Recursive Think-Answer Process to Stop "Thinking" Earlier
The Weekly Salt #110


This week, we review:
⭐Reinforcement-aware Knowledge Distillation for LLM Reasoning
Recursive Think-Answer Process for LLMs and VLMs
⭐Reinforcement-aware Knowledge Distillation for LLM Reasoning
Reinforcement-learning post-training has become the go-to way to squeeze better multi-step reasoning out of LLMs, but it leaves you with an awkward deployment problem: the models that learn best are often too expensive to run.
This paper tackles the practical version of that problem, distilling an RL-trained “reasoning” teacher into a smaller student while the student itself is being trained with RL, and argues that most knowledge-distillation recipes were built for supervised fine-tuning, not for an on-policy learning loop where the student’s rollout distribution keeps drifting.
The authors pin the failure mode on two things: teacher traces that stop matching what the student is currently doing, and a teacher-student divergence penalty that fights reward maximization unless you babysit the loss weights.
Their proposal, RL-aware distillation (RLAD): don’t bolt “imitate the teacher” onto RL as a separate objective. Make imitation part of the same trust-region machinery that already keeps policy updates sane.
The main mechanism, Trust Region Ratio Distillation (TRRD), replaces the usual teacher-student divergence regularizer with a clipped likelihood-ratio objective whose anchor is a mixture of the teacher and the student’s previous policy.
In plain terms, the teacher doesn’t get a constant vote but it gets influence only as the current advantage signal supports moving in that direction, and the update is bounded relative to the mixture anchor rather than blindly pulled toward teacher behavior everywhere. The paper also emphasizes that the teacher is used to score student rollouts (log-probabilities), not to generate additional trajectories, which matters for cost.
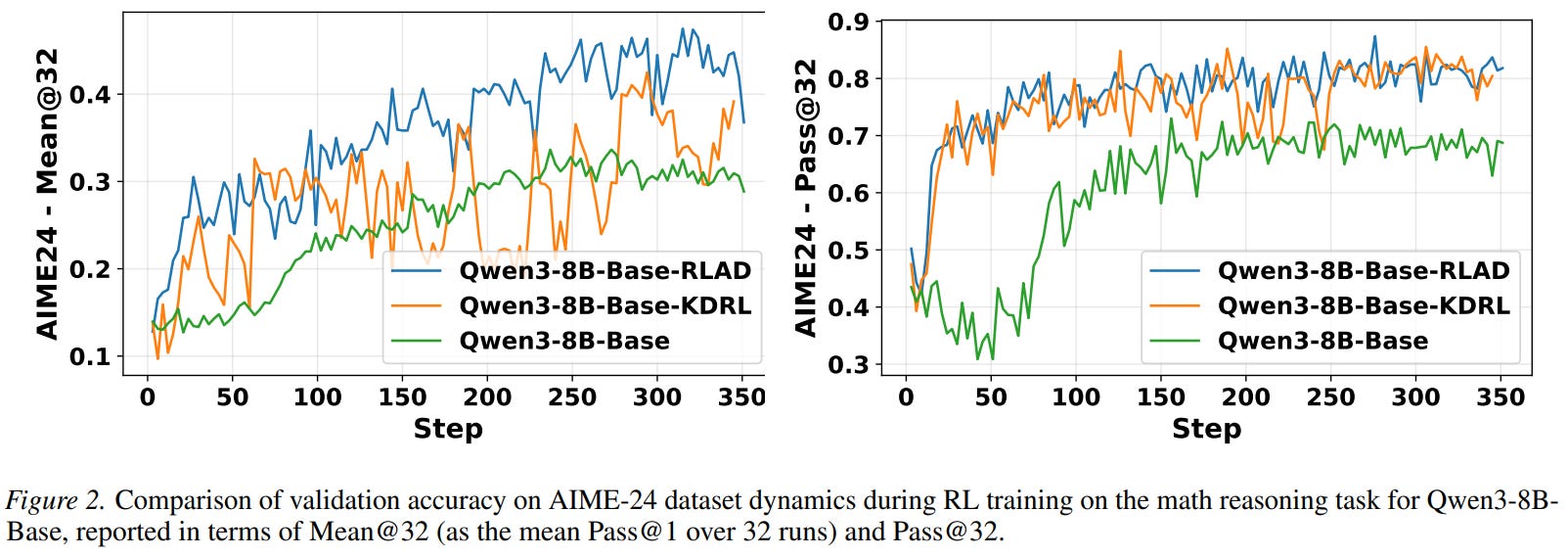
On long-context math, RLAD consistently beats plain GRPO and a KL-style distillation baseline: for a Qwen3-8B-Base student with a 32B teacher at 30K context, average score rises from 61.0 to 66.5, with notable jumps on the harder AIME benchmarks and steadier validation dynamics. Batch latency increases by roughly 12% versus GRPO in their setup, and RLAD and the KL-style baseline cost about the same when both must consult a large teacher.
Recursive Think-Answer Process for LLMs and VLMs
Think–Answer “reasoner” models have a familiar failure mode: they visibly doubt themselves mid-generation, yet still commit to a single-shot output that’s wrong.
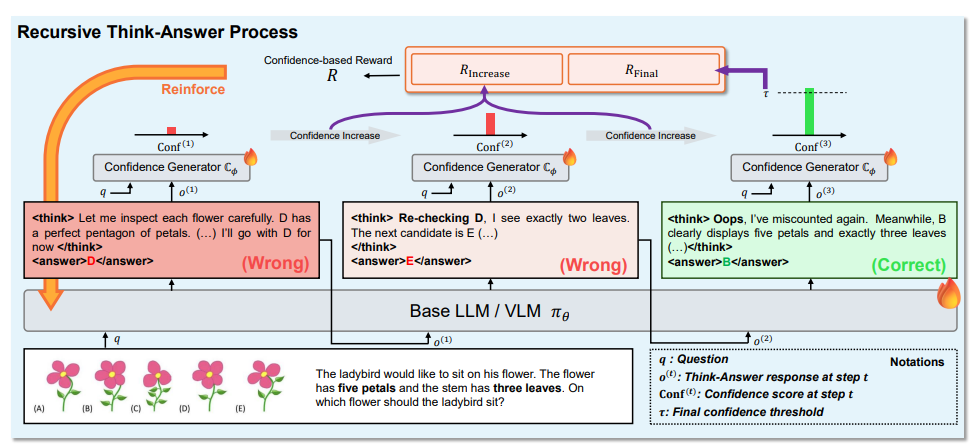
This paper’s stance is that sampling-and-reranking is an external patch, not a fix, because the model never learns a policy for “am I confident enough to stop?” The proposed Recursive Think–Answer Process (R-TAP) turns that question into something you can optimize directly: train the model to run multiple internal reasoning cycles when needed, and to terminate early when the trajectory looks reliable.
R-TAP’s trick is to introduce a separate confidence generator during training. It takes the question plus the model’s current Think–Answer pair and outputs a continuous confidence score.
It’s first trained as a correctness classifier using multiple sampled solutions per question. Then the base LLM/VLM is reinforcement-tuned on short recursive trajectories (multiple Think–Answer pairs, each conditioned on the previous ones) with two confidence-shaped incentives:
reward trajectories where confidence increases from one cycle to the next
reward stopping on a final cycle whose confidence clears a fixed threshold
Standard “format/correctness/length” rewards are kept alongside this, but confidence is the new steering wheel: it pushes the policy toward self-correction behavior without bolting on a test-time verifier.
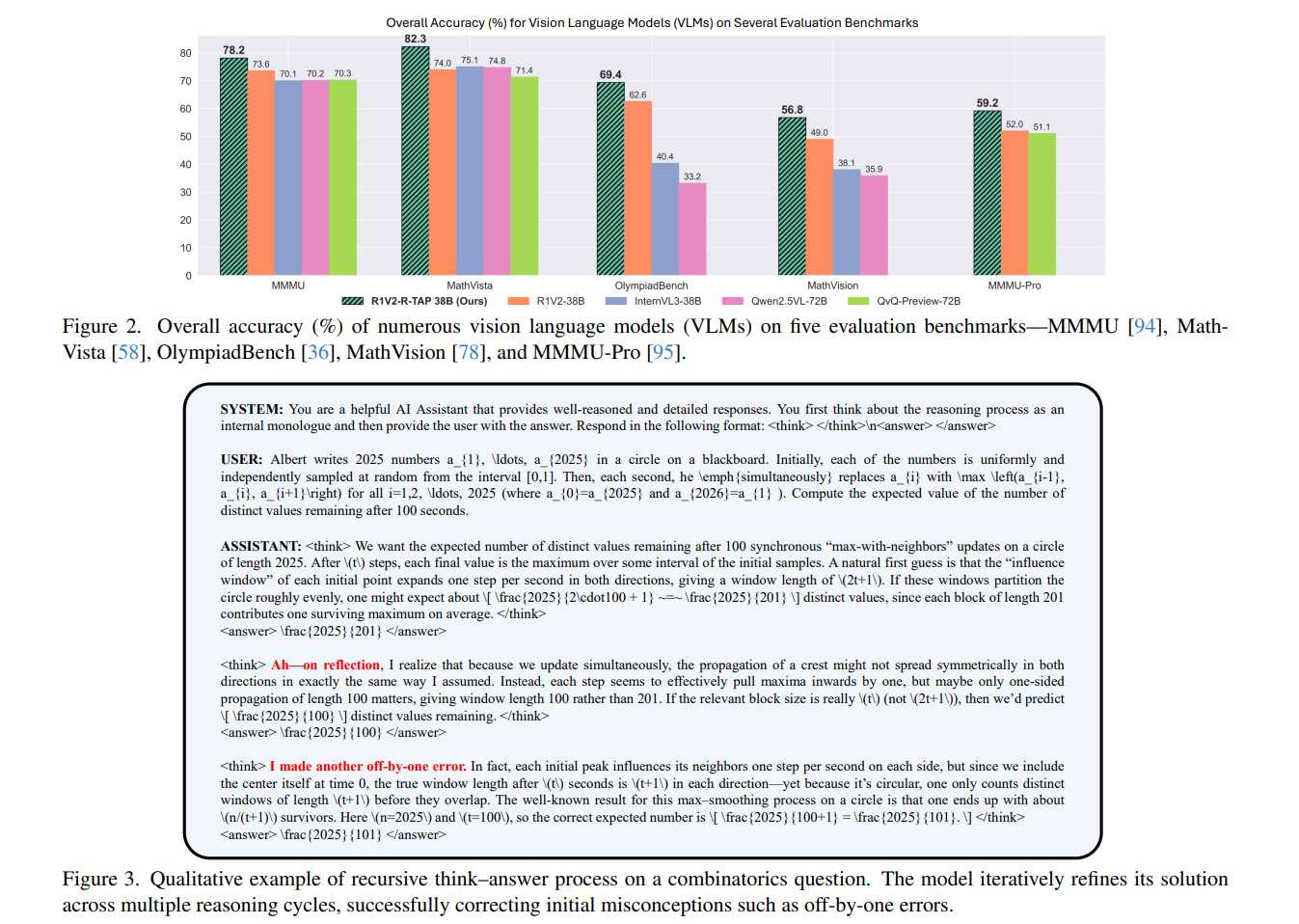
Empirically, the method is presented as broadly “drop-in” across both language-only and vision-language backbones. They show consistent accuracy gains on a mix of math, knowledge, and coding benchmarks for LLMs, and on multimodal reasoning suites for VLMs.
Ablations argue that you need both the “confidence increases” signal and the “confident final answer” signal to get the full lift. I also like that the paper tries to measure behavioral change, not just benchmark deltas: it tracks the drop in “Oops”-style self-correction tokens and reports that this correlates with reduced inference time and diminished reliance on majority-vote self-consistency, suggesting the policy is becoming more stable per sample, not merely luckier with more draws.