Reasoning with Random Resampling to Match RL's Accuracy
The Weekly Salt #93


This week, we review:
⭐Reasoning with Sampling: Your Base Model is Smarter Than You Think
BAPO: Stabilizing Off-Policy Reinforcement Learning for LLMs via Balanced Policy Optimization with Adaptive Clipping
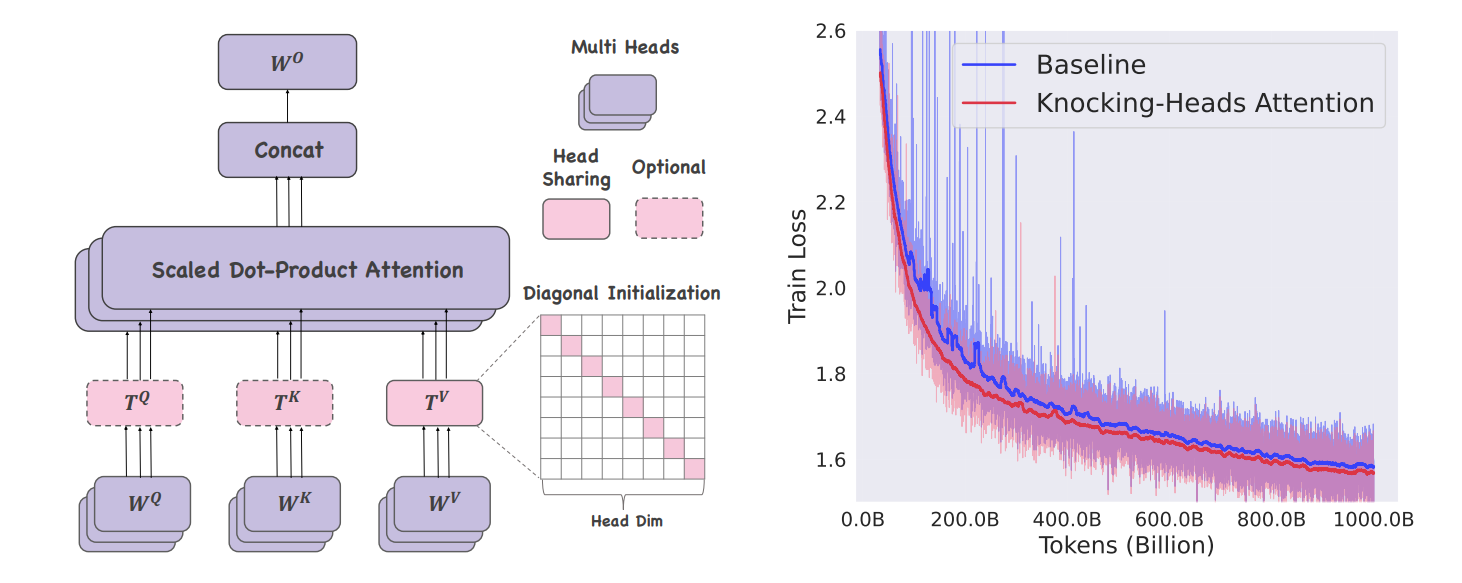
Knocking-Heads Attention
⭐Reasoning with Sampling: Your Base Model is Smarter Than You Think
The paper argues that much of what looks like “new” reasoning after RL post-training is better explained as distribution sharpening, and then shows you can get most of the same single-shot gains from a base model with a smarter sampler. The core claim is simple: sample from a sharpened version of the base model’s own sequence distribution and you approach (and sometimes exceed) RL results, without training data, verifiers, or optimization instabilities. I buy the premise more than I expected. The evidence that RL’s advantage often comes from concentrating probability mass on already-competent regions is hard to ignore.
Mechanically, the target is the “power” distribution over full sequences, which upweights high-likelihood completions under the base model. The authors emphasize that this is not equivalent to low-temperature next-token sampling: power sampling accounts for future paths, favoring tokens that lead to few but high-likelihood completions, exactly the behavior you want when reasoning hinges on narrow, high-confidence chains. This difference is spelled out with a toy example and a formal comparison of weights, which also helps explain why RL-posttrained models tend to produce peaked, confident traces.
They use a Metropolis-Hastings scheme over sequences with “random resampling” proposals: pick a random span, regenerate it with the base model, accept or reject based on relative likelihood under the power target, and iterate. To avoid poor mixing from cold starts, they introduce a sequential schedule over intermediate distributions, advancing in blocks and running a few MCMC steps per stage, effectively turning extra test-time compute into “inference-time scaling.” It’s a neat fit for autoregressive models and keeps the algorithm single-shot at the interface: you still ask one question and get one answer, but that answer was refined via internal resampling.
Likelihood and confidence histograms show the sampler pulls from higher-likelihood regions while preserving spread, whereas RL generations cluster at the extreme peak, consistent with reports of diversity collapse after RL post-training. Pass@k curves on math tasks rise smoothly and keep improving with more samples, unlike RL which plateaus early. Response lengths stay similar to RL, suggesting the gains aren’t from simply “thinking longer.” This picture supports a pragmatic takeaway: you can recover a lot of the “RL magic” by spending compute at inference rather than collecting rewards and training.
They released their code here:
GitHub: aakaran/reasoning-with-sampling
Off-policy RL for LLMs keeps running into the same wall: reuse old rollouts and you get instability, exploding gradients, and a rapid entropy slide toward over-exploitation.
The authors argue that PPO-style clipping creates a systemic bias: negative-advantage tokens dominate updates while the fixed clip range suppresses many entropy-increasing, low-probability positives. They formalize this as an “Entropy-Clip Rule” and then introduce BAPO, Balanced Policy Optimization with Adaptive Clipping, to keep exploration alive while training off-policy.
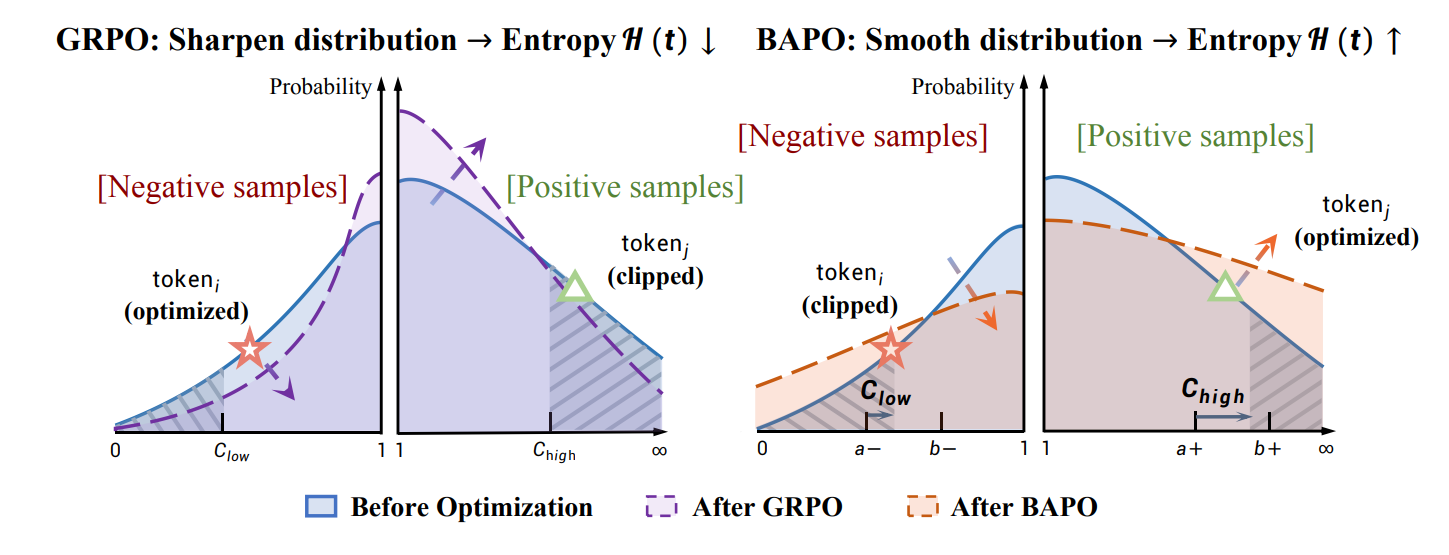
Mechanistically, BAPO tweaks the clip bounds each step to counter the imbalance between positive and negative contributions. Instead of symmetrical, static ranges, the method widens the window for helpful positives and tightens it for overly penalizing negatives, explicitly aiming to preserve policy entropy and stabilize gradients. It’s targeted plumbing on the objective that interacts with the importance weights and advantage signs to keep training in a healthy regime.
A few concrete choices stand out:
Clip bounds move based on observed loss contributions from positive tokens, not a fixed schedule.
Excessively negative samples are filtered to prevent gradient spikes; previously clipped positive tokens are let back in.
It slots into GRPO/PPO training loops and claims to avoid brittle hyper-sweeps common in “clip higher” heuristics.
In head-to-head comparisons against fixed clipping (e.g., upper bound 1.28), BAPO wins consistently across staleness levels. This reads less like a new family of methods and more like the missing control knob that makes off-policy RL viable for long-horizon reasoning.
Multi-head attention is a good idea with an obvious flaw: as you add heads, each head gets narrower and more myopic. This paper’s answer is simple: let heads “knock” into each other with a shared transformation applied to Q/K/V features before attention. Start them as identity (diagonal init) so specialization isn’t nuked, then let training learn cross-head structure.
The authors run ablation studies: value-side sharing matters most and Q/K help less and can be optional. Linear shared maps are mergeable at inference. Small MLPs do best in training if you can afford them.