


Rethinking LLM Reliability: Calibration, Compression, and the Hidden Costs of Inference-Time Scaling
The Weekly Salt #79


This week, we review:
⭐Does More Inference-Time Compute Really Help Robustness?
The Geometry of LLM Quantization: GPTQ as Babai's Nearest Plane Algorithm
Beyond Binary Rewards: Training LMs to Reason About Their Uncertainty
⭐Does More Inference-Time Compute Really Help Robustness?
This work critically examines the effects of inference-time scaling, increasing computational budget during inference, on the robustness of LLMs, particularly in reasoning tasks. While prior studies (mostly on proprietary models) have suggested that more computation at inference time boosts both accuracy and robustness, this paper gives a more nuanced view by systematically studying open-source models.
Using a practical method called budget forcing to lengthen reasoning chains, the authors replicate earlier robustness gains, especially against prompt injection and prompt extraction attacks. This shows that open models can benefit from inference-time scaling in similar ways to proprietary ones.
However, the paper identifies a key limitation in existing robustness claims: they often assume that intermediate reasoning steps remain hidden from adversaries. When this assumption is relaxed, i.e., when reasoning traces are exposed, the authors observe an inverse scaling law: longer reasoning chains consistently reduce robustness across various adversarial settings.
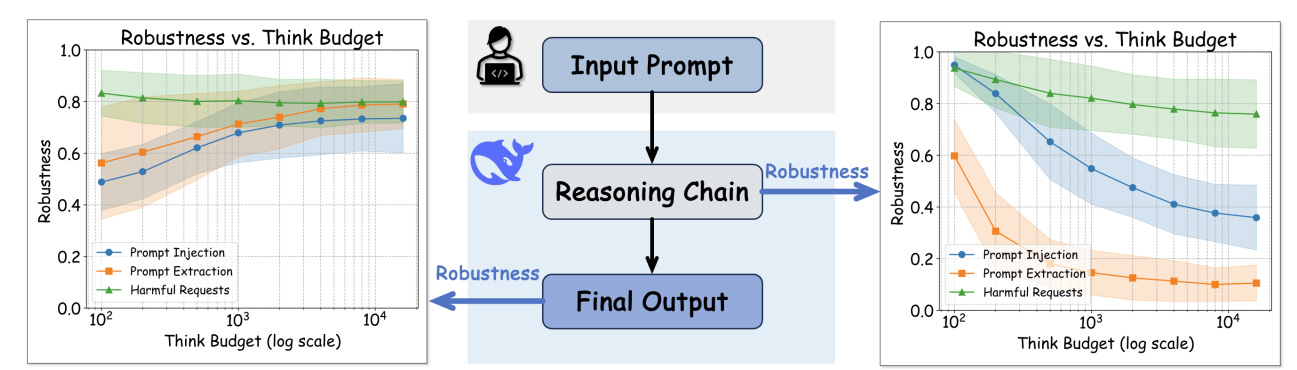
Even when reasoning steps are hidden, the paper demonstrates that vulnerabilities may persist. Tool-augmented reasoning and indirect reconstruction via carefully designed prompts can still expose models to attacks. These findings complicate the simplistic narrative that “more inference equals more robustness” and point to a deeper trade-off between reasoning depth and security.
The work ultimately highlights that inference-time scaling can both help and harm, depending on model exposure and adversarial context.
The Geometry of LLM Quantization: GPTQ as Babai's Nearest Plane Algorithm
This work revisits GPTQ, a widely used post-training quantization method for LLMs, and provides a theoretical foundation for its empirical success. Despite GPTQ’s effectiveness in pushing quantization to 4-bit precision with minimal performance degradation, its greedy, coordinate-wise procedure lacked a principled explanation until now.
The authors show that the core problem GPTQ solves, minimizing L2 output error during linear-layer quantization, is equivalent to a well-studied lattice problem: the Closest Vector Problem (CVP). They further demonstrate that GPTQ, when executed in reverse order, is mathematically equivalent to Babai’s nearest plane algorithm applied to the Hessian-derived basis, with and without weight clipping.

This insight yields several consequences. GPTQ's update step gains a geometric interpretation rooted in lattice theory, and under no clipping, its error can now be formally bounded by Babai’s guarantee. The analysis also informs improved heuristics for choosing quantization order and opens the door to leveraging a rich body of lattice-based methods, such as basis reduction, to enhance quantization.
Beyond Binary Rewards: Training LMs to Reason About Their Uncertainty
Recent work highlights a key limitation in how current reasoning-based language models are trained using reinforcement learning with correctness-based rewards (RLVR). While this approach improves task accuracy, it leads to poor calibration; models often become overconfident, even when wrong. This is particularly concerning in safety-critical settings where uncertainty must be communicated.
To address this, the authors propose RLCR (reinforcement learning with calibration rewards), which augments the standard correctness reward with a calibration term derived from proper scoring rules. Models trained with RLCR learn not only to produce accurate answers but also to estimate and verbalize their confidence appropriately.
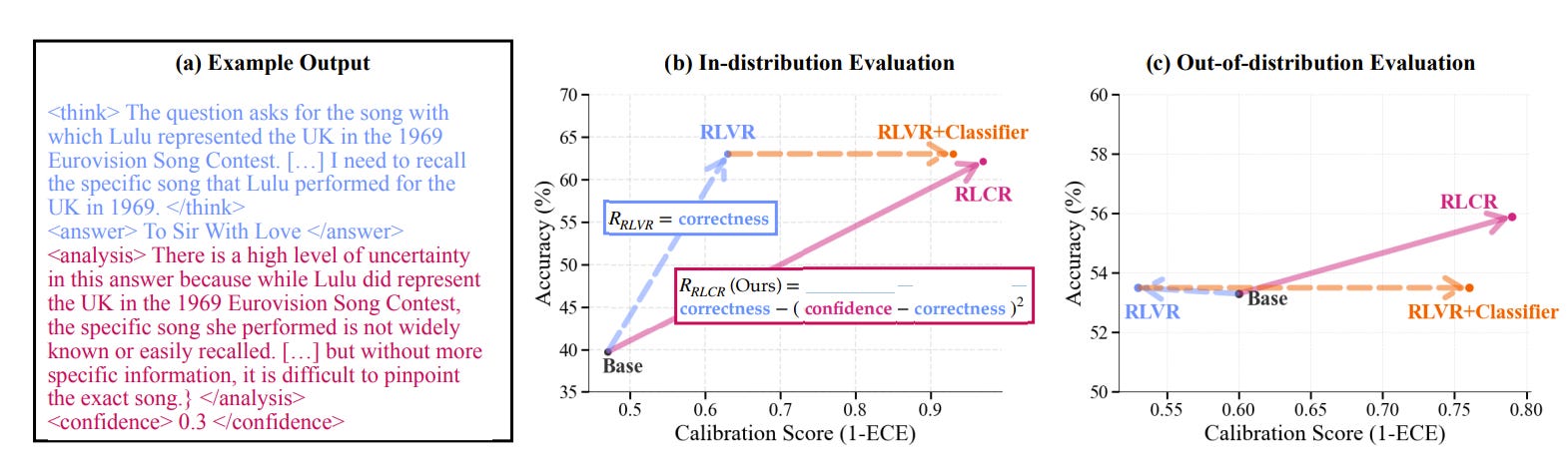
Empirical results show that RLCR matches RLVR in accuracy while significantly improving calibration across both in-domain and out-of-domain tasks. RLCR-trained models exhibit more coherent confidence estimates across reasoning chains and generalize better to new tasks. This suggests that integrating calibration into the RL training objective is beneficial for robustness and reliability in LLMs.