

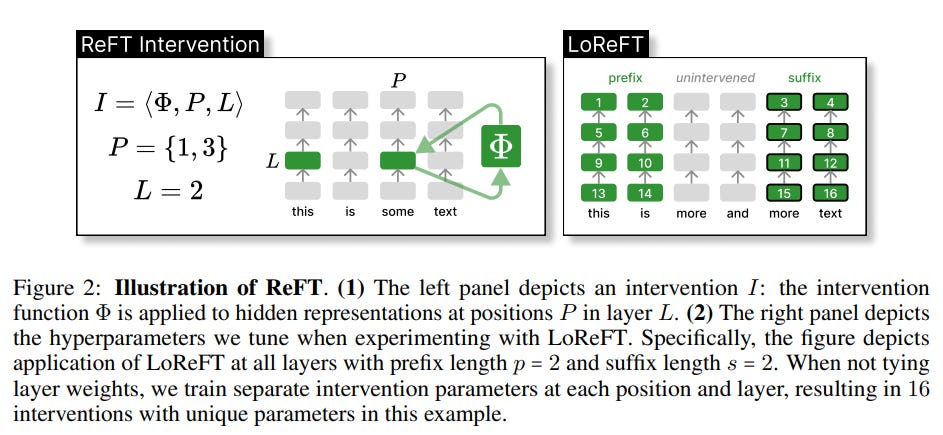
ReFT: Fine-tuning Representations Rather than Weights
ReFT: Fine-tuning Representations Rather than Weights
The Weekly Salt #12

Reviewed this week
⭐ReFT: Representation Finetuning for Language Models
AURORA-M: The First Open Source Multilingual Language Model Red-teamed according to the U.S. Executive Order
Long-context LLMs Struggle with Long In-context Learning
Training LLMs over Neurally Compressed Text
⭐: Papers that I particularly recommend reading.
New code repositories:
I maintain a curated list of AI code repositories here:
⭐ReFT: Representation Finetuning for Language Models
Parameter-efficient fine-tuning (PEFT) techniques typically focus on adapting the weights of a model. Yet, significant research in interpretability has revealed that model representations carry significant semantic information, hinting at the potential superiority of altering representations over updating weights.
From this observation, this study by Stanford University proposes Representation Finetuning (ReFT), a strategy that targets a small subset of model representations, aiming to direct the model's output towards achieving specific tasks during inference.
Unlike traditional weight modification techniques, ReFT applies targeted interventions to model representations, acting as a functional equivalent to weight-based PEFTs.
They also propose Low-rank Linear Subspace ReFT (LoReFT). LoReFT operates by adjusting hidden model representations within a linear subspace defined by a low-rank projection matrix.
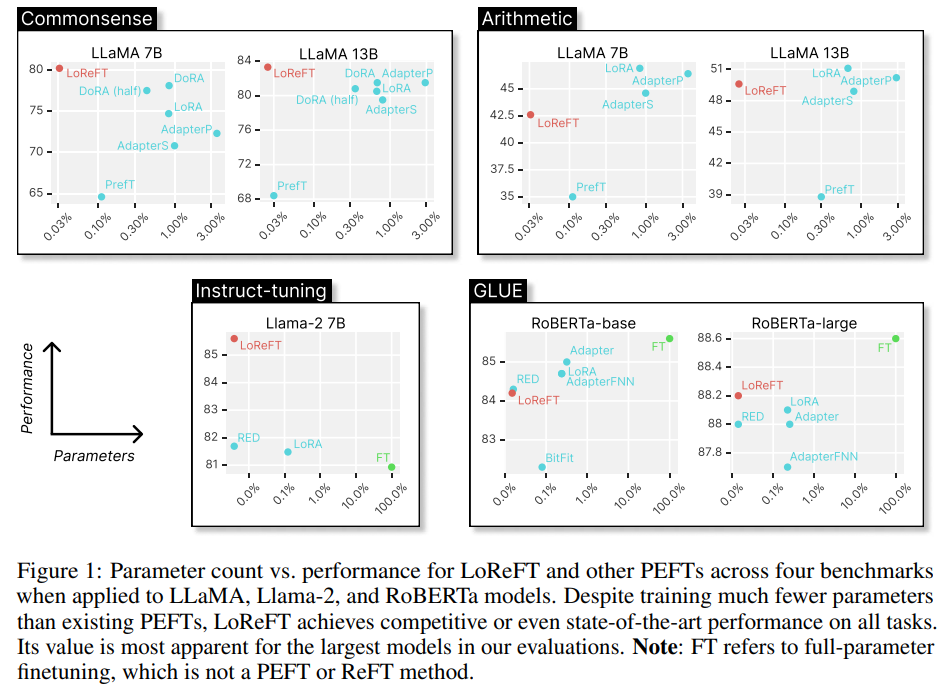
They experiment with LoReFT's on models from the LLaMA family and smaller language models, comparing its performance against traditional PEFT methods across a variety of standard benchmarks, including commonsense and arithmetic reasoning, instruction following, and natural language understanding tasks.
The results show that LoReFT significantly reduces the need for parameters (compared to LoRA) by up to 50 times while maintaining or surpassing benchmark performance.
They released their code here:
GitHub: stanfordnlp/pyreft
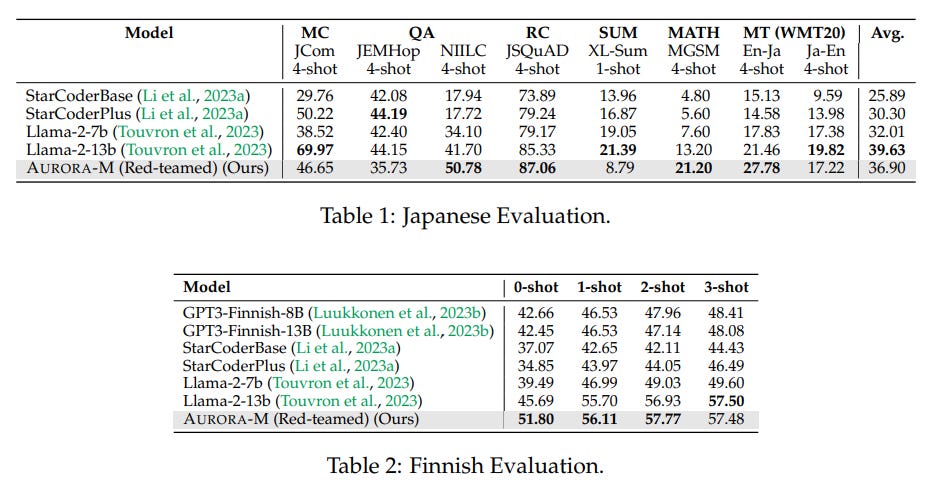
The study introduces AURORA-M, a new multilingual LLM with 15B parameters. AURORA-M has been trained on data in six diverse languages, including English, Finnish, Hindi, Japanese, Vietnamese, and programming code. The dataset used for training contained 435 billion tokens seen approximately 4 times (4 epochs).

It is the first multilingual LLM to adopt safety guidelines derived from the Biden-Harris Executive Order, ensuring compliance with high safety and security standards.
The evaluation of AURORA-M spans various tasks across multiple languages and domains. Its performance is compared with leading multilingual models. The safety assessments further validate its reliability and alignment with responsible AI development principles.
Base and instruct variants of Aurora-M are already on the Hugging Face Hub:
Hugging Face: Aurora-M models
Long-context LLMs Struggle with Long In-context Learning
In this study, the authors explore the application of in-context learning (ICL) to extreme-label classification tasks to test the capabilities of long-context large language models (LLMs).

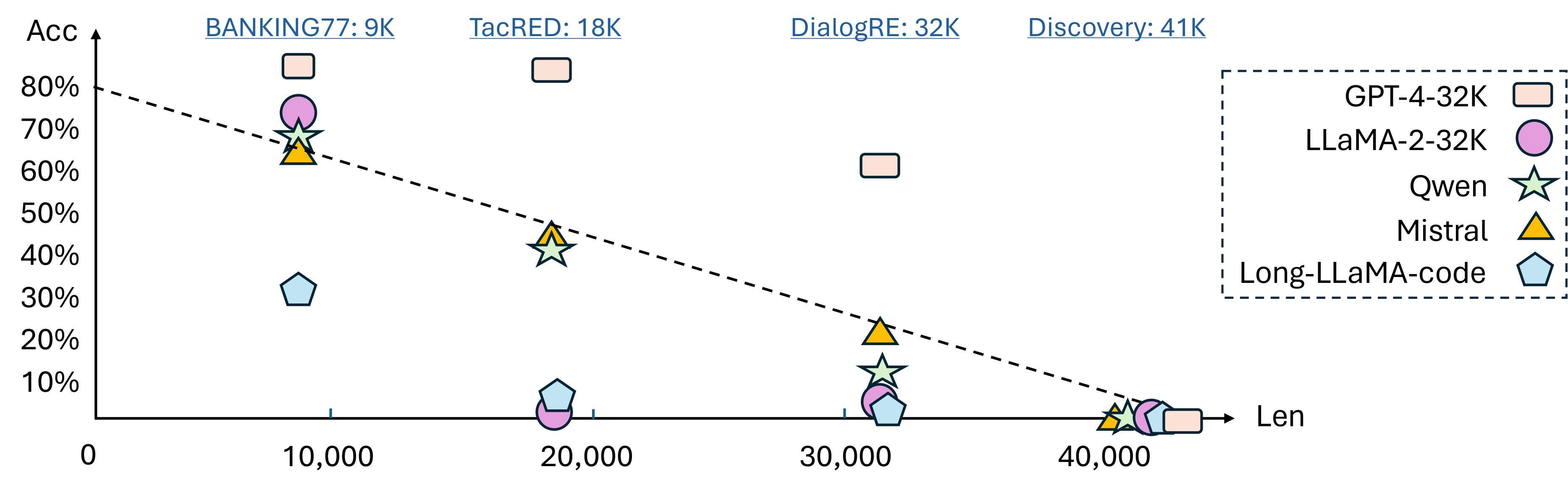
This approach challenges LLMs to process and understand extensive inputs to accurately predict from a vast label space, exemplified by tasks like Discovery, which features 174 classes and requires demonstrations exceeding 10,000 tokens for just a single instance per class.
To evaluate LLMs for such tasks, the researchers introduce LongICLBench, comprising six tasks varying in context length and label complexity.
Using this new benchmark, their analysis across 13 long-context LLMs indicates a general decline in performance with increased task complexity and demonstrates that while longer demonstrations can be beneficial up to a point, they eventually lead to performance deterioration or instability.
Notably, they also discover that the placement of instances within the prompt significantly affects some models' ability to learn in long contexts.
LongICLBench is available on GitHub:
GitHub: TIGER-AI-Lab/LongICLBench
Training LLMs over Neurally Compressed Text
The research paper proposes a new method for text compression inspired by Mixture of Experts (MoE) transformers, specifically focusing on Arithmetic Coding (AC).
The proposed strategy involves initially training a smaller language model (M1) on raw byte sequences, and then using this model to compress a pre-training corpus with AC. This compression results in a bitstream that, once tokenized, serves as the training data for a larger model (M2), designed to interpret the compressed text.
This methodology suggests a potential recursive application, where an even larger model (M3) could be trained on M2's output, and so forth.
However, the authors observe that text compressed through AC poses significant challenges for standard transformer-based LLMs, with models struggling to learn from the compressed data effectively. This difficulty persists even when simplifying M1 to a basic unigram model. To address this, the authors introduce a technique called Equal-Info Windows, which divides text into segments compressed independently, ensuring each segment contains a similar amount of information. This method facilitates more effective learning from AC-compressed text by providing a consistent mapping between the number of tokens and the amount of compressed text.
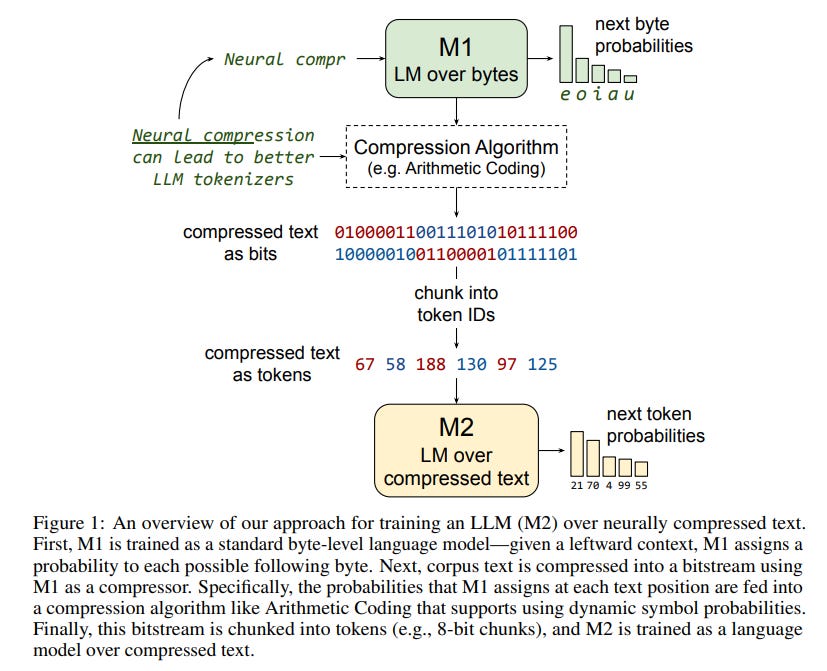
Despite some success with Equal-Info Windows enabling the learning of neural-compressed text, the findings indicate that models trained this way still lag behind those trained with standard subword tokenizers, particularly in terms of perplexity.
If you have any questions about one of these papers, write them in the comments. I will answer them.