
LoRA's Scaling Factor (Alpha): Still Misunderstood?
The Weekly Salt #122


This week, we review:
Rethinking the Role of Efficient Attention in Hybrid Architectures
Variable-Width Transformers
The Hidden Power of Scaling Factor in LoRA Optimization
Rethinking the Role of Efficient Attention in Hybrid Architectures
The paper asks a mechanistic question behind modern hybrid LLMs: in architectures mixing full attention with efficient modules such as SWA (e.g., GPT-OSS), Lightning Attention, Mamba-2 (e.g., Nemotron 3), or Gated DeltaNet (e.g., Qwen3.5), do the efficient modules actually provide long-context capability, or do they merely change how full-attention layers learn?
Hybrid attention is now common for long-context efficiency, but prior work mostly reports end metrics or isolated ablations rather than explaining training dynamics and capability emergence.
Methodologically, they run a controlled scaling-law study over a full-attention baseline and six layer-wise hybrids: SWA with 128/512/2048 windows plus three recurrent mixers. Models span S1–S5, up to 665M total parameters, are pretrained at 16K context, and are assessed with validation loss for short-context modeling and LongPPL as a continuous proxy for long-context capability. The key empirical pattern is that validation-loss curves largely overlap across architectures, while LongPPL differs strongly in low-data regimes but converges with sufficient training.
The central mechanistic claim is that efficient attention is not the primary carrier of long-range information. Full attention is. They support this with inference-time receptive-field restriction, where constraining full attention hurts LongPPL much more than constraining efficient modules, and with layer-wise NIAH probing, where long-range information gains concentrate in full-attention layers.
They then explain different convergence speeds via “Large-Window Laziness”: large SWA windows satisfy much of the local next-token signal, weakening gradients that would otherwise force full-attention layers to develop retrieval heads. Gradient-influence profiling and checkpoint-level retrieval-head tracing show SWA-2048 has slower retrieval-head sharpening and slower Q/K convergence than smaller-window or recurrent hybrids.
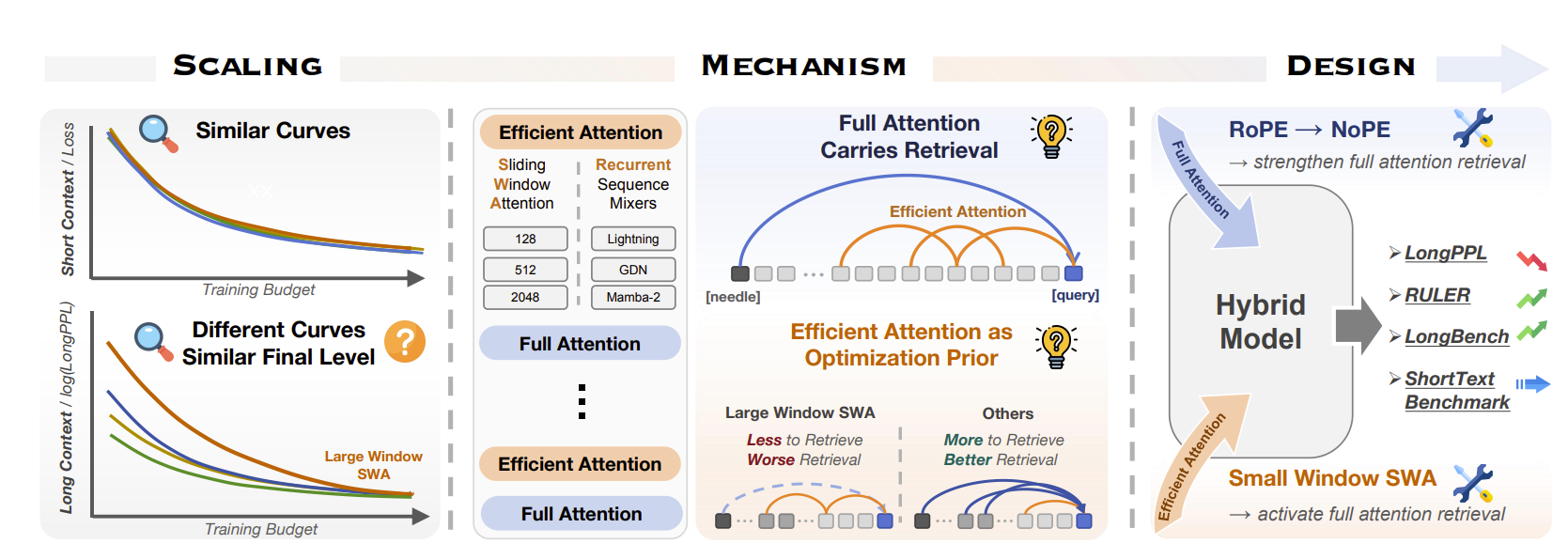
The proposed design implication is to optimize the hybrid around full-attention retrieval rather than making efficient modules “stronger.” Their concrete intervention is SWA-128-NoPE: use small-window SWA to keep pressure on full attention, and apply NoPE only in full-attention layers to improve long-range retrieval.
Evaluation is intentionally secondary here: SWA-128-NoPE improves RULER/NIAH and LongBench at 16K/32K while keeping short-context averages essentially unchanged, but the authors note the experiments remain sub-billion-scale and may not fully transfer to frontier-scale training recipes.
The paper targets a largely implicit design assumption in decoder-only Transformers: once a global hidden size is chosen, every block gets the same residual width and roughly the same capacity. The authors argue this is not obviously optimal because different depths perform different computational roles, and because parameter-matched variable-width models can have lower average per-layer width, reducing attention-side compute and KV-cache footprint.
The proposed architecture, > <former, uses a variable-width, X-shaped depth profile: early and late layers are wide, while middle layers form a bottleneck. The key implementation choice is to keep a fixed global residual stream, equal to the widest layer, while each Transformer block reads from and writes to only a layer-specific slice. Coordinates inactive in a narrow block bypass it and are copied forward. When width expands again, previously active coordinates are restored rather than learned through projection. This makes width changes parameter-free and preserves a skip-path interpretation instead of inserting learned residual adapters.
Width schedules are generated geometrically and controlled mainly by bottleneck location and bottleneck width. The authors sweep several global shapes and find the X-shaped profile works best, then use a ratio-based recipe with the bottleneck around three quarters through depth and about 30% of the baseline hidden width. Ablations indicate the carry-forward residual mechanism is important: zero padding is worse, and learned projection for expanded dimensions is worse still at the tested scale.
Evaluation is on dense LMs from 200M to 2B parameters and a 3B-total/1B-active MoE, trained on DCLM with constant-width baselines. > <former improves language-modeling loss across tested sizes while using lower pretraining FLOPs and lower average layer width; loss-matched scaling fits imply about 22% fewer FLOPs and about 15% lower average width. Zero-shot downstream results are strongest on perplexity metrics; NLU accuracy is mostly favorable for the 2B dense model and mixed for MoE.
The Hidden Power of Scaling Factor in LoRA Optimization
One more paper to discuss LoRA’s alpha.
The paper argues that LoRA’s scaling factor, alpha, has been mischaracterized as just another way to scale the learning rate. The authors’ motivation is that common LoRA practice fixes alpha through simple rank-tied heuristics, then compensates with unusually large learning rates. They claim this hides the real optimization bottleneck. Their empirical sweeps suggest that LoRA’s low-rank parameterization suppresses the effective curvature spectrum, making the landscape smoother but also leaving standard settings underpowered.
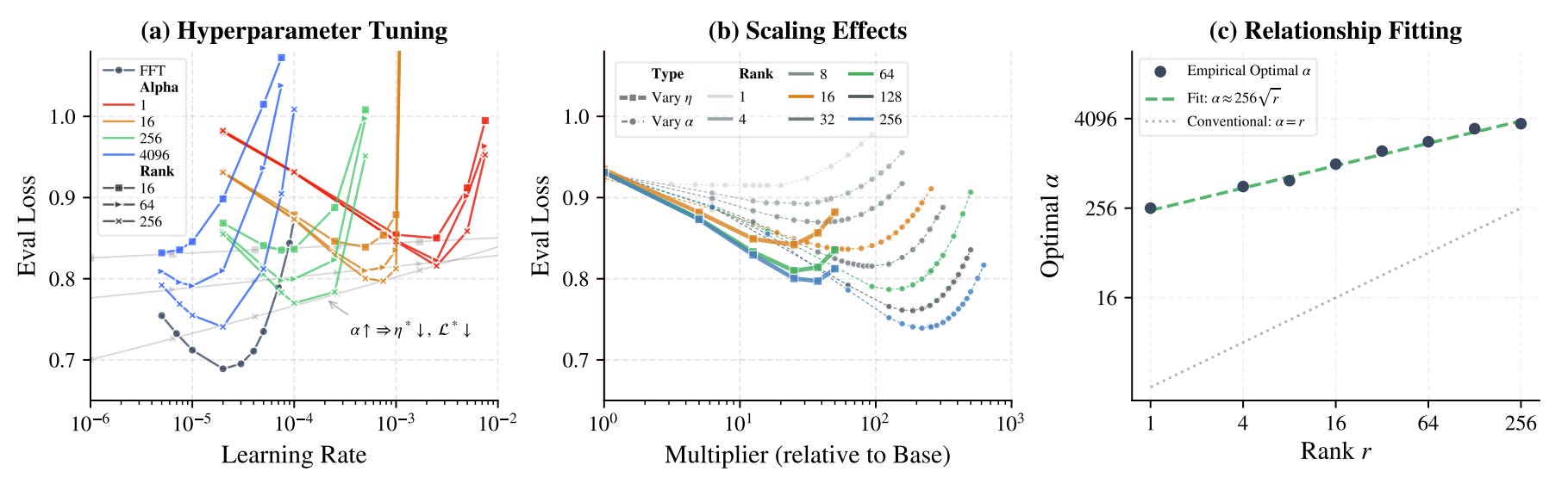
The core analysis is a “Signal-Drift” view of LoRA optimization. They decompose LoRA’s induced weight-space dynamics into a task-aligned signal term and a structural drift term caused by the bilinear adapter parameterization. In this framing, the learning rate and alpha are not interchangeable: increasing the learning rate scales both useful signal and destabilizing drift, while increasing alpha preferentially restores task-aligned curvature and preserves a better signal-to-drift profile under adaptive optimizers.
The proposed method, LoRA-α, is minimal: keep the standard small full-finetuning-style learning rate, and set alpha much larger than conventional LoRA defaults using either an empirical LLM-oriented sublinear rank rule or an analytic layer-wise rule derived from curvature alignment at initialization. The practical goal is to decouple capacity restoration from optimizer step-size tuning: alpha handles the curvature/signal restoration, while the learning rate remains conservative. Any remaining tuning is confined to a narrow scaling multiplier around the proposed alpha.
Evaluation is broad but secondary to the paper’s argument: they test encoder, decoder, diffusion, and vision-language models across supervised, contrastive, flow-matching, and RL settings. LoRA-α generally improves over vanilla LoRA and other LoRA variants, with gains stronger at higher ranks. In long-context reasoning SFT it is reported as the closest LoRA-style approximation to full fine-tuning.