
Multimodal Self-instruct and Leakage of Code Benchmarks
The Weekly Salt #26


Reviewed this week
⭐On Leakage of Code Generation Evaluation Datasets
Lookback Lens: Detecting and Mitigating Contextual Hallucinations in Large Language Models Using Only Attention Maps
Self-Recognition in Language Models
Multimodal Self-Instruct: Synthetic Abstract Image and Visual Reasoning Instruction Using Language Model
⭐: Papers that I particularly recommend reading.
New code repositories:
I maintain a curated list of AI code repositories here:
On Leakage of Code Generation Evaluation Datasets
As we saw in a previous article, data contamination is a significant problem in LLM evaluation.

In code generation, it is an even bigger problem as benchmarks for code generation are scarce, as demonstrated by this new work by Cohere.
Achieving competitive results on these benchmarks offers considerable scientific and economic benefits. However, this widespread use has led to data leakage and contamination beyond the intended evaluation scope, undermining their reliability.
If models are trained on or selected based on this evaluation data, it compromises the integrity of the evaluation.
Cohere presents evidence that contamination, defined here as any instance where evaluation datasets have leaked into model training, has affected most LLMs. The primary form of contamination occurs through the inclusion of these datasets in training data, which they demonstrate is likely.
Another form of contamination arises indirectly through the use of synthetic data, which is particularly common in improving code capabilities by generating additional training data. Additionally, what is common to all LLMs but good to always point out is that the final model selection is usually overly influenced by performance on these benchmarks, leading to overfitting in some way.
They also propose the Less Basic Python Problems (LBPP) benchmark, designed to be a more challenging, yet portable, code generation test set. They claim that they made it in a way that minimizes the risk of leakage.
Hugging Face dataset: CohereForAI/lbpp
Most prior studies addressing hallucinations in LLMs focus on scenarios where hallucinations stem from the models' inherent knowledge.
These approaches typically use LLM representations, such as hidden states, MLP outputs, and attention outputs, to detect and mitigate hallucinations. In contrast, contextual information is crucial for identifying contextual hallucinations, as attention maps provide a meaningful measure of the model's focus on the context during generation.
To leverage this, this work hypothesizes that contextual hallucinations are linked to how much an LLM attends to the provided context. They introduce the notion of "lookback ratio," calculated as the ratio of attention weights on the given context versus newly generated tokens. This ratio is computed for each attention head at every time step, and then they train a linear classifier, “Lookback Lens”, to detect contextual hallucinations based on these features.
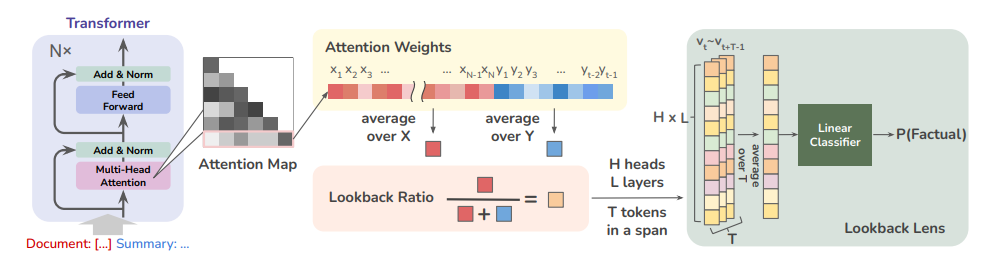
According to the authors, it performs comparably to, and sometimes better than, more complex hallucination detectors that use hidden states or entailment models trained on annotated datasets.
They released their tool to detect contextual hallucinations:
GitHub: voidism/Lookback-Lens
Self-Recognition in Language Models
Can LLMs recognize their own outputs among outputs generated by other LLMs?
This work explores whether similar questions can measure LM self-recognition. The process involves: instructing LMs to generate self-recognition questions, collecting answers from a panel of LMs, and prompting them to identify their own answers.
Testing ten state-of-the-art LMs, the authors found no consistent evidence of general self-recognition. LMs often preferred answers from "stronger" models over their own and exhibited consistent preferences for certain models. They also discovered that position bias significantly affects LM decision-making, with implications for LM benchmarks using multiple-choice formats.
LLMs have been shown to be particularly useful for generating synthetic data for training other LLMs. In The Salt, we already reviewed two different approaches for synthetic generation: Ada-instruct, which I found doesn’t perform very well, and Microsoft’s approach for instruction pre-training:


Phi LLMs are very good examples of very good small LLMs that were trained on synthetic data.

These approaches only generate synthetic text, for multimodal models, such as visual-language models (VLMs) we would need also to generate images.
The authors of this paper focus on tasks exploiting abstract images requiring reasoning. They propose a multi-modal self-instruct strategy designed to produce abstract images and aligned reasoning instructions for various everyday scenarios, including roadmaps, dashboards, 2D planar layouts, charts, relation graphs, flowcharts, and visual puzzles.

The process begins with the strategy autonomously proposing a creative idea for visual scenarios, such as using a step-by-step flowchart to demonstrate how to attend an academy conference or designing a roadmap. Then, it generates detailed instructions to visualize this idea. After synthesizing the desired image, LLMs self-instruct to generate high-quality Q&A pairs for this visual content. The entire process is fully completed by the LLM with minimal demonstration examples.
If you have any questions about one of these papers, write them in the comments. I will answer them.