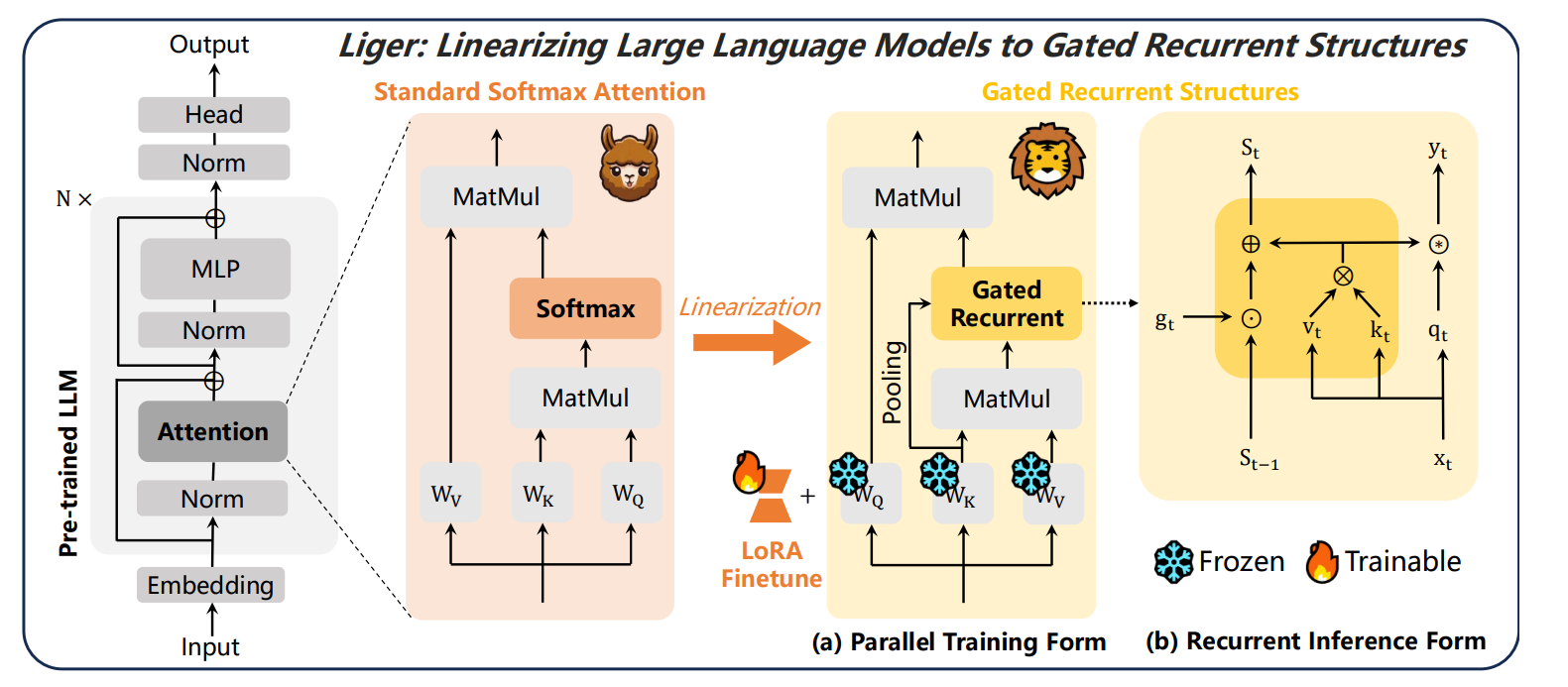
Applying Liger to models like Llama 3 (1B to 8B parameters) shows that it outperforms existing methods like SUPRA, MambaInLlama, and LoLCATs, preserving LLM performance while significantly improving efficiency.
Their code is here:
GitHub: OpenSparseLLMs/Linearization
Large-Scale Data Selection for Instruction Tuning
Instruction tuning has become a key step in training LLMs, with high-quality data selection proving to be more effective than simply using large datasets. Research shows that even 1,000 carefully chosen samples can outperform models trained on much larger but noisier datasets. However, scaling data selection techniques to larger datasets remains a challenge, as many existing methods struggle with efficiency and performance when selecting from millions of samples.
This study explores how well different data selection techniques perform when choosing instruction-tuning data from massive data pools, including those used in TÜLU 2 and TÜLU 3, state-of-the-art instruction-tuned models.

These datasets contain millions of samples of varying quality, requiring scalable selection methods that can filter noise while preserving diversity for generalization. The research evaluates nine different data selection approaches, including gradient-based influence methods, embedding-based methods, and loss/perplexity-based methods, across tasks like code generation (HumanEval) and general chat (AlpacaEval).
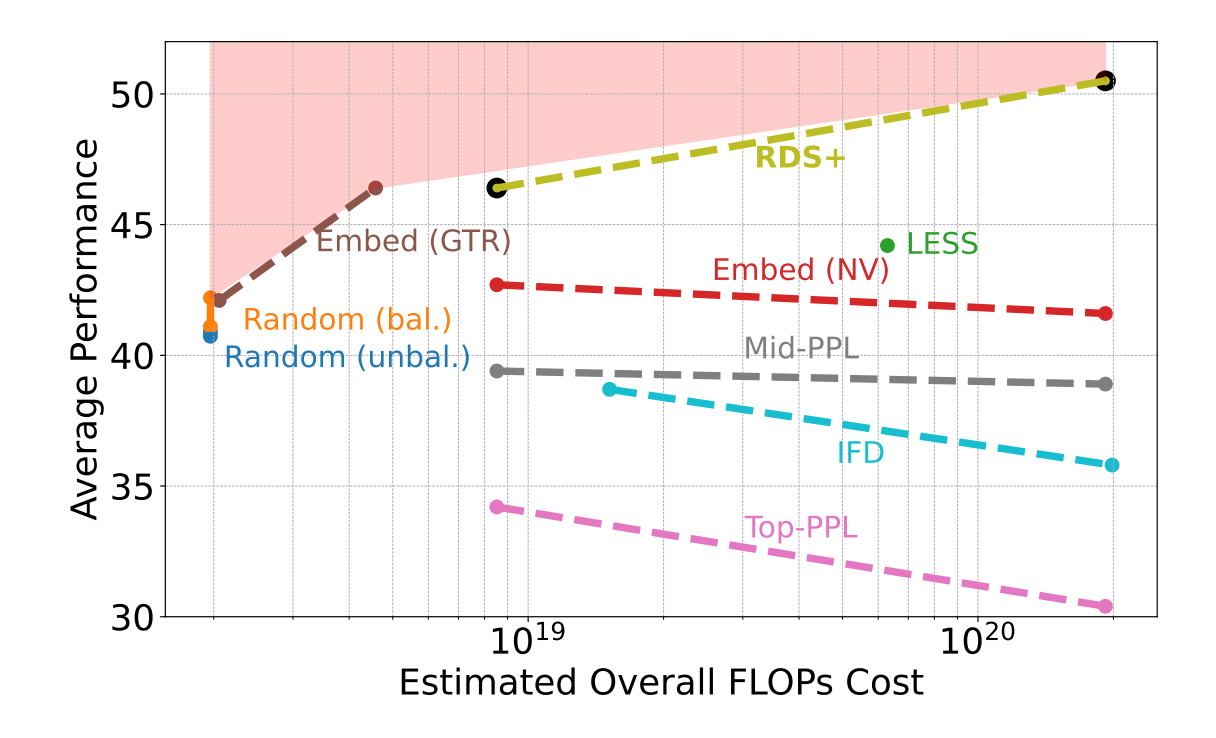
Surprisingly, the best-performing method is a simple embedding-based approach that leverages hidden states from a pretrained LM. This method consistently outperforms all other techniques across different dataset sizes and tasks. Key findings include:
Many selection methods lose effectiveness as dataset sizes grow, while RDS+ improves with scale, outperforming all others by at least two points on average.
RDS+ is also the best method for selecting data for multiple tasks, outperforming TÜLU 2, which was trained on a human-curated dataset.
RDS+ remains more compute-efficient than prior methods when selecting from hundreds of thousands to millions of samples, contradicting earlier studies that only tested on smaller datasets.
These results suggest that data selection techniques are most useful at larger scales, where they can significantly improve LM training efficiency.
They released their code here: