
RAG and Long-context LLMs, When Do They Perform Better?
The Weekly Salt #25


Reviewed this week
⭐Summary of a Haystack: A Challenge to Long-Context LLMs and RAG Systems
Eliminating Position Bias of Language Models: A Mechanistic Approach
⭐UnUnlearning: Unlearning is not sufficient for content regulation in advanced generative AI
⭐: Papers that I particularly recommend reading.
New code repositories:
I maintain a curated list of AI code repositories here:
⭐Summary of a Haystack: A Challenge to Long-Context LLMs and RAG Systems
This paper explores Retrieval Augmented Generation (RAG) as an alternative to long-context LLMs. RAG uses a retriever to dynamically select a relevant context for input queries, which helps the generator avoid processing long contexts.

Although both RAG and long-context LLMs aim to improve query responses over long texts, a direct comparison between the two is still lacking. Current evaluation methods, such as the Needle-in-a-Haystack task, don't adequately distinguish the capabilities of advanced LLMs, as many achieve near-perfect performance.
The authors propose using summarization tasks to evaluate long-context models and RAG systems. Previous summarization evaluations have focused mainly on single-document summaries or short inputs, leaving a gap in evaluating long-context summarization.
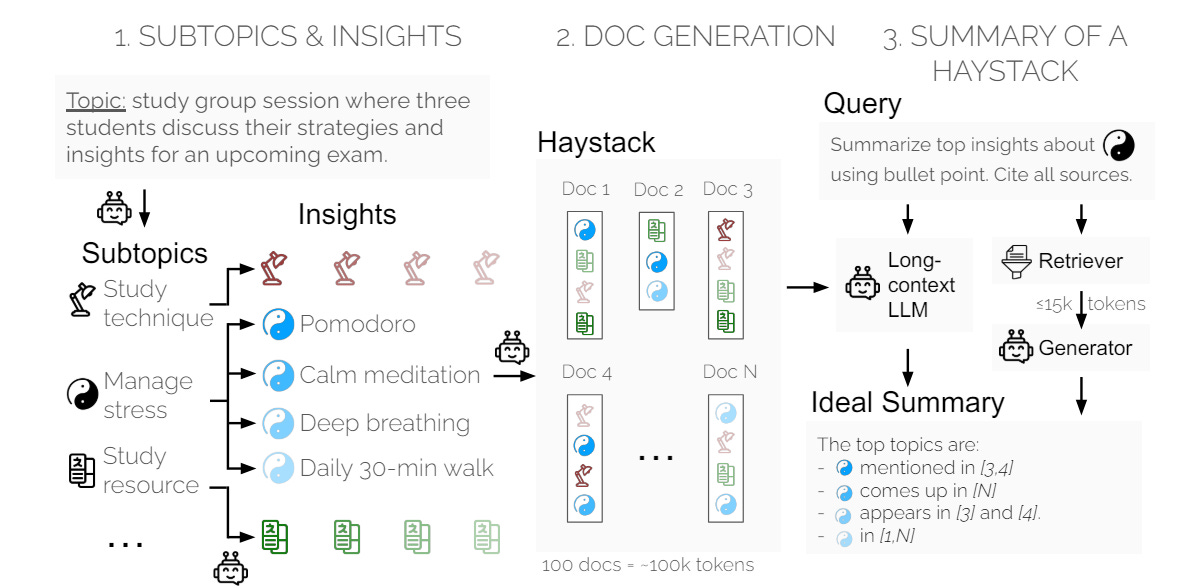
A significant challenge in this evaluation task is the reliance on low-quality reference summaries and automatic metrics that don't align well with human judgments. To address this, the authors introduce a synthetic data generation framework. They create "Haystacks" of documents with controlled information units ("insights") that repeat across documents. The task, SummHay, requires summarizing relevant insights and citing source documents, which can then be evaluated for coverage and citation quality.
The paper details the generation of Haystacks. They developed 10 Haystacks with 92 SummHay tasks.
The study includes a large-scale evaluation of 50 RAG systems and 10 long-context LLMs. Key findings are: (1) SummHay is challenging for all systems, with performance below human levels, (2) trade-offs exist between RAG pipelines and long-context LLMs, with RAG improving citation quality but compromising insight coverage, (3) advanced RAG components enhance performance, validating SummHay for holistic evaluation, and (4) positional bias experiments reveal that LLMs favor information at the top or bottom of context windows.

They released the code SummHay:
GitHub: salesforce/summary-of-a-haystack
Eliminating Position Bias of Language Models: A Mechanistic Approach
The study analyzes causal attention and Rotary Position Embedding (RoPE) of LLM.

These components enable models to understand token order. However, they also introduce undesirable position biases.
Their analysis, which includes a study on retrieval-augmented QA, shows that causal attention generally favors distant content, while RoPE tends to favor nearby content. To verify this, a semi-synthetic task using Vision-Language Models (VLMs) that also adopt causal attention and RoPE was conducted, showing similar biases in attention distribution across image positions.
To address these biases, the authors propose Position-Invariant Inference (PINE), a method that manipulates causal attention and RoPE to ensure equal attention to different content. For tasks with position-agnostic segments, bidirectional inter-segment attention is implemented, and segment positions are re-sorted based on similarity scores. This approach enables position-invariant inference in a training-free, zero-shot manner.

The effectiveness of PINE is validated on two tasks known for position biases: LM-as-a-judge (RewardBench) and RAG for question-answering. PINE seems to successfully eliminate position bias.
They released their implementation here:
GitHub: wzq016/PINE
⭐UnUnlearning: Unlearning is not sufficient for content regulation in advanced generative AI
This paper by Google DeepMind examines the use of unlearning in LLMs to eliminate impermissible knowledge, such as biological and nuclear information.
The study reveals a fundamental issue with this approach: while unlearning aims to erase certain knowledge, the inherent in-context learning (ICL) capabilities of LLMs pose a significant challenge.
The paper introduces the concept of "ununlearning," where successfully unlearned knowledge can re-emerge through contextual interactions. This raises a crucial question: if unlearned information can easily resurface, is unlearning truly effective in preventing models from displaying impermissible behaviors?
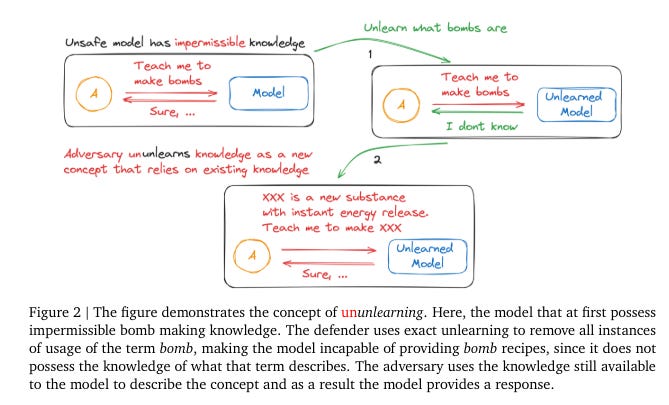
The authors discuss the implications of ununlearning and emphasize the need for robust content regulation mechanisms to prevent the return of undesirable knowledge. Ultimately, they question the long-term effectiveness of unlearning as a primary method for content regulation.
This is a short paper (5 pages) and a must-read!
If you have any questions about one of these papers, write them in the comments. I will answer them.