


I’ve launched the Summer Sale for The Kaitchup: get 30% off forever on the yearly subscription.
The same deal applies to The Salt, which focuses more on scientific papers and research insights.
Both offers are valid until June 30.
Looks like the stream of interesting papers is starting to slow down. No surprise, summer is here!
This week, we review:
⭐ RLPR: Extrapolating RLVR to General Domains without Verifiers
All is Not Lost: LLM Recovery without Checkpoints
⭐: Papers that I particularly recommend reading.
New code repositories (list of all repositories):
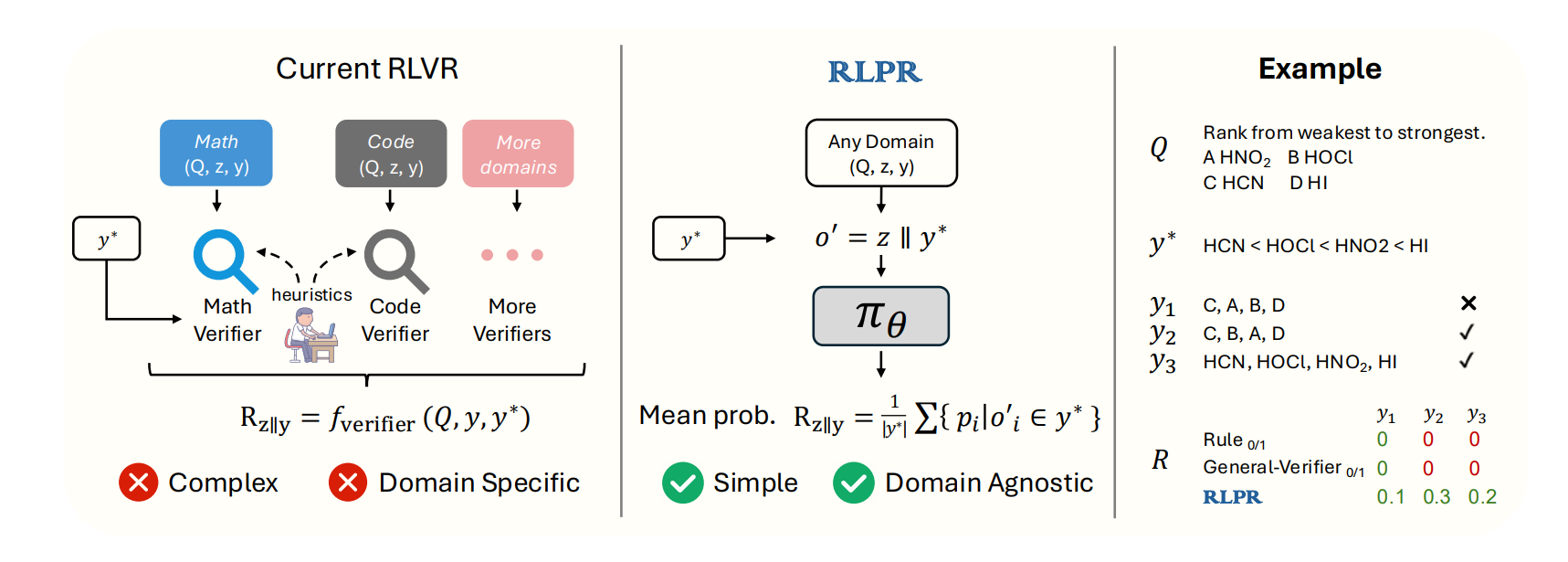
⭐ RLPR: Extrapolating RLVR to General Domains without Verifiers
This paper tackles a key limitation in large-scale reinforcement learning with verifiable rewards (RLVR). It’s mostly stuck in math and code tasks because it relies heavily on domain-specific verifiers, typically hand-crafted rules or specialized models, to give rewards. These verifiers don’t generalize well to broader tasks with free-form answers (like open-domain reasoning), where defining correctness is fuzzier and much harder to automate.
To address that, the authors propose RLPR (Reinforcement Learning with Reference Probability Reward). Instead of needing an external verifier, RLPR uses the model’s own probability of generating a reference answer as a reward signal. The idea is simple: if the model assigns a higher likelihood to the correct answer, it probably understands the reasoning path leading there. This self-rewarding setup avoids manual reward engineering and scales better across domains.
They make two main technical contributions:
Probability-based Reward (PR): Instead of naive log-likelihood, they average token-level probabilities of the reference answer and apply a simple debiasing trick by comparing with outputs that don’t include reasoning.
Adaptive curriculum filtering: During training, they filter out prompts with very low reward variance (i.e., too easy or too hard) using a dynamic threshold. This helps maintain stability and makes training smoother.
Experiments across 7 benchmarks and 3 model families (Qwen, Llama, Gemma) show that RLPR boosts general reasoning, outperforms other verifier-free baselines, and even beats methods that rely on specialized verifier LLMs.
They released their code here:
GitHub: openbmb/RLPR
All is Not Lost: LLM Recovery without Checkpoints
This work addresses the challenge of training LLMs on unreliable hardware like spot (interruptible) instances, where stage-level failures in pipeline-parallel setups are more likely.
Solutions like checkpointing or redundant computation help recover from failures but introduce high overheads, either by frequently saving large model states to storage or duplicating compute across nodes.
The authors propose CheckFree, a lightweight recovery method that doesn’t require checkpointing or redundant execution. When a stage fails, its replacement is initialized by averaging the weights of its neighboring stages. This leverages the observation that adjacent layers in transformer models tend to learn similar functions, making such interpolation a viable warm-start strategy.
However, this doesn't work for the first and last stages (no neighbors on one side). To handle these, the authors introduce CheckFree+, which uses out-of-order pipeline parallelism to train the second and second-to-last stages to mimic the behavior of the edges. This allows the system to reconstruct even those critical boundary stages if they fail.

Empirical results show that CheckFree significantly reduces recovery overhead and improves training efficiency, cutting down training time by over 12% in low failure rate settings, while maintaining final model performance.
The code is here:
GitHub: gensyn-ai/CheckFree