
MMBERT as a Drop-in Successor to XLM-R
The Weekly Salt #86


This week, we review:
⭐mmBERT: A Modern Multilingual Encoder with Annealed Language Learning
GAPrune: Gradient-Alignment Pruning for Domain-Aware Embeddings
Single-stream Policy Optimization
⭐mmBERT: A Modern Multilingual Encoder with Annealed Language Learning
MMBERT is a ModernBERT-style multilingual encoder trained on roughly 3T tokens spanning 1,833 languages, built to refresh the aging XLM-R line of encoders. Two training twists drive it: an inverse masking schedule that lowers the MLM mask rate as training progresses (30% → 15% → 5%), and Cascading Annealed Language Learning that expands the language set across phases (≈60 → 110 → 1,833) while annealing the sampling temperature from high-resource–biased to more uniform.
Hundreds of low-resource languages are only introduced in the short decay phase, letting the model piggyback on a strong multilingual base and extract large gains from relatively little data.
Architecturally, it mirrors ModernBERT (FlashAttention2, unpadding, 8k context, RoPE) with a Gemma-2 tokenizer, offered in small (~140M total; ~42M non-embed) and base (~307M total; ~110M non-embed) sizes.
Training runs in three stages: 2.3T tokens of pretraining, 600B mid-training that upgrades data quality and extends context to 8k, then a 100B decay with very low masking and three data mixtures (English-heavy, 110-lang, and 1,833-lang). The best checkpoints from these mixtures are merged (TIES-merging for base) to blend strengths. The data mix leans on higher-quality public corpora (FineWeb2/HQ, filtered DCLM/Dolma, MegaWika, ArXiv, books, instructions, some code).
On benchmarks, MMBERT consistently surpasses XLM-R and mGTE for both English and multilingual NLU and retrieval; the base model even ties ModernBERT on English MTEB-v2 retrieval while remaining multilingual.
The late-stage language annealing seems to pay off: adding Tigrinya and Faroese only during the 100B-token decay phase yields big jumps on TiQuAD and FoQA, with scores that edge out much larger decoder LMs like OpenAI’s o3 and Google’s Gemini 2.5 Pro on those tasks.
GAPrune: Gradient-Alignment Pruning for Domain-Aware Embeddings
GAPrune targets a practical gap in domain-specific embedding models: large LLM-based embedders capture specialized semantics but are hard to deploy, while standard pruning treats all weights uniformly and either erases domain knowledge or harms general linguistic ability. The method reframes pruning as a domain-aware selection problem. It scores parameters by both their importance to the target domain and how well they align with general-language objectives, aiming to keep weights that serve the domain without breaking foundational semantics.
The pipeline uses two small, representative datasets, general and domain, built from contrastive triplets. For each parameter, GAPrune computes Fisher Information on domain data (importance) and on general data (to penalize domain-irrelevant reliance), plus a cross-domain gradient alignment via cosine similarity between averaged gradients from the two datasets. These signals are fused into a Domain-Alignment Importance (DAI) score: a Fisher-dom term minus a β-weighted Fisher-gen term, scaled by weight magnitude (with a small magnitude prior), then modulated by (1+α·alignment). Pruning keeps the top-k DAI-scored parameters in a one-shot pass, and the pruned model can optionally be lightly retrained.
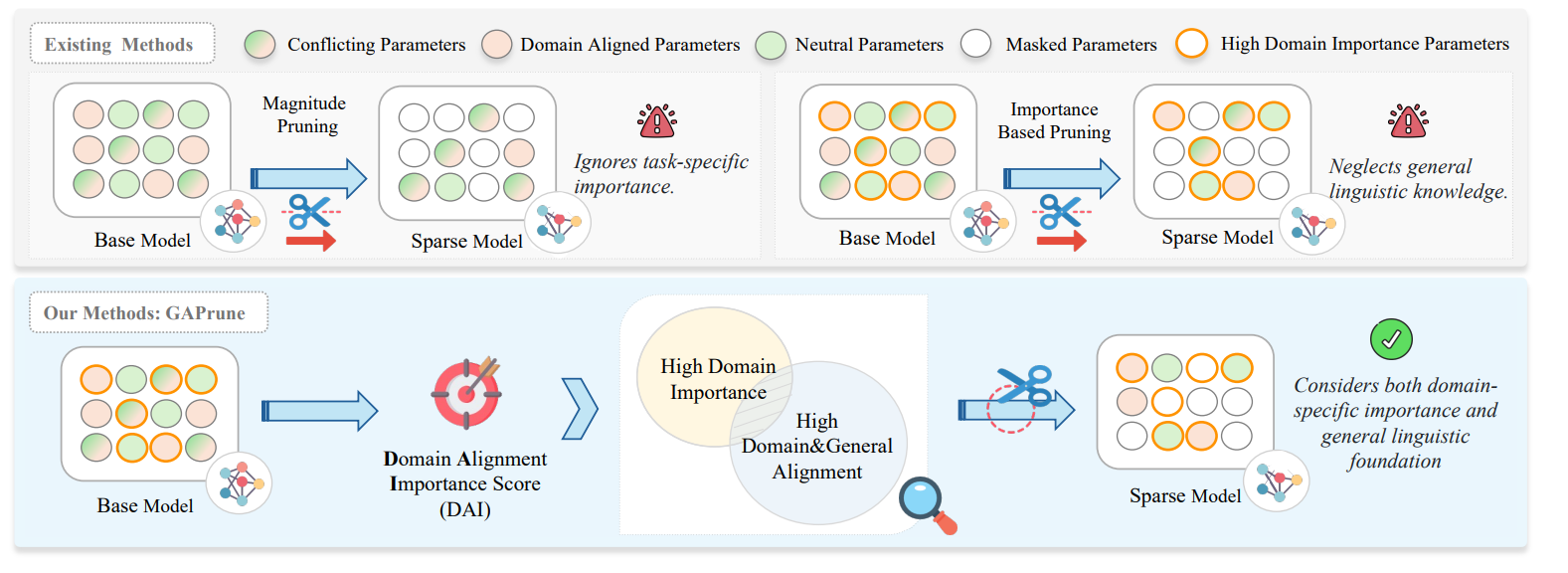
On FinMTEB (finance) and ChemTEB (chemistry) with Qwen3-Embedding-4B and E5-mistral-7B-Instruct, GAPrune beats magnitude and Fisher baselines at both 30% and 50% sparsity. In one-shot at 50% sparsity, it stays within ~2.5% of dense on both domains, whereas Fisher-only variants degrade sharply (e.g., >30% drop on FinMTEB for General Fisher in one-shot). With just 100 post-pruning training steps, Qwen3-Embedding-4B surpasses dense by +4.51% on FinMTEB and +1.73% on ChemTEB, and outperforms a layer-pruning baseline (L³ Prune). Results are consistent across architectures, suggesting the DAI criterion captures model-agnostic signals of domain utility and cross-domain compatibility.
Ablations and diagnostics indicate GAPrune selects a different subset of parameters than Fisher alone (negative correlation with Domain/General Fisher), prioritizes later layers crucial for retrieval, and yields better embedding geometry: lower alignment loss, higher cross-dimensional correlation and cosine similarity to dense, and higher effective dimensionality than Fisher-pruned models.
Single-stream Policy Optimization
Yet, another policy optimization method! But this one brings something new.
The paper argues that popular group-based RL methods for LLMs, especially GRPO, waste compute and scale poorly. When all samples in a group share the same outcome, advantages collapse to zero and no gradient flows, and in distributed setups every prompt waits for the group’s slowest rollout, which is disastrous for long-horizon or tool-using agents with highly variable latencies. Engineering fixes like dynamic sampling add complexity but not principle. The authors advocate returning to a single-sample (“single-stream”) policy-gradient view and design Single-stream Policy Optimization (SPO) to keep variance low without groups.
SPO swaps the on-the-fly group baseline for a persistent, KL-adaptive value tracker: for binary RLVR rewards, each prompt’s success probability is tracked with a discounted Beta posterior whose forgetting rate depends on the policy’s KL drift, yielding a low-variance, action-independent baseline. Advantages are then normalized globally across the batch (not per-prompt), and the same advantages drive a standard clipped-policy loss. Because the tracker is persistent, SPO naturally supports prioritized sampling: prompts near the decision boundary, high uncertainty under the tracker, are sampled more often, with a small exploration floor to avoid collapse. The result is a group-free pipeline that maintains stable gradients and removes synchronization barriers.
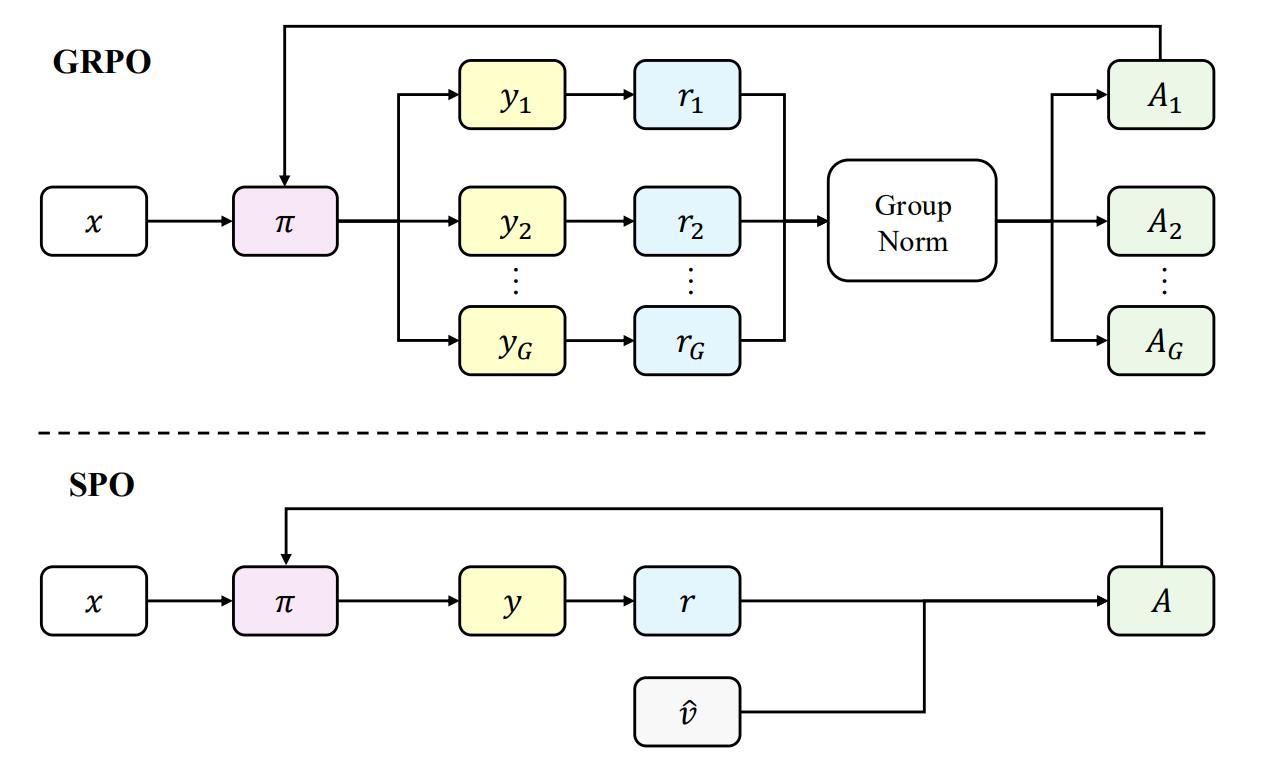
On Qwen3-8B with tool-integrated reasoning, SPO converges more smoothly and improves aggregate accuracy on five hard math benchmarks. The average maj@32 rises by +3.4 percentage points over GRPO (notably +7.3 on BRUMO 25, +4.4 on AIME 25, +3.3 on HMMT 25), and pass@k curves sit above GRPO across k. Signal-quality analyses show GRPO spends most samples in degenerate groups (often >60–80% over training), while SPO keeps producin informative gradients; unnormalized advantage variance under SPO’s baseline is markedly lower (≈50% reduction vs. raw-reward “no baseline”), whereas GRPO’s “effective” (non-degenerate) advantages are highly volatile.
For scalability, simulations modeling long-tail interaction times show the group-free design can assemble batches by collecting the first completed trajectories and ignoring stragglers, yielding a 4.35x throughput speedup compared to group-based batching. The authors position SPO as a simpler, more principled path: persistent value estimation plus batch-wide normalization and prioritized sampling, rather than ever-larger groups and ad-hoc heuristics, to push LLM reasoning and agentic training efficiently.