
Mixture-of-Experts: Mixture-of-Head Attention and Embedding Model
The Weekly Salt #40


Reviewed this week:
⭐Your Mixture-of-Experts LLM Is Secretly an Embedding Model For Free
JudgeBench: A Benchmark for Evaluating LLM-based Judges
Rethinking Data Selection at Scale: Random Selection is Almost All You Need
MoH: Multi-Head Attention as Mixture-of-Head Attention
⭐: Papers that I particularly recommend reading.
New code repositories (list of all repositories):
Get a subscription to The Salt, The Kaitchup, The Kaitchup’s book, and multiple other advantages by subscribing to The Kaitchup Pro:
Your Mixture-of-Experts LLM Is Secretly an Embedding Model For Free
With LLM2Vec, we can already extract an embedding model from LLMs. I showed how to use it here:

Now, we can do something similar with MoEs.
MoE has become increasingly important in LLMs. The key to MoE’s effectiveness is its dynamic routers, which assign each input to the most relevant expert, optimizing computation efficiency and accuracy.
However, most MoE-based LLMs, designed for autoregressive next-token prediction, may not capture all relevant input features. Their hidden states (HS) can be biased towards future predictions rather than fully representing the input, which is a limitation when extracting embeddings for tasks like classification. This leads to a question: can high-quality embeddings be extracted from pre-trained LLMs without additional fine-tuning? The paper answers "yes," discovering that routing weights (RW) in MoE can complement HS by capturing intermediate reasoning choices and enriching input information.
The authors propose MoE Embedding (MOEE), which combines RW and HS to create an embedding model. This combination improves embedding tasks by integrating both output-dependent and input-sensitive information. Two strategies are explored: concatenation and a weighted sum of RW and HS similarities, with the latter yielding the best results.
The authors released their code here:
GitHub: tianyi-lab/MoE-Embedding
JudgeBench: A Benchmark for Evaluating LLM-based Judges
The paper addresses the growing need for reliable methods to evaluate LLMs, particularly those used as judges for evaluating other LLMs. Human judgments have been the gold standard for evaluating models, but this approach is costly, especially for complex tasks like code verification or mathematical proofs. To address this limitation, LLM-based judges have emerged as scalable alternatives, used to rank models, guide training, and select the best responses during inference.
However, the reliability of these LLM-based judges is questioned due to their susceptibility to making factual and logical mistakes, just like the models they evaluate. Prior works have focused on aligning LLM judges with human preferences, but this approach assumes that human annotators are always objective, which is often not the case for complex tasks. This paper proposes a hierarchical framework to guide LLM-based judges in selecting responses based on three principles: (1) faithful instruction following, (2) factual and logical accuracy, and (3) stylistic alignment with human preferences. Importantly, factual correctness should take precedence over stylistic preferences.

To improve LLM-based judging, the paper introduces JudgeBench, a benchmark designed to test LLM judges on difficult response pairs requiring advanced reasoning. The benchmark is created through a pipeline that converts any dataset with ground truth labels into one suitable for evaluating LLM-based judges. The dataset includes 350 challenging response pairs in categories like general knowledge, reasoning, mathematics, and coding, where the incorrect responses contain subtle errors, making them hard to distinguish from correct ones.
The evaluation code and data are available here:
GitHub: ScalerLab/JudgeBench
Rethinking Data Selection at Scale: Random Selection is Almost All You Need
The paper discusses Supervised Fine-Tuning (SFT) for LLM and focuses on improving instruction-following capabilities, intent comprehension, and text generation. While LLMs aim to generalize to a wide range of tasks, fine-tuning with domain-specific data is often necessary. Recent studies explore data selection strategies for SFT, categorized into external-scoring methods (requiring external models like GPT-4) and self-scoring methods (where LLMs score the data themselves).
Existing SFT methods primarily use small, single-source datasets, but real-world applications often require large, diverse datasets. The paper finds that, as dataset sizes increase to millions of examples, current selection methods perform worse than random selection, particularly when dealing with large-scale, multi-source data.
The study identifies three key findings:
Self-scoring techniques show diminishing returns on large datasets, performing better on small, single-source datasets but losing effectiveness as scale increases.
Data diversity becomes more important than data quality in large-scale SFT. While quality is crucial for small datasets, diversity is essential for large, complex datasets.
Length filtering is a practical criterion for improving SFT on large datasets. Training models with long texts improve performance on both subjective and objective evaluation tasks.
The paper suggests that current SFT data selection methods need reconsideration when applied to large, multi-source datasets, and highlights the benefits of focusing on data diversity and token length in large-scale SFT.
MoH: Multi-Head Attention as Mixture-of-Head Attention
This paper introduces Mixture-of-Head attention (MoH) to improve transformer models' multi-head attention mechanism. While multi-head attention has been the standard, not all attention heads are equally significant, and some can be pruned without affecting performance. This suggests redundancy in multi-head attention architectures.
MoH integrates multi-head attention with the Mixture-of-Experts (MoE) mechanism, treating attention heads as experts. A dynamic routing mechanism is introduced, where tokens select the most relevant heads, improving both inference efficiency and model performance without increasing the parameter count. Additionally, MoH replaces the standard summation of attention heads with a weighted summation for more flexibility and performance potential.
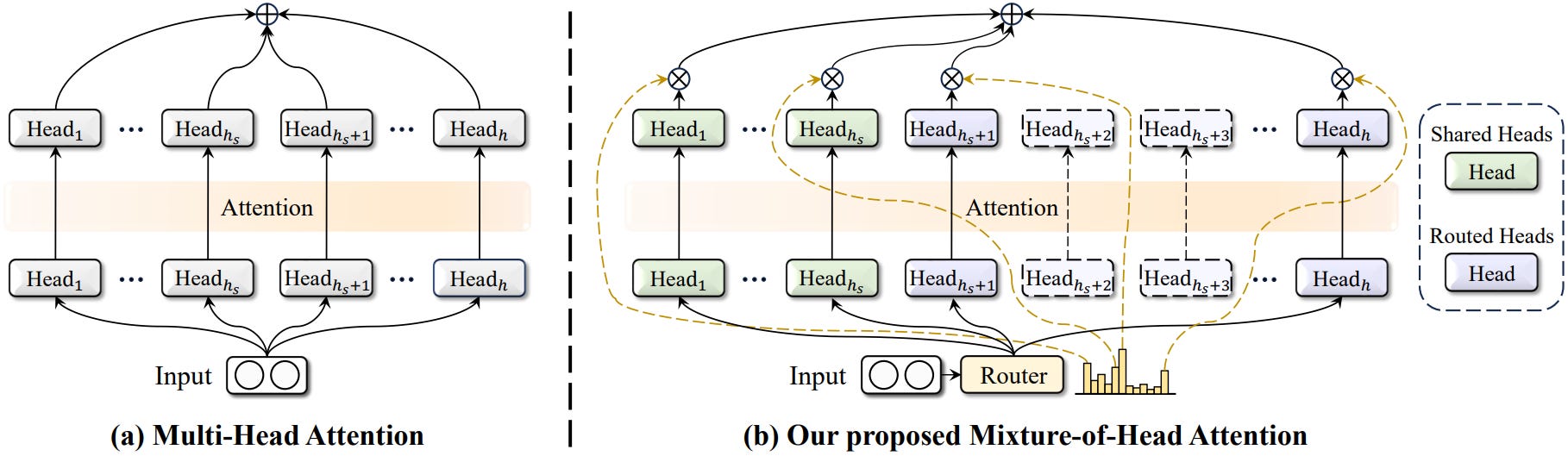
The paper shows MoH’s effectiveness across different model frameworks, including Vision Transformers (ViT), Diffusion models with Transformers (DiT), and LLMs. MoH achieves competitive or superior performance compared to standard multi-head attention using fewer attention heads (50%-90% of the heads). For example, in image classification, MoH surpasses well-tuned baselines with fewer heads.
MoH also shows that pre-trained models can be further tuned to adopt the MoH architecture.
The code of MoH is available here:
GitHub: SkyworkAI/MoH