


Reviewed this week
NeedleBench: Can LLMs Do Retrieval and Reasoning in 1 Million Context Window?
⭐Spectra: A Comprehensive Study of Ternary, Quantized, and FP16 Language Models
Scaling Laws with Vocabulary: Larger Models Deserve Larger Vocabularies
LazyLLM: Dynamic Token Pruning for Efficient Long Context LLM Inference
⭐: Papers that I particularly recommend reading.
New code repositories:
I maintain a curated list of AI code repositories here:
NeedleBench: Can LLMs Do Retrieval and Reasoning in 1 Million Context Window?
To evaluate the long-context capabilities of LLMs, several approaches and datasets have been proposed. One prominent dataset is the LongBench dataset, which benchmarks long text comprehension in both Chinese and English with tasks ranging from 5,000 to 15,000 tokens. However, accurately assessing LLM performance at the scale of 1 million tokens remains a significant challenge.
The Needle In A Haystack (NIAH) test is now also a standard benchmark that extends the context window to 200,000 tokens. It is often used to evaluate methods extending LLM’s context.

However, the ability to pass the NIAH test does not necessarily indicate that LLMs can handle real-world long-context problems. Real-world tasks often require models to retrieve and integrate multiple pieces of dispersed, question-related information.
To address these limitations, the NeedleBench dataset was introduced in this paper. It aims to provide a comprehensive assessment of models' abilities to extract and analyze information within long texts. Additionally, the Ancestral Trace Challenge (ATC) test was developed as a simplified proxy to measure multi-step logical reasoning. Initial findings show that current LLMs struggle with complex logical reasoning tasks involving very long contexts.
The authors released their code here:
GitHub: open-compass/opencompass
⭐Spectra: A Comprehensive Study of Ternary, Quantized, and FP16 Language Models
Post-training quantization converts LLMs initially trained in a 16-bit (FP16/BF16) format to smaller bitwidths. In The Kaitchup, I reviewed many of these methods, e.g.:


Quantization lowers hardware requirements but can degrade performance at very low bitwidths.
An alternative approach involves training neural networks with low bitwidths from scratch, such as ternary networks. These networks offer compression benefits without the drawbacks of post-training quantization.
The Spectra LLM suite, introduced in this paper, includes models across multiple bit-widths, including post-quantized LLMs and ternary LLMs. This is the first work of this kind.
The Spectra suite demonstrates that ternary LLMs show stable training dynamics despite an extremely low bidwidth. Comparative evaluations of ternary LLMs and post-quantized LLMs reveal that ternary LLMs at the billion parameter scale consistently outperform their counterparts.
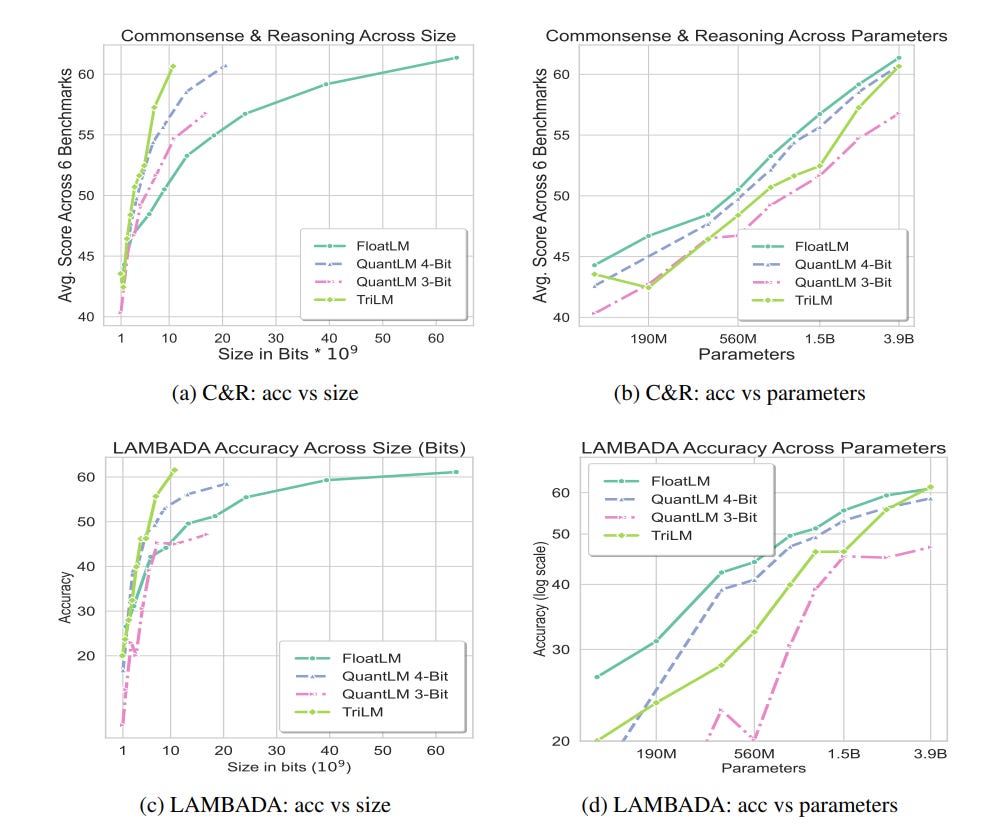
This work is more evidence that quantization-aware training outperforms post-quantization, especially for low bitwidths. However, quantization-aware training remains extremely costly as it requires pre-training from scratch.
Scaling Laws with Vocabulary: Larger Models Deserve Larger Vocabularies
The size of a model's vocabulary significantly influences its performance, requiring a balance between being too large or too small.
A larger vocabulary enhances tokenization efficiency and the model's ability to capture diverse concepts, but it can lead to under-fitting rare tokens, especially with limited data. Determining the optimal vocabulary size involves considering training data and non-vocabulary parameters.
This paper argues that the impact of vocabulary size on scaling laws has been underestimated. It introduces a normalized loss formulation to compare models with different vocabulary sizes and presents methods to predict the optimal vocabulary size based on computational budget. These methods reveal that optimal vocabulary parameters grow according to a power law but at a slower rate than non-vocabulary parameters.
Most current LLMs have suboptimal vocabulary sizes, with models like StarCoder2-3B and InternLM2-20B being closest to the optimal.

Empirical experiments on 3B parameter models confirm that using the suggested vocabulary sizes improves performance under various training conditions.
The authors released their code here:
GitHub: sail-sg/scaling-with-vocab
LazyLLM: Dynamic Token Pruning for Efficient Long Context LLM Inference
During the prefilling stage of language models, all tokens from the prompt are processed by all transformer layers, which can be slow for long prompts due to the complex neural architecture of modern models. “time-to-first-token” (TTFT) can be long due to prefilling. This stage can account for a significant portion of total generation time, especially for long sequences, making its optimization crucial for efficient model inference.
Research has largely focused on speeding up the decoding stage, with less attention on optimizing TTFT. Some methods indirectly improve TTFT by reducing model size, but direct optimization within a static transformer architecture has been less explored. Profiling shows that many prompt tokens are redundant and can be removed without affecting predictions while reducing TTFT.

The paper proposes LazyLLM, a technique that speeds up the prefilling stage by selectively computing key-value pairs for essential tokens and deferring the rest. This method prunes tokens based on their importance, determined by attention scores, and allows pruned tokens to be revived later if needed, maintaining accuracy. An auxiliary caching mechanism, Aux Cache, stores the hidden states of pruned tokens, ensuring efficient computation and preventing runtime slowdowns.
If you have any questions about one of these papers, write them in the comments. I will answer them.