


New Advances in Linear-time Sequence Modeling
The Weekly Salt #35


Reviewed this week:
⭐Source2Synth: Synthetic Data Generation and Curation Grounded in Real Data Sources
RetrievalAttention: Accelerating Long-Context LLM Inference via Vector Retrieval
Gated Slot Attention for Efficient Linear-Time Sequence Modeling
⭐: Papers that I particularly recommend reading.
New code repositories:
I maintain a curated list of AI code repositories here:
Source2Synth: Synthetic Data Generation and Curation Grounded in Real Data Sources
The authors propose Source2Synth, a scalable approach for generating synthetic data grounded in real-world sources, which improves task performance without human annotations.
Source2Synth involves three stages:
1. Dataset Generation: Real-world sources, such as web tables or Wikipedia articles, are used to generate synthetic examples. A seed topic is selected to condition the generation of instructions, reasoning steps, and answers.
2. Dataset Curation: The synthetic data is split into two slices. The first slice fine-tunes an LLM, which then curates the second slice using imputation (filling in blanks) and filtering (rejecting incorrect answers).
3. Model Fine-tuning: The curated dataset improves model performance in complex tasks.

The method is tested in two domains: answering tabular questions using SQL and multi-hop question answering.
I don’t know how well it works compared to previous works. Since they didn’t release any implementation or model, I still recommend generating data with open LLMs using the approach proposed by Microsoft:

RetrievalAttention: Accelerating Long-Context LLM Inference via Vector Retrieval
Recent LLMs have demonstrated an exceptional ability to process lengthy contexts, with models like Gemini 1.5 Pro supporting context windows of up to 10 million tokens. However, this capability introduces efficiency challenges due to the quadratic complexity of attention mechanisms, leading to significant GPU memory consumption and increased inference latency when using techniques like KV Caching.
To address these issues, the concept of leveraging dynamic sparsity in the attention mechanism is introduced. The paper proposes RetrievalAttention, an efficient method that uses Approximate Nearest Neighbor Search (ANNS) to dynamically identify and focus on the most critical tokens during token generation. This approach tackles the out-of-distribution problem between query and key vectors in traditional attention mechanisms by constructing a vector index tailored to the distribution of queries.

RetrievalAttention significantly reduces the need to access and store large amounts of key-value vectors by traversing only a small subset (1% to 3%) of key vectors. It offloads most KV vectors to CPU memory for indexing while keeping essential ones in GPU memory, optimizing both memory usage and latency. Evaluations on various long-context benchmarks show that RetrievalAttention maintains the accuracy of full attention models while achieving up to a 4.9× reduction in decoding latency. Notably, it enables running 8-billion-parameter models on a single 24GB GPU (like the NVIDIA 4090) with minimal accuracy loss and acceptable latency.
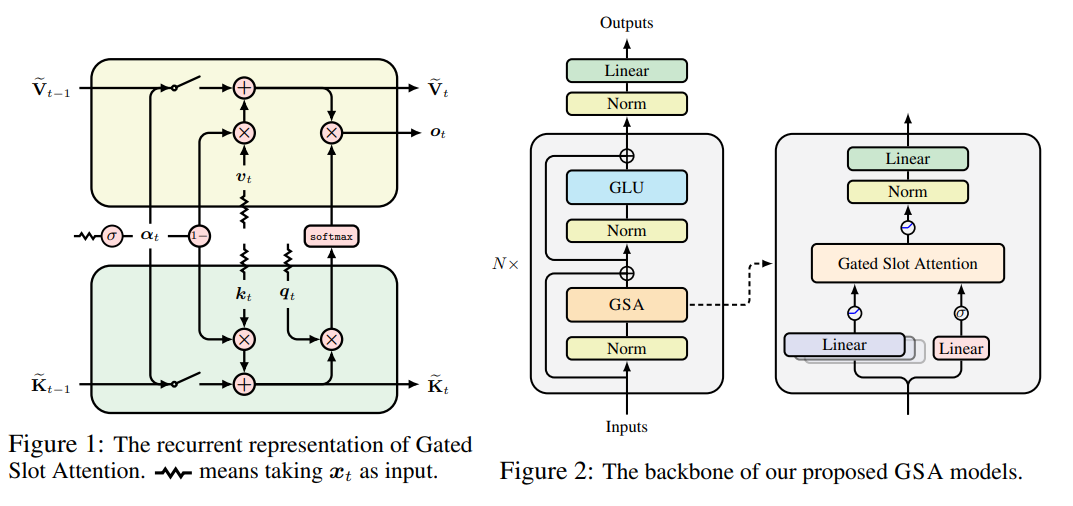
Gated Slot Attention for Efficient Linear-Time Sequence Modeling
This paper discusses the challenges of using Transformers, particularly with standard softmax attention (SA), for long sequence modeling tasks. While Transformers work well for moderate-length sequences, issues arise during inference as the Key-Value (KV) cache grows, creating memory and efficiency problems (as already discussed in the article above).
Linear (kernelized) attention and its gated variants have emerged as alternatives, offering constant memory complexity and improved inference efficiency. However, these models struggle with tasks requiring in-context retrieval and learning.

Recent attention has shifted toward a "fine-tuning pre-trained Transformers to RNNs" (T2R) approach to reduce training costs. However, linear attention models use different kernel methods than softmax, causing performance gaps when fine-tuning. To address this, the authors revisit the Attention with Bounded-Memory Control (ABC) model, which retains the softmax operation and reduces discrepancies during fine-tuning. ABC is efficient but has been limited by slow training and average language modeling performance.
The authors propose Gated Slot Attention (GSA), an enhanced version of ABC that incorporates gating mechanisms. GSA improves performance in language modeling and recall-intensive tasks without requiring large state sizes. In the T2R setting, fine-tuning the Mistral-7B model to GSA surpasses other recurrent language models and linear attention methods. GSA also achieves faster inference speeds and similar training speeds compared to other models, making it a more efficient solution for complex tasks.
They released their implementation here:
If you have any questions about one of these papers, write them in the comments. I will answer them.