


MaltMul-Free LLMs and Neural Algorithmic Reasoners
The Weekly Salt #22


Reviewed this week
⭐Scalable MatMul-free Language Modeling
Turbo Sparse: Achieving LLM SOTA Performance with Minimal Activated Parameters
Transformers meet Neural Algorithmic Reasoners
MaskLID: Code-Switching Language Identification through Iterative Masking
⭐: Papers that I particularly recommend reading.
New code repositories:
I maintain a curated list of AI code repositories here:
Scalable MatMul-free Language Modeling
I often review papers describing alternative neural architectures such as Jamba and RWKV.


This work goes further by completely removing all the MatMul operations.
In deep learning, matrix multiplication (MatMul) operations are computationally expensive, consuming most of the execution time and memory during training and inference.
Previous works have proposed to replace MatMul with simpler operations using two main strategies. The first strategy substitutes MatMul with elementary operations, such as AdderNet, which uses signed addition instead of multiplication in convolutional neural networks (CNNs) for computer vision tasks. The second approach involves binary or ternary quantization, simplifying MatMul to operations where values are either flipped or zeroed out before accumulation. This method can be applied to activations or weights, as seen in spiking neural networks (SNNs) and binary/ternary neural networks (BNNs and TNNs).
Recent advancements in language modeling, like BitNet, have demonstrated the scalability of quantization by replacing all dense layer weights with binary/ternary values, supporting up to 3 billion parameters. However, BitNet retains the self-attention mechanism, which relies on an expensive matrix multiplication for forming the attention map. Despite efforts to optimize hardware efficiency on GPUs with specialized kernels and advanced memory access patterns, MatMul operations remain resource-intensive due to extensive data movement and synchronization.
In response, the authors developed the first scalable MatMul-free language model by using additive operations in dense layers and element-wise Hadamard products for self-attention-like functions. Ternary weights eliminate MatMul in dense layers, similar to BNNs, and an optimized Gated Recurrent Unit (GRU) relies solely on element-wise products, competing with state-of-the-art Transformers while eliminating all MatMul operations.

To demonstrate the hardware benefits, the authors provided an optimized GPU implementation and a custom FPGA accelerator.
Using fused kernels in the GPU implementation of ternary dense layers accelerated training by 25.6% and reduced memory consumption by up to 61% over an unoptimized baseline on GPU. Additionally, lower-bit optimized CUDA kernels increased inference speed by 4.57 times and reduced memory usage by a factor of 10 when the model was scaled up to 13 billion parameters. This work highlights how scalable, lightweight language models can reduce computational demands and energy use in real-world applications.

They released their code:
GitHub: ridgerchu/matmulfreellm
Turbo Sparse: Achieving LLM SOTA Performance with Minimal Activated Parameters
Recent LLMs typically use activation functions like GELU and Swish, but these functions do not significantly improve activation sparsity and are difficult to accelerate. ReLUfication replaces the original activation function with ReLU and continues pretraining. However, it often fails to achieve the desired activation sparsity and may degrade performance.
The failure of existing ReLUfication methods can be attributed to two main reasons. First, replacing SwiGLU with ReGLU is inefficient, only increasing sparsity from 40% to around 70%, indicating a need for deeper investigation into model architecture. Second, the limited diversity of pre-training data and insufficient training tokens result in incomplete capability recovery.
To address these issues, the authors propose an efficient activation function named dReLU. They applied dReLU in the pre-training of small-scale LLMs alongside SwiGLU. Their findings show that LLMs using dReLU match the performance of those using SwiGLU while achieving nearly 90% sparsity.

Additionally, they conducted a sparsity analysis on Mixture of Experts (MoE)-based LLMs and found that the feed-forward networks within the experts remain sparsely activated, similar to dense LLMs. This suggests an opportunity to accelerate inference speed by combining MoE techniques with ReLU-based sparse activation.
To validate their method, they implemented it on the Mistral-7B and Mixtral-47B models, converting them to TurboSparse-Mistral-7B and TurboSparse-Mixtral-47B, respectively. With the TurboSparse-Mistral-7B model, they increased the average sparsity of the FFN to 90%. With the TurboSparse-Mixtral-47B model, they improved sparsity from 75% to 97% by incorporating sparse neuron activations, significantly reducing FLOPs during inference.

Transformers meet Neural Algorithmic Reasoners
The current leading approach for modeling noisy text data relies on Transformer-based LLMs, which are known for their good natural language understanding but are also notably fragile with simple algorithmic tasks, especially when it comes to out-of-distribution generalization.
On the other hand, Graph Neural Networks (GNNs) are much better at these tasks and are often referred to as Neural Algorithmic Reasoners (NARs).
This paper introduces the TransNAR model, integrating the strengths of both technologies. The authors propose a hybrid architecture that merges the language understanding capabilities of a Transformer with the robust reasoning abilities of a pre-trained GNN-based NAR. In this setup, the Transformer uses the NAR to modulate its token embeddings in a high-dimensional space.
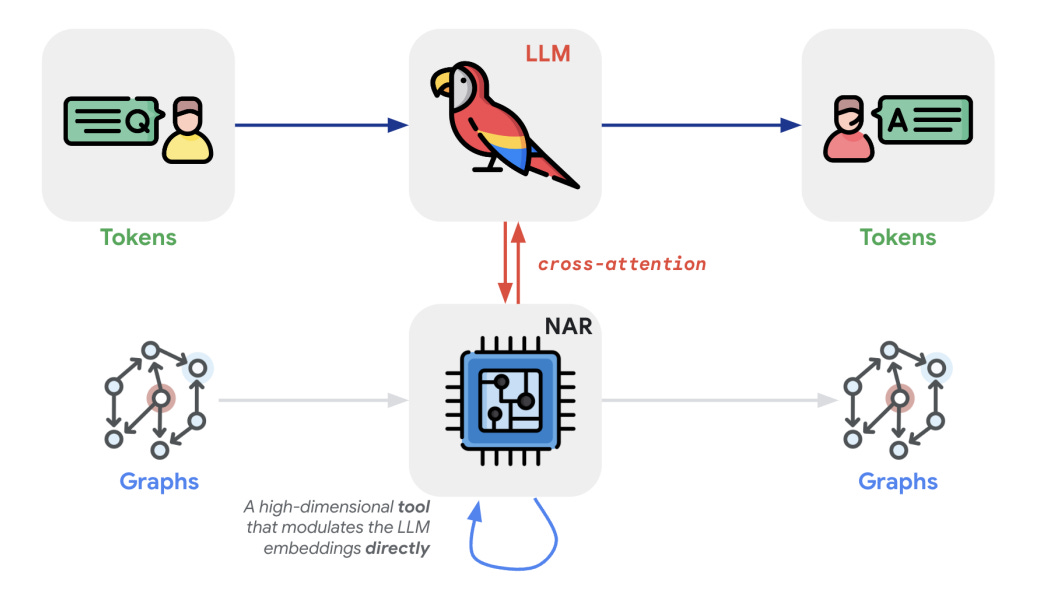
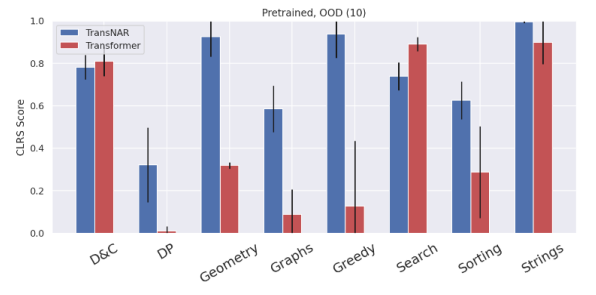
An evaluation on CLRS-Text, a text-based version of the CLRS-30 benchmark, shows that this NAR-augmented language model has better and more robust reasoning capabilities out-of-distribution.
MaskLID: Code-Switching Language Identification through Iterative Masking
Code-switching is the use of different languages in the same text.
Previous research on code-switching (CS) language identification (LID) has primarily focused on developing word-level LIDs for specific pairs of languages, usually limited to recognizing only two languages. These methods are impractical for broader applications.
This research proposes a new method called MaskLID, which also employs high-quality sentence-level LID to identify CS segments. By masking text features associated with the dominant language, MaskLID enhances the recognition of additional languages.
This method works with two existing FastText-based LIDs.
MaskLID can identify any pair of languages and detect mixtures of more than two languages within the same segment.
The effectiveness of MaskLID is demonstrated on two test datasets containing both CS and monolingual data.
GitHub: cisnlp/MaskLID
If you have any questions about one of these papers, write them in the comments. I will answer them.