

Reviewed this week
Self-Improving Robust Preference Optimization
⭐Mixture-of-Agents Enhances Large Language Model Capabilities
PLaD: Preference-based Large Language Model Distillation with Pseudo-Preference Pairs
Buffer of Thoughts: Thought-Augmented Reasoning with Large Language Models
⭐: Papers that I particularly recommend reading.
New code repositories:
There is no new code repository this week. The team behind the Mixture-of-Agents plans to release their code. It should be very interesting. They provided a repository link but it yields a 404 error for now.
I maintain a curated list of AI code repositories here:
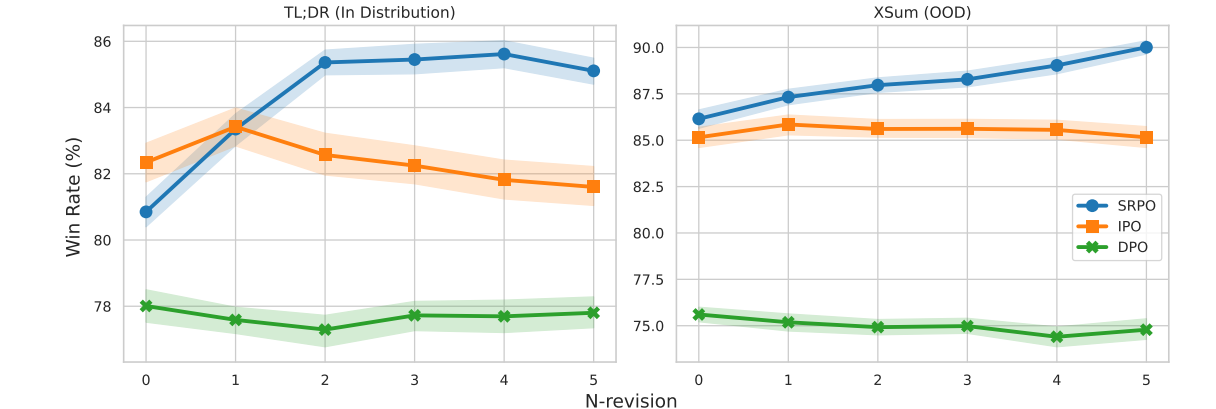
Self-Improving Robust Preference Optimization
This paper by Cohere introduces an alternative approach for aligning LLMs with human preferences, built on more principled and robust foundations. The objective is to develop a solution that remains robust to changes in the preference dataset, meaning that variations in the distribution of sampled completions do not significantly impact the learning outcome.
This approach leverages the concept of self-improving language models, which are capable of recursively improving their outputs with each inference iteration.
The Self-Improving Robust Preference Optimization (SRPO) method involves two sequential optimization processes.
The first step consists of an in-context self-improving preference optimization. The main idea is to develop a model capable of improving its outputs. When given a context and an initial completion, this self-improving model generates a better completion. It determines which new completion is preferred over the initial one according to human preferences. This problem can be clearly defined and solved using established methods from supervised learning, making the improvement process straightforward and reliable.
The second step is robust preference optimization. This step involves using the self-improvement policy learned in the previous step to train a generative LLM. The best generative policy is identified as one that generates completions requiring minimal improvement by the optimal self-improvement policy. This objective is minimized with respect to the generative policy for in-context completions.
The solutions for both steps can be estimated jointly through a single supervised direct preference optimization scheme using only a dataset of annotated pair-wise completions. Thus, both the self-improvement policy and the generative policy can be determined by minimizing the SRPO's supervised learning objective.
The fact that SRPO doesn’t need a separate dataset for supervised fine-tuning makes it very simple and similar to ORPO.

They only compared SRPO with DPO and IPO. They found that SRPO leads to better results.

⭐Mixture-of-Agents Enhances Large Language Model Capabilities
The research explores whether the collective expertise of multiple LLMs can create a more capable and robust model.
The answer is affirmative. An LLM generates better responses when presented with outputs from other models, even if those models are less capable individually. Evidence from the AlpacaEval 2.0 benchmark shows that the win rates of six popular LLMs significantly improve when they are provided with answers generated by other models.
Based on this finding, the paper introduces the Mixture-of-Agents (MoA) methodology, which leverages multiple LLMs to iteratively improve the generation quality. Initially, LLMs in the first layer independently generate responses to a given prompt. These responses are then refined by LLMs in the subsequent layer, with this iterative process continuing until a more robust response is obtained.
Models with higher win rates are chosen for subsequent layers, and the diversity of model outputs is emphasized to improve response quality.

Using benchmarks such as AlpacaEval 2.0, MT-Bench, and FLASK, the authors demonstrate substantial improvements with the MoA methodology. The MoA framework achieves a win rate of 65.8% on AlpacaEval 2.0, surpassing the previous best of 57.5% by GPT-4 Omni.

They will release their code here:
GitHub: togethercomputer/moa
PLaD: Preference-based Large Language Model Distillation with Pseudo-Preference Pairs
In this work, a new framework called Preference-based Large Language Model Distillation (PLaD) is introduced for distilling knowledge from LLMs using preference datasets.
PLaD is based on the observation that sequences generated by a teacher model generally surpass those of a student model in quality. By sampling outputs from both models, PLaD creates pseudo-preference pairs and calculates a ranking loss that adjusts the student's sequence likelihoods.
This approach recognizes the complex interactions between teacher and student models, focusing the student's learning on understanding the relative quality of outputs without strictly relying on teacher forcing, which addresses the student's expressivity limitations.
The framework also introduces a calibration loss that links the quality of generated outputs to their likelihood, optimizing output quality through calibration. This method eliminates the need for internal access to the teacher model and provides an annotation-free way to construct preference pairs based on the capacity gap between teacher and student models.

PLaD was evaluated on tasks such as Anthropic helpful dialogue generation and Reddit TL;DR summarization using models like Llama 2 and GPT-NeoX. The student model trained with PLaD outperformed those trained with other state-of-the-art knowledge distillation methods in terms of the win rate of generated sequences.

Buffer of Thoughts: Thought-Augmented Reasoning with Large Language Models
The Buffer of Thoughts (BoT) is a new framework designed to improve the reasoning accuracy, efficiency, and robustness of LLMs.
The framework includes a meta-buffer, a lightweight library containing a collection of universal high-level thoughts (thought-templates), which can be shared across tasks. For each problem, a relevant thought-template is retrieved and instantiated with a specific reasoning structure for efficient thought-augmented reasoning.
The framework is easier to understand from this figure:

To ensure the scalability and stability of BoT, a buffer-manager is introduced to dynamically update the meta-buffer. This method has three key advantages: it improves accuracy by reusing thought-templates, increases efficiency by leveraging historical reasoning structures without complex multi-query processes, and improves robustness by enabling LLMs to address similar problems consistently.
The empirical experiments show that BoT significantly improves precision, efficiency, and robustness across a wide range of tasks. The proposed framework outperforms previous state-of-the-art methods.
If you have any questions about one of these papers, write them in the comments. I will answer them.