
"Reverse Thinking" for Better LLM Reasoning
The Weekly Salt #47


Reviewed this week:
⭐Reverse Thinking Makes LLMs Stronger Reasoners
⭐Evaluating Language Models as Synthetic Data Generators
Florence-VL: Enhancing Vision-Language Models with Generative Vision Encoder and Depth-Breadth Fusion
⭐: Papers that I particularly recommend reading.
New code repositories (list of all repositories):
Reverse Thinking Makes LLMs Stronger Reasoners
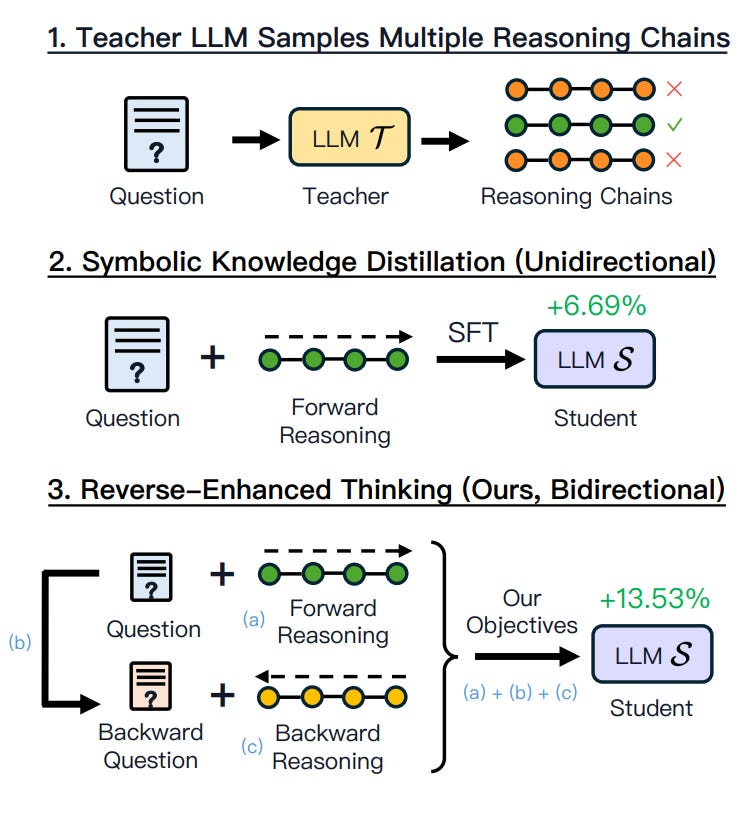
To improve performance in solving problems, a two-way reasoning approach—combining forward and backward thinking—has proven effective. Forward reasoning works step-by-step from the question to the answer, while backward reasoning starts with the answer and traces back to the question. This dual approach helps verify solutions and catch errors. For example, in a math problem like "Emma has two apples and Jack has three; how many do they have together?" forward reasoning calculates 2+3=5. Backward reasoning confirms the solution by starting with 5 and ensuring Emma and Jack's counts match the question. If forward reasoning made an error, backward reasoning would highlight the mismatch. Note: This is an example taken from the paper.
This two-way reasoning has been beneficial in structured domains like math, where relationships between steps are clear and tasks can easily be modified by changing variables. The authors wondered if backward reasoning could also help in broader, less structured areas and whether it could be trained directly into a model rather than just being used for verification during testing.
To explore this, they introduced REVTHINK, a training framework designed to teach models how to reason both forward and backward. REVTHINK uses data augmentation to create additional training examples, generated by a larger "teacher" model. For each question, the teacher model produces:
Forward reasoning (from the question to the answer),
A backward question (from the answer back to the question),
Backward reasoning (from the backward question to the answer).
These generated examples are carefully validated before being used to train a smaller "student" model. During training, the student learns to:
Reason forward (solve the question),
Create a backward question,
Reason backward (solve the backward question).
This process embeds both reasoning styles into the student model, improving its problem-solving abilities while keeping test-time performance as fast and efficient as standard approaches.
⭐Evaluating Language Models as Synthetic Data Generators
Synthetic data has become an increasingly important tool for improving LLMs as it is a scalable and efficient alternative to manual data labeling. While human-annotated data remains valuable, synthetic data generation allows models to improve their performance across a wide range of tasks without relying solely on manual processes.
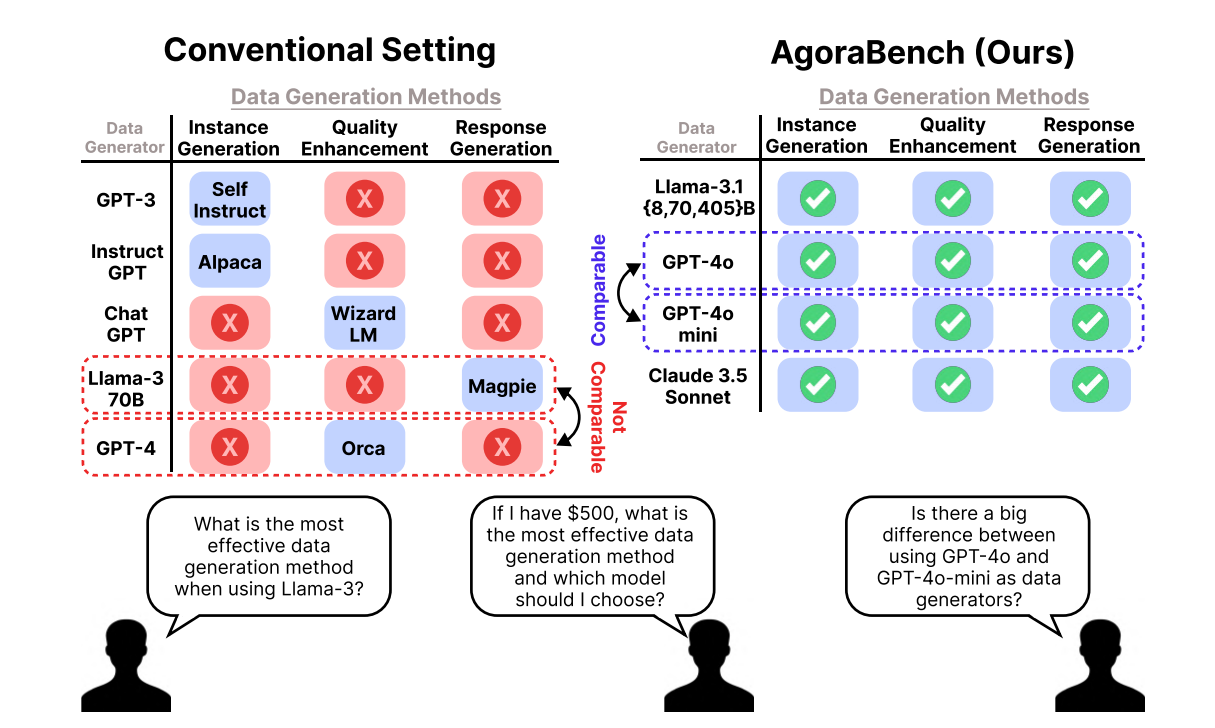
Comparing different LLMs’ abilities to generate synthetic data, however, has proven challenging. Studies often use inconsistent setups, varying in how much data they generate, which models they train, and how they evaluate performance. These differences make it difficult to determine which LLMs are truly better at synthetic data generation.
To address this, the authors developed AGORABENCH, a benchmark designed to fairly evaluate LLMs as data generators. It tests models across three domains—math, instruction-following, and coding—using three types of data generation: creating new examples, refining existing ones, and enhancing data quality. AGORABENCH keeps everything else constant, including prompts, datasets, and data amounts, so that only the LLMs’ data generation abilities are being tested. The quality of the generated data is assessed using the Performance Gap Recovered (PGR) metric, which measures how much a model improves after training on the synthetic data compared to its original version.
The authors also found that certain factors influence performance. In budget-limited scenarios, generating larger amounts of data with a less powerful model was often more effective than generating smaller amounts with a more advanced model. For instance, GPT-4o-mini, a smaller and cheaper model, outperformed GPT-4o in some settings when producing a larger dataset.
The visual encoders used in vision-language models (VLMs) like CLIP and SigLIP typically offer high-level semantic representations of images that capture overall scene context but often overlook finer pixel-level or region-specific details crucial for specific tasks. This has led to challenges in adapting VLMs to diverse applications requiring nuanced visual understanding.
To address these gaps, Microsoft introduced Florence-VL, built on top of Florence-2. Florence-2 is one of my favorite VLMs as it is extremely small (cheap to run) but very capable in most vision tasks that don’t require extensive language generation.

Unlike Florence-2, Florence-VL focuses on extracting and integrating multiple levels of visual information, referred to as depth, and accommodating various task-specific perceptual needs, known as breadth.
It has a Depth-Breadth Fusion (DBFusion) strategy, which combines features from different layers of the vision model. By fusing lower-level and higher-level features, Florence-VL is better at modeling images. The model uses a straightforward channel concatenation approach to align these features effectively with the pre-trained LLM.
The code and model are available here:
GitHub: JiuhaiChen/Florence-VL