
Pre-training LLMs of Multiple Sizes, Simultaneously
The Weekly Salt #29


Reviewed this week
Improving Text Embeddings for Smaller Language Models Using Contrastive Fine-tuning
ThinK: Thinner Key Cache by Query-Driven Pruning
⭐POA: Pre-training Once for Models of All Sizes
Towards Achieving Human Parity on End-to-end Simultaneous Speech Translation via LLM Agent
⭐: Papers that I particularly recommend reading.
New code repositories:
I maintain a curated list of AI code repositories here:
Improving Text Embeddings for Smaller Language Models Using Contrastive Fine-tuning
Text embeddings are vectorized representations of text that capture semantic meaning. These embeddings play a key role in various tasks, such as RAG.
This project is driven by the limited research on enhancing the text embedding capabilities of smaller models. For example, MiniCPM, a compact language model, struggles to produce high-quality text embeddings without additional fine-tuning. To address this issue, this research conducts experiments to enhance the quality of text embeddings generated by MiniCPM, making it a more viable option for resource-constrained scenarios. They especially focused on contrastive fine-tuning techniques such as the one I presented in this article:

They released their code here:
ThinK: Thinner Key Cache by Query-Driven Pruning
Inference costs with LLMs increase with model size and sequence length. Quantization and pruning techniques reduce the model size to make inference cheaper.
However, one of the primary challenges in managing these models is the quadratic complexity of the transformer attention mechanism, which becomes particularly costly when dealing with very long sequences.
Effective management of memory and computational costs during inference is crucial, particularly by addressing dimensions like sequence length, layers, heads, and channel size within the key-value (KV) cache.
In this context, previous approaches have focused on reducing costs by pruning dimensions such as sequence length and layers but have largely overlooked the channel dimension. This paper highlights the redundancy in the channel dimension of the key cache, noting that the magnitude across these dimensions is often unbalanced and that attention weights display a low-rank structure. Based on these observations, the authors show that the key cache's channel dimension contains redundancy that can be exploited to reduce costs.
They introduce a method called ThinK for KV cache pruning, which identifies the least significant channels by formulating the task as an optimization problem. This method uses a query-dependent criterion to assess the importance of each channel and selects the most critical ones in a greedy manner.
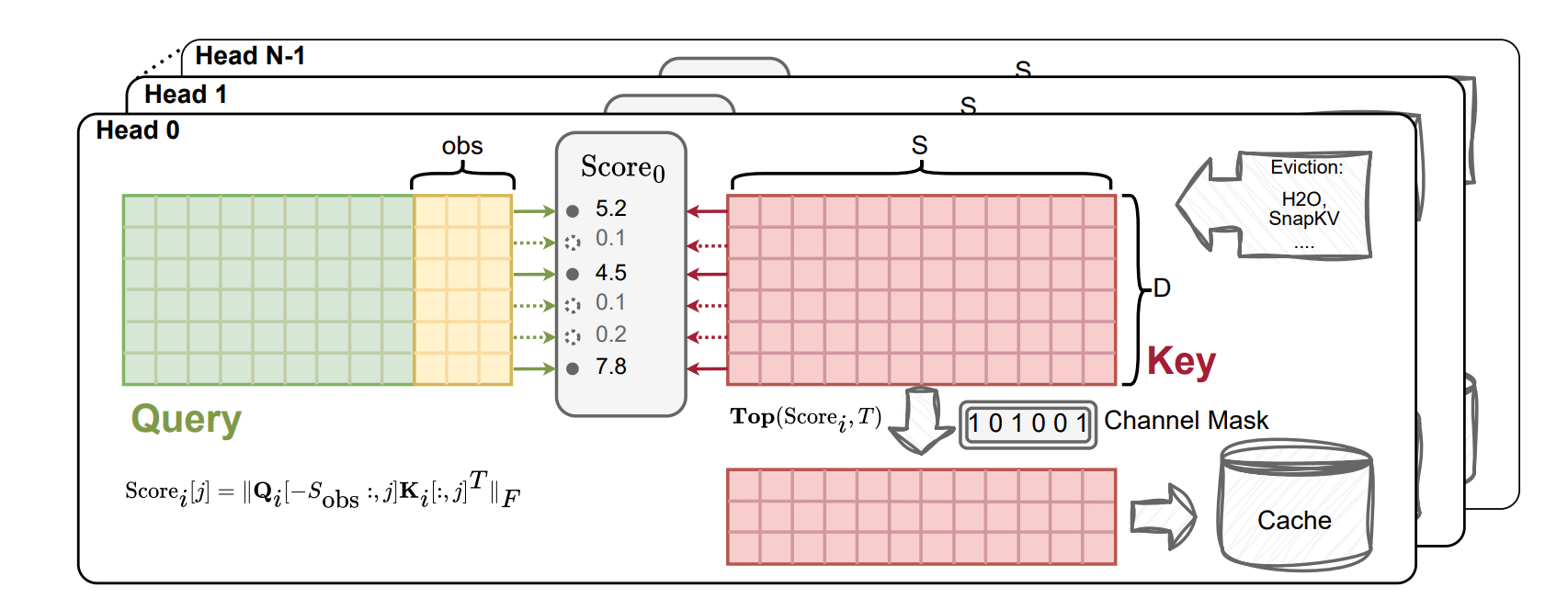
ThinK reduces KV cache memory costs by over 20% while maintaining the model’s accuracy.
Another way to reduce the size of the KV cache is quantization:

POA: Pre-training Once for Models of All Sizes
The paper introduces a new paradigm in self-supervised learning called POA (Pre-training Once for All), which is based on the teacher-student self-distillation framework. POA incorporates an elastic student branch that leverages parameter sharing to embed a series of sub-networks within the student model.
This approach is based on the observation that smaller models are essentially sub-networks of larger models in modern network architectures. During each pre-training step, a subset of parameters from the intact student model is randomly sampled to form an elastic student, which, along with the intact student, is trained to mimic the teacher network's output. The teacher network is continuously refined through an exponential moving average (EMA) of the student’s parameters, including those of the elastic student.
The elastic student enables effective pre-training on different subsets of parameters, facilitating the extraction of high-performance sub-networks for various downstream applications. This method also acts as a form of regularization, stabilizing the training process by ensuring output consistency between the teacher and various sub-networks. Additionally, the elastic student serves as an ensemble of sub-networks across different pre-training steps, enhancing representation learning.
The paper demonstrates that POA is the first self-supervised learning method capable of concurrently training multiple models of varying sizes.
They will release their code here:
GitHub: Qichuzyy/POA
Towards Achieving Human Parity on End-to-end Simultaneous Speech Translation via LLM Agent
In 2018, Microsoft claimed that its translation system outperformed humans (claiming human parity). 6 months later, another work showed that their evaluation was flawed. I was there when this paper was presented. There was a lot of tension in that conference room.
Since then, machine translation researchers have not dared to make that claim again…
ByteDance claims that their simultaneous speech translation system, a very difficult translation task, is close to humans’ performance. In my opinion, achieving human parity on this task is impossible with today’s technologies. Even if it was possible, we still lack a good evaluation framework to make sure the system is better than humans.
Nonetheless, while I don’t think we are “Towards Achieving Human Parity”, the authors present many interesting contributions in this paper.
They introduce an end-to-end approach called CLASI, a Cross-Lingual Agent for Simultaneous Interpretation. CLASI learns a robust read-write policy by imitating professional interpreters and following a data-driven policy learning process, which includes annotating real-world speech. For specialized terminology and uncommon phrases, they integrate external modules—a knowledge database and memory—using a Multi-Modal Retrieval Augmented Generation (MM-RAG) process to extract relevant knowledge and enhance in-context learning.

This is a framework quite complex, especially due to the use of external knowledge which is required to deal with the limits of LLMs.
To overcome data scarcity, they adopt a three-stage training methodology: pretraining on large datasets, continual training with synthesized speech translation data, and fine-tuning with human-annotated data to improve robustness and translation quality.
If you have any questions about one of these papers, write them in the comments. I will answer them.